

Принципи побудови тестів
Щоб стати широко використовуваними, психологічні тести повинні відповідати трьом критеріям: вони повинні бути стандартизованими, надійними і валідними. Тести Стенфорда-Біне і Векслера відповідають цим вимогам.
Стандартизація
Знання того, на скільки питань тесту для визначення розумових здібностей ви відповіли правильно, майже ні про що не говорить. Для оцінки ваших показників потрібна основа для їх порівняння з показниками інших людей. Щоб добитися виразних порівнянь, творці тестів спочатку пропонують даний тест репрезентативній вибірці людей. Коли інші люди пройдуть тест, ми можемо порівняти його результати зі стандартами, визначеними цією групою. Процес визначення значущих оцінок, що співвідносяться із заздалегідь протестованою групою, називається стандартизацією.
Пригадаємо, що Терман з колегами виявив, що питання, розроблені для парижан, не забезпечували задовільного стандарту для оцінки американців. Тому вони переглянули тест і стандартизували його нову версію шляхом тестування 2300 корінних білих американців з різними соціально-економічними рівнями. На жаль, потім, спираючись на цей стандарт, вони почали оцінювати кольорових американців і представників іммігрантських груп (Van Leeuweri, 1982).
Приклад завдань з тесту векслера для дорослих (wais)
(Thorndike & Hagen, 1977)

Нормальна крива
Результати тесту здібностей утворюють нормальну криву дзвоноподібної форми. Середній показник для тесту Векслера — 100 балів.
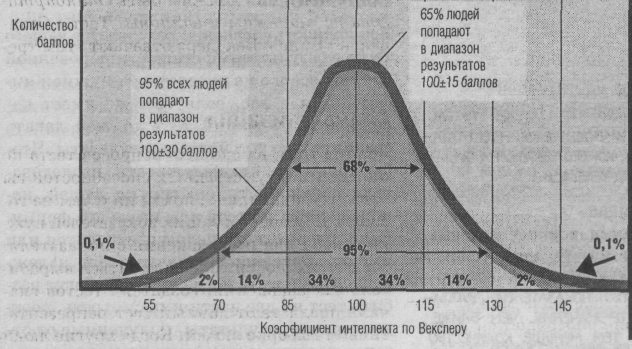
Результати стандартизованого тесту, як правило, є нормальним розподілом, дзвоноподібною схемою оцінок у вигляді нормальної кривої (мал. 11.4). Незалежно від того, що ми вимірюємо, — ріст, вагу чи розумові здібності людей, більшість оцінок має тенденцію накопичуватися біля середнього показника. У тестах на розумові здібності ми рахуємо цю середню оцінку рівною 100. У міру того як ми віддаляємося від середнього показника (до будь-якої з крайніх точок), знаходимо там все менше і менше людей. У кожній віковій групі тести Стенфорда-Біне і Векслера дають кожній людині оцінку відповідно до того, наскільки його показники відхиляються у більшу чи меншу сторону від середнього. Як показано на малюнку, найвищий показник, на який проте випадає 2% всіх оцінок, відповідає оцінці розумових здібностей, рівній 130. Низька оцінка, представлена менш ніж 98 відсотками всіх оцінок, відповідає оцінці розумових здібностей, рівній 70.
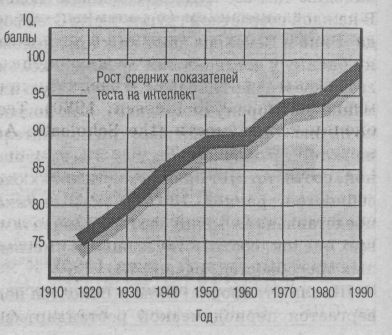
Шкала Стенфорда-Біне і Векслера піддається періодичній рестандартізації, щоб зберегти середню оцінку приблизно рівною 100. Якщо ви недавно здавали перероблений тест WAIS, ваші показники порівнювалися із стандартизованим набором людей, протестованих між 1976 і 1980 роками, а не з первинним набором людей Девіда Векслера від 1930 року. Як ви вважаєте, коли ми порівнюємо показники самого останнього стандартизованого відбору з показниками відбору тестованих 1930-х років, ми бачимо підйом чи спад показників тесту? Дивно, але навіть враховуючи, що оцінки здібностей під час вступу до коледжу падали між 1960-ми і 1970-ми роками, показники тестів на визначення розумових здібностей поліпшувалися. Цей всесвітній феномен називається ефектом Флінна — на честь новозеландського дослідника Джеймса Флінна (1987, 1996), який вперше прорахував його величину. Як показує мал. 11.5, якщо ми визначаємо, що останні середні показники рівні 100, то на тому ж графіку середні показники 75-річної давності рівні 76. Подібне зростання показників спостерігалося в 20 країнах. Прогрес виглядає реальним і сьогодні широко приймається як важливе явище, оскільки припускає, що або існує якась проблема з самими тестами, або інтелект розвивається. Крім того, він протистоїть переконанню багатьох сучасних послідовників Гальтона у тому, що вища народжуваність серед тих, хто має нижчий IQ, приводить до зниження людського інтелекту.
Стандартизація
Виділення значущих показників шляхом порівняння їх з наявними результатами тестування контрольної групичи групи стандартизації.
Нормальна крива
Симетрична крива у формі дзвону, що демонструє розподіл психологічних і фізіологічних показників, більшість показників групується навколо середнього значення, чим ближче до країв кривої, тим менше показників.
Яка інтригуюча загадка: здібності або знижуються, як можна припустити з факту зниження оцінок в тестах на визначення придатності під час вступу до коледжу, або ростуть, як підказують дані тесту на визначення розумових здібностей? Зниження оцінок на придатність абітурієнтів частково пояснюється великою академічною різноманітністю студентів, які почали здавати цей тест в 1960-ті роки. Тест WAIS завжди був стандартизований відповідно до різноманітнішої і представницької групи людей. Такі люди (люди в цілому) стали більш грамотними і освіченими з 30-х років. Ці факти допомагають зрозуміти, чому показники складніших тестів на придатність знижувалися в той час, як росли показники основних умінь, які визначалися тестом WAIS. Деякі вчені, проте, припускають, що даний прогрес може бути результатом покращеного харчування, досвіду в проходженні тестів або якогось невідомого чинника. Таємничим чином прогрес виявляється вищим у невербальних тестах, на які покращена освіта повинна впливати найменше. (Можливо, заняття з конструкторами, головоломками і відеоіграми, такими як "Тетріс", допомогли, але зростання почалося ще до того, як всі ці ігри стали популярними.) Флінн вважає дивним припущення, що його покоління набагато розумніше за попередні, проте дані аналізу говорять самі за себе. "Я збитий з пантелику", — говорить він.
Надійність
Можливість порівняння результатів вашого тесту з результатами стандартизованої групи все ж таки не надасть потрібної інформації про вас, якщо тест не має надійності. Хороший тест повинен давати порівняно стійкі результати. Щоб перевірити його надійність, дослідники неодноразово тестують .людей, використовуючи той же тест або іншу його форму. Якщо дві оцінки в цілому співвідносяться або мають кореляцію, значить, тест надійний. Крім того, дослідники можуть розбити тест на дві частини і подивитися, чи співвідносяться результати, одержані від відповідей на парні і непарні питання.
Чим більша кореляція між самим тестом та його повторами і між розділеним на половини результатом, тим вища надійність даного тесту. Тести, які ми до цього розглядали, — тест Стенфорда-Біне і тест WAIS, — мають надійність, яка дорівнює приблизно +0,9. Це дуже високий показник. У повторних тестах оцінки людей дуже близькі до результатів першого тесту.
Валідність
Висока надійність не забезпечує валідності тесту — ступеня вимірюваності того, що повинен вимірювати, або передбачення того, що повинен передбачати. Якщо ви використовуєте сантиметр, який сів, для вимірювання росту людей, ваші дані матимуть високу надійність (послідовність), але низьку обґрунтованість. Як же у такому разі визначити, чи є тест обґрунтованим? Для деяких тестів достатньо того, що вони мають змістову валідність. Це означає, що тест викликає доречну поведінку. Дорожній тест на отримання посвідчення водія має змістову валідність, тому що в ньому представлені рутинні завдання, які необхідно вирішити водію. Курсові іспити мають змістовну валідність, якщо оцінюється засвоєння репрезентативного відбору курсового матеріалу.
Інші тести ми оцінюємо, виходячи з того, наскільки вони відповідають певному критерію — незалежній мірі того, що даний тест має намір оцінити. Для деяких тестів критерієм є майбутній успіх. Наприклад, тести на визначення здібностей повинні мати прогностичну валідність (яка також називається критерійно зумовленою валідністю). Це значить, що вони повинні передбачати майбутні досягнення.
Чи можна вважати загальні тести на визначення здібностей настільки ж передбачаючими, наскільки вони надійні? Оскільки критики люблять заперечувати, то ясно, що відповідь буде негативною. Передбачаюча сила тестів на визначення здібностей достатньоя висока в молодших класах, але пізніше вона слабшає. Результати тестів на визначення академічних здібностей є хорошим прогнозом (в розумних межах) можливих досягнень в початковій школі, де кореляція між оцінкою розумових здібностей і оцінками приблизно рівна +0,60 (Jensen, 1980). Тест оцінки успішності (the Scholastic Assessment Test — SAT), використовуваний в Сполучених Штатах як вступний іспит, менш вдалий в прогнозі оцінок першокурсників. В даному випадку кореляція складає менш +0,50 (Willingham & others,1990). До моменту проходження перевірки (GRE — Graduate Record Examination) (оцінний тест, подібний SAT, але призначений для тих, хто вступає до аспірантури) аспіранта кореляція з оцінками успішності в аспірантурі ще скромніша — +0,30 (GRE, 1990).
Надійність
Ступінь стійкості показників тесту. Може бути оцінена по стійкості результатів у двох частинах одного тесту, в різних версіях тесту або при повторному тестуванні.
Валідність
Показує, наскільки даний тест вимірює ті показники, для вимірювання яких він призначений, або прогнозує те, що повинен прогнозувати.
Змістова валідность
Показує, наскільки даний тест досліджує саме ту поведінку, для вивчення якої він створений (наприклад, тест на водіння автомобіля оцінює уміння керувати ним).
Критерій
Аспект поведінки, який повинен бити передбачений за допомогою даного тесту. використовується для визначення прогностичної валідності тесту.
Прогностична валідность
Точність, з якою тест прогнозує поведінку, для прогнозу якої він був створений. Оцінюється за допомогою обчислення кореляції між результатами тесту і поведінковим критерієм (також носить назву "критерійно зубумовлена валідність").
Чому прогностична сила результатів оцінки здібностей зменшується у міру того, як учні просуваються по сходинках освіти? Розглянемо паралельну ситуацію: у всіх лінійних гравців регбі вага тіла має кореляцію з успіхом. Гравець вагою 120 кілограм може перемогти 85-кілограмового опонента. Але в межах вузьких меж — від 110 до 130 кілограм, характерних для професійного рівня — кореляція між вагою і успіхом стає незначною (мал. 11.6). Чим вужче за межа різниці ваги, тим нижчою стає прогностична сила ваги тіла.
Таким чином, якщо Гарвард приймає учнів тільки з дійсно високими оцінними показниками, їх ледве відчутно диференційовані оцінки навряд чи можуть що-небудь передбачити. Аналогічне звуження меж різниці пояснює, чому GRE — лише скромний провісник оцінок успішності в аспірантурі. Якщо в аспірантуру приймаються лише ті студенти, чиї тестові бали охоплюють вузьку область показників, не дивно, що їх тестові оцінки неточно передбачають їх успішність. Це справедливо навіть у тому випадку, коли тест має прекрасну прогностичну валідність з достатньо різноманітним представницьким набором студентів. Таким чином, коли ми валідизуємо тест, використовуючи велику кількість людей, а потім застосовуємо його для обмеженої групи, він втрачає велику частину своєї обґрунтованості. Звужена область оцінок успішності — як, наприклад, в аспірантурі, де ставляться в основному відмітки "5" і "4" — аналогічним чином скорочує прогностичну валідність.