

Зайцев М.Г., Варюхин С.Е. |
505 |
Приемы решения задач
7.П-1. Производитель снегоходов
Производитель снегоходов должен сделать заказ на двигатели на 1 месяц работы у внешнего поставщика. Время выполнения этого заказа поставщиком - 2 месяца. Кампания делает снегоходы на заказ и количество произведенной продукции определяется числом заказов на снегоходы в данном месяце. Какое число заказов компания будет иметь через 2 месяца (когда подойдет заказ от поставщика, который надо сделать сегодня) неизвестно, но предыдущий опыт позволяет оценить вероятность различных уровней спроса. Данные представлены в таблице.
Кол-во двигателей |
200 |
300 |
400 |
|
500 |
|
600 |
700 |
|
Вероятность продаж |
0.15 |
0.25 |
0.25 |
0.2 |
|
0.1 |
0.05 |
он |
|
Если купленный двигатель используется |
в тот месяц, |
для которого |
|||||||
куплен, он дает прибыль $300, если он залеживается до следующего месяца, это влечет убытки $100.
Постройте таблицу выигрышей и потерь. Используя принцип максимума ожидаемой монетарной ценности определите:
каков оптимальный размер заказа? какова цена совершенной информации?
Как изменится оптимальное решение, если потери от неиспользованного вовремя, двигателя составляют $300? Как при этом изменится стоимость совершенной информации?
Проанализируйте, насколько существенно изменится решение, если вероятности известны с точностью не лучше 5 процентных пунктов.
Сравните выводы, к которым приводят критерии максимина и минимаксных сожалений, с решением на основе максимума ожидаемой монетарной ценности альтернативы.
Решение задачи.
Для того чтобы построить таблицу выигрышей и потерь необходимо определиться, какие значения спроса (сценарии будущего) мы будем считать возможными и из каких предполагаемых размеров заказа мы будем выбирать оптимальный (альтернативы).
Данная в условиях задачи таблица распределения вероятностей различных значений спроса подталкивает к тому, чтобы в качестве возможных значений спроса выбрать 6 чисел, отраженных в ней. Это особенно естественно, поскольку для этих уровней спроса уже оценены соответствующие вероятности.
Отвлекаясь от конкретной формулировки условия задачи, обсудим происхождение представленной в условии таблицы распределения вероятностей
различных значений спроса? Как подробно обсуждалось в теоретическом введении к настоящей главе, существуют два источника для подобного рода информации: реальная выборка значений спроса, основанная на исторических данных, или экспертные оценки. Очевидно, что в реальной выборке различные «некруглые» значения спроса (например, 222, 390, 715 и т.п.) были сгруппированы в 6 диапазонов около представленных в таблице «круглых» значений от 200 до 700. Результаты построенной на исторических данных статистической выборки могут непосредственно использоваться для прогноза спроса на интересующий нас период времени в будущем (в этом случае говорят, что используется «наивный прогноз: завтра будет так же, как сегодня»). Разумеется, эти результаты можно скорректировать, используя экспертные оценки. Например, пусть из тех же исторических данных следует, что спрос на тот или иной продукт имеет сильную сезонную компоненту (что весьма реалистично для продажи снегоходов), или наш отдел маркетинга в настоящее время проводит мероприятия по интенсивному продвижению продукта так, что в следующем месяце ожидается существенное увеличение спроса, по сравнению с предыдущими месяцами, на основании которых и было получено распределение вероятностей, представленное в условии задачи. В этом случае, менеджеры отдела маркетинга могут предположить (на основании своего опыта), что представленные в таблице уровни спроса следует увеличить (например, на 30%), сохранив прежние оценки вероятностей этих уровней, или наоборот, сохранив возможные уровни продаж, сдвинуть максимум распределения вероятностей в сторону более высоких значений.
Поскольку вся эта «внутренняя кухня компании» осталась за рамками рассматриваемой задачи, примем, что данное в условии распределение вероятностей спроса следует непосредственно применить к интересующему нас месяцу. Тогда, для избежания не нужных сложностей, в качестве рассматриваемых альтернатив размера заказа естественно выбрать те же значения, что и уровни спроса, представленные в таблице.
Тогда таблицей выигрышей и потерь будет иметь 6 6=36 клеток, в каждой из которых необходимо подсчитать финансовый выигрыш или потерю. Если организовать таблицу так, как показано на рисунке (Рис. 260), то эти финансовые результаты должны содержаться в ячейках C4:H9. Их можно подсчитать для каждого из 36 вариантов развития событий отдельно, но это утомительно и, главное, совсем не в духе идеологии MS-Excel. Лучше составим формулу.
|
A |
|
B |
C |
|
D |
E |
F |
G |
|
H |
1 |
Прибыль= |
0.3 |
|
тыс. |
Потери= -0.1 тыс. |
|
|||||
2 |
|
|
|
|
Возможный спрос (состояние окружения) |
|
|||||
3 |
|
|
|
200 |
|
300 |
400 |
500 |
600 |
|
700 |
4 |
|
|
200 |
|
|
|
|
|
|
|
|
5 |
Варианты заказа |
|
300 |
|
|
|
|
|
|
|
|
6 |
|
400 |
|
|
|
|
|
|
|
|
|
7 |
(альтернативы) |
|
500 |
|
|
|
|
|
|
|
|
8 |
|
|
600 |
|
|
|
|
|
|
|
|
9 |
|
|
700 |
|
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
|
|
|
|
11 |
Вероятность спроса |
|
0.15 |
|
0.25 |
0.25 |
0.2 |
0.1 |
|
0.05 |
|
Рис. 260
При различных вариантах заказа и спроса может возникнуть две принципиально разных ситуации.
Первая ситуация. Спрос превысил сделанный заказ или в точности соответствовал ему. В этом случае мы продадим все, что у нас запасено на
Зайцев М.Г., Варюхин С.Е. |
507 |
данный месяц и не больше этого. В таблице C4:H9 этой ситуации отвечают ячейки, расположенные выше диагонали, идущей от ячейки C4 к ячейке H9 (либо расположенные на самой диагонали). Чтобы подсчитать прибыль в этих случаях достаточно, очевидно, умножить размер заказа на прибыль от продажи одной единицы. В виде формулы для протягивания для ячейки C4 это запишется так: =$B4*$C$1. Здесь ссылка на величину прибыли от использования одного двигателя в течение месяца со дня покупки фиксирована полностью и при протягивании не изменяется, а ссылка на размер заказа фиксирована только по столбцу. Это сделано для того, чтобы при протягивании формулы вправо ссылаться на одну и ту же величину заказа, а при протягивании вниз переходить к следующему размеру заказа, который меняется по строкам.
Вторая ситуация. Спрос оказался ниже размера заказа. В этом случае часть закупленных двигателей останется на складе и принесет убытки. Продадим мы столько двигателей, какова оказалась величина спроса, а разница между размером заказа и спросом останется. Поэтому прибыль для ячейки C9, например, запишется следующим образом: =C$3*$C$1+ ($B9-C$3)*$F$1. В первом слагаемом (полученной прибыли) ссылка на величину спроса C$3 фиксирована по строке, поэтому при протягивании формулы по вертикали не меняется, а при протягивании по горизонтали указывает на различную величину спроса. Во втором слагаемом ссылка на размер заказа фиксирована по столбцу, а ссылка на величину спроса по строке (все, как и в предыдущих случаях). Чтобы записать одну формулу для всех случаев, используем функцию =ЕСЛИ(..). В ячейке C4 запишем:
=ЕСЛИ($B4<=C$3;$B4*$C$1;C$3*$C$1+($B4-C$3)*$F$1),
т.е. если заказ меньше спроса или равен ему, используем формулу
=$B4*$C$1, а если нет – формулу = C$3*$C$1+($B4-C$3)*$F$1.
Распространив эту формулу на всю таблицу, получим следующий результат (Рис. 261).
|
A |
|
B |
C |
|
D |
|
E |
F |
G |
|
H |
1 |
Прибыль= |
0.3 |
|
тыс. |
|
Потери= -0.1 тыс. |
|
|||||
2 |
|
|
|
|
Возможный спрос (состояние окружения) |
|
||||||
3 |
|
|
|
200 |
|
300 |
|
400 |
500 |
600 |
|
700 |
4 |
|
|
200 |
|
60 |
|
60 |
60 |
60 |
60 |
|
60 |
5 |
Варианты заказа |
|
300 |
|
50 |
|
90 |
90 |
90 |
90 |
|
90 |
6 |
|
400 |
|
40 |
|
80 |
120 |
120 |
120 |
|
120 |
|
7 |
(альтернативы) |
|
500 |
|
30 |
|
70 |
110 |
150 |
150 |
|
150 |
8 |
|
|
600 |
|
20 |
|
60 |
100 |
140 |
180 |
|
180 |
9 |
|
|
700 |
|
10 |
|
50 |
90 |
130 |
170 |
|
210 |
10 |
|
|
|
|
|
|
|
|
|
|
|
|
11 |
Вероятность спроса |
|
0.15 |
|
0.25 |
|
0.25 |
0.2 |
0.1 |
|
0.05 |
|
Рис. 261
Из этой таблицы следует, что если мы закажем, например, 600 двигателей, то с вероятностью 0,15 получим $20 тыс. С вероятностью 0,25 получим $60 тыс., с такой же вероятностью 0,25 – $100 тыс., с вероятностью 0,2 – $140 тыс., с вероятностью 0,1 мы точно попадем в спрос и получим $180 тыс. и, наконец, с вероятностью 0.05 спрос превысит наш заказ и мы получим те же $180 тыс., что и при спросе 600 двигателей.
Используя эти данные можно оценить средний взвешенный финансовый результат EMV для каждой альтернативы (значения размера заказа). Рассчитаем величину EMV для каждой альтернативы, используя функцию =СУММПРОИЗВ(..). Для заказа в 700 двигателей функция будет иметь вид:

=СУММПРОИЗВ($C$11:$H$11;C9:H9). Ссылка на строку вероятностей фиксирована. Поместим эту формулу в ячейку I9 и протянем вверх до ячейки I4.
Величина EMV (Рис. 262) с ростом заказа меняется немонотонно: сначала растет от 60 тыс. до 102 тыс., а затем уменьшается до 90 тыс. Максимальная величина средней прибыли – 102 тыс. – соответствует заказу 500 двигателей.
|
A |
|
B |
C |
|
D |
|
E |
F |
G |
|
H |
I |
1 |
Прибыль= |
0.3 |
|
тыс. |
|
Потери= -0.1 тыс. |
|
|
|||||
2 |
|
|
|
|
Возможный спрос (состояние окружения) |
|
|
||||||
3 |
|
|
|
200 |
|
300 |
|
400 |
500 |
600 |
|
700 |
EMV |
4 |
|
|
200 |
|
60 |
|
60 |
60 |
60 |
60 |
|
60 |
60 |
5 |
Варианты заказа |
|
300 |
|
50 |
|
90 |
90 |
90 |
90 |
|
90 |
84 |
6 |
|
400 |
|
40 |
|
80 |
120 |
120 |
120 |
|
120 |
98 |
|
7 |
(альтернативы) |
|
500 |
|
30 |
|
70 |
110 |
150 |
150 |
|
150 |
102 |
8 |
|
|
600 |
|
20 |
|
60 |
100 |
140 |
180 |
|
180 |
98 |
9 |
|
|
700 |
|
10 |
|
50 |
90 |
130 |
170 |
|
210 |
90 |
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
11 |
Вероятность спроса |
|
0.15 |
|
0.25 |
|
0.25 |
0.2 |
0.1 |
|
0.05 |
|
|
Рис. 262
Как показано в теоретическом введении, дополнительная информация способна увеличить нашу ожидаемую прибыль и уменьшить риск потерь. Вычислим стоимость совершенной информации. Для этого сначала, в строке C10:H10 определим максимальные выигрыши при каждом сценарии будущего, используя функцию =МАКС(..).
Для ячейки C10 формула будет выглядеть следующим образом: =МАКС(C4:C9). При протягивании формулы вправо до ячейки H10, мы увидим, что каждый раз из столбца прибылей выбирается значение ячейки, расположенной на диагонали таблицы.
Так как вероятности каждого уровня спроса остаются прежними, мы можем подсчитать ожидаемую монетарную ценность в гипотетическом случае владения совершенной информацией (т.е. если каждый месяц некий ангелхранитель будет подсказывать нам точное значение спроса). Для этого просто протянем формулу в ячейке I9 вниз на одну ячейку (Рис. 263).
|
A |
|
B |
C |
|
D |
|
E |
F |
G |
|
H |
I |
1 |
Прибыль= |
0.3 |
|
тыс. |
|
Потери= |
-0.1 |
тыс. |
|
|
|||
2 |
|
|
|
|
Возможный спрос (состояние окружения) |
|
|
||||||
3 |
|
|
|
200 |
|
300 |
|
400 |
500 |
600 |
|
700 |
EMV |
4 |
|
|
200 |
|
60 |
|
60 |
60 |
60 |
60 |
|
60 |
60 |
5 |
Варианты заказа |
|
300 |
|
50 |
|
90 |
90 |
90 |
90 |
|
90 |
84 |
6 |
|
400 |
|
40 |
|
80 |
120 |
120 |
120 |
|
120 |
98 |
|
7 |
(альтернативы) |
|
500 |
|
30 |
|
70 |
110 |
150 |
150 |
|
150 |
102 |
8 |
|
|
600 |
|
20 |
|
60 |
100 |
140 |
180 |
|
180 |
98 |
9 |
|
|
700 |
|
10 |
|
50 |
90 |
130 |
170 |
|
210 |
90 |
10 |
Угадали спрос |
60 |
|
90 |
|
120 |
150 |
180 |
|
210 |
120 |
||
11 |
Вероятность спроса |
|
0.15 |
|
0.25 |
|
0.25 |
0.2 |
0.1 |
|
0.05 |
|
|
12 |
|
|
|
|
|
|
|
EMVPI= |
120 |
|
|
EVPI= |
18 |
Рис. 263
Оказывается, уникальный источник совершенной информации, каждый месяц сообщающий нам точные значения будущего спроса, увеличивает нашу ожидаемую прибыль всего на 18% (получим 102 тыс. вместо 120 тыс.). Эта величина и есть стоимость совершенной информацией EVPI, т.е. верхняя граница цены, которую мы готовы платить за информацию при выборе из рассматриваемых альтернатив при данных сценариях будущего.
Как уже неоднократно подчеркивалось, совершенную информацию (особенно о спросе) получить невозможно. Несовершенная информация (основанная на экспертных оценках) всегда носит вероятностный характер и
Зайцев М.Г., Варюхин С.Е. |
509 |
действует на статистическое распределение вероятностей, изменяя его в ту или другую сторону. Например, если наши эксперты из отдела маркетинга говорят, что спрос в следующем месяце будет выше обычного, это, очевидно, означает, что вероятности высокого спроса должны увеличиться, а вероятности низкого спроса, напротив, уменьшиться. В нашей таблице вероятность того, что спрос не превысит 400 двигателей, равна 0,65 (0,15+0,25+0,25), а вероятность того, что спрос будет 500 двигателей и выше – 0,35. Т.е. вероятность низкого спроса почти вдвое выше вероятности высокого. Предположим, что информация экспертов выравнивает эти вероятности. Тогда распределение вероятностей можно записать, вычитая из первых трех вероятностей по 0.05, и добавляя столько же к последним трем вероятностям (см. таблицу Рис. 264).
Оценка распределения вероятностей при учете информации
Спрос |
200 |
300 |
400 |
500 |
600 |
700 |
|
Вероятности при |
0.1 |
0.2 |
0.2 |
0.25 |
0.15 |
0.1 |
|
повышенном спросе |
|||||||
|
|
|
|
|
|
||
Вероятности при |
0.2 |
0.3 |
0.3 |
0.15 |
0.05 |
0 |
|
пониженном спросе |
|||||||
|
|
|
|
|
|
Рис. 264
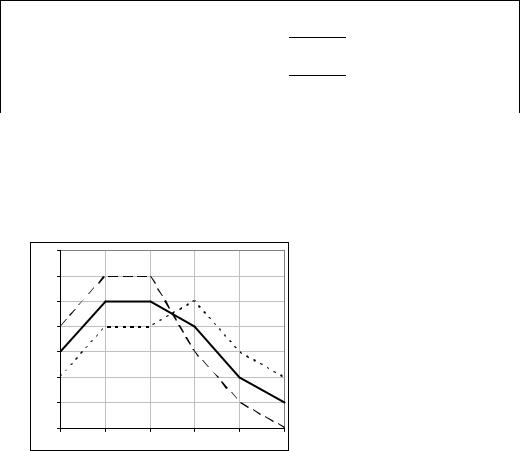
В свою очередь, если спрос в следующем месяце ожидается ниже, чем в текущем, мы можем оценить изменение распределения вероятностей, уменьшив вероятности высокого спроса и увеличив, соответственно, вероятности низкого (см. таблицу на рис. 206 ). Для сравнения на рисунке (Рис. 265) все три распределения показаны в виде графиков.
0.35 |
|
|
|
|
|
0.3 |
|
|
|
|
|
0.25 |
|
|
|
|
|
0.2 |
|
|
|
|
|
0.15 |
|
|
|
|
|
0.1 |
|
|
|
|
|
0.05 |
|
|
|
|
|
0 |
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
Рис. 265
Жирной непрерывной линией показано первоначальное распределение. Для вновь полученных распределений вероятностей спроса нужно
повторить расчеты максимального значения EMV. Скопируем построенную раньше таблицу на два новых листа Excel (через команду Переместить\Скопировать…). Заменим в этих листах вероятности на новые и получим следующий результат (Рис. 266).

|
A |
|
B |
C |
|
D |
|
E |
F |
G |
|
H |
I |
1 |
Прибыль= |
0.3 |
|
тыс. |
|
Потери= -0.1 тыс. |
|
|
|||||
2 |
|
|
|
|
Возможный спрос (состояние окружения) |
|
|
||||||
3 |
|
|
|
200 |
|
300 |
|
400 |
500 |
600 |
|
700 |
EMV |
4 |
|
|
200 |
|
60 |
|
60 |
60 |
60 |
60 |
|
60 |
60 |
5 |
Варианты заказа |
|
300 |
|
50 |
|
90 |
90 |
90 |
90 |
|
90 |
82 |
6 |
|
400 |
|
40 |
|
80 |
120 |
120 |
120 |
|
120 |
92 |
|
7 |
(альтернативы) |
|
500 |
|
30 |
|
70 |
110 |
150 |
150 |
|
150 |
90 |
8 |
|
|
600 |
|
20 |
|
60 |
100 |
140 |
180 |
|
180 |
82 |
9 |
|
|
700 |
|
10 |
|
50 |
90 |
130 |
170 |
|
210 |
72 |
10 |
Угадали спрос |
60 |
|
90 |
|
120 |
150 |
180 |
|
210 |
107 |
||
11 |
Вероятность спроса |
|
0.2 |
|
0.3 |
|
0.3 |
0.15 |
0.05 |
|
0 |
|
|
|
Рис. 266 Расчет EMV альтернатив для пониженного спроса |
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
||
|
A |
|
B |
C |
|
D |
|
E |
F |
G |
|
H |
I |
1 |
Прибыль= |
0.3 |
|
тыс. |
|
Потери= -0.1 тыс. |
|
|
|||||
2 |
|
|
|
|
Возможный спрос (состояние окружения) |
|
|
||||||
3 |
|
|
|
200 |
|
300 |
|
400 |
500 |
600 |
|
700 |
EMV |
4 |
|
|
200 |
|
60 |
|
60 |
60 |
60 |
60 |
|
60 |
60 |
5 |
Варианты заказа |
|
300 |
|
50 |
|
90 |
90 |
90 |
90 |
|
90 |
86 |
6 |
|
400 |
|
40 |
|
80 |
120 |
120 |
120 |
|
120 |
104 |
|
7 |
(альтернативы) |
|
500 |
|
30 |
|
70 |
110 |
150 |
150 |
|
150 |
114 |
8 |
|
|
600 |
|
20 |
|
60 |
100 |
140 |
180 |
|
180 |
114 |
9 |
|
|
700 |
|
10 |
|
50 |
90 |
130 |
170 |
|
210 |
108 |
10 |
Угадали спрос |
60 |
|
90 |
|
120 |
150 |
180 |
|
210 |
134 |
||
11 |
Вероятность спроса |
|
0.1 |
|
0.2 |
|
0.2 |
0.25 |
0.15 |
|
0.1 |
|
|
Рис. 267 Расчет EMV альтернатив для повышенного спроса
Как мы можем видеть, при повышенном спросе (Рис. 267) максимальное значение EMV (114 тыс.) соответствует выбору либо 500, либо 600 двигателей. При пониженном спросе (Рис. 266) максимальное значение EMV (92 тыс.) соответствует выбору 400 двигателей. Однако результат заказа 500 двигателей всего на 2 тыс. хуже.
Это означает, что если мы будем все время заказывать 500 двигателей и не станем реагировать на сигналы о возможном повышенном или пониженном спросе, то фактически ничего не потеряем. Выбор 500 двигателей оптимален и остается таковым даже при значительных вариациях вероятностей сценариев будущего, отражающих возможные вариации спроса. Это небольшое исследование является ответом и на вопрос о том, изменяется ли оптимальное решение, если учесть, что все вероятности известны нам с точностью не лучше 5 процентных пунктов. Мы взяли два крайних случая того, как может выглядеть истинное распределение вероятностей спроса и, выбранное первоначально решение –заказать 500 двигателей, практически не изменилось.
Наряду с распределением вероятностей спроса большое влияние на выработку решения имеет относительная величина возможных потерь. Мы говорим относительная, так как значение имеет соотношение величин прибыли от использования двигателя в конечном изделии и потери от его хранения в течение лишнего месяца. В первоначальной постановке задачи ожидаемые потери в три раза меньше, чем прибыль. Из-за этого оптимальный размер заказа получается выше, чем среднее значение ежемесячного спроса. Мы, кстати, до сих пор не подсчитывали, каков именно этот средний спрос. Давайте сделаем это сейчас.
Расчет среднего спроса делается точно так же, как и ожидаемой монетарной ценности, только теперь значения спроса мы умножаем на соответствующие вероятности. Добавим в какую-нибудь ячейку формулу
=СУММПРОИЗВ($C$11:$H$11;C3:H3).
Зайцев М.Г., Варюхин С.Е. |
511 |
Результат вычисления оказывается равным 400 двигателей.
Таким образом, мы получили оптимальный размер заказа в 500 двигателей при среднем спросе 400 двигателей. Это, как мы уже отметили, связано с тем, что прибыль от своевременного использования двигателя выше, чем потери от его хранение в течение лишнего месяца.
В задаче спрашивается, как изменится решение, если потери достигают 300 единиц. При этом размер прибыли в расчете на один двигатель равен потерям. Если вспомнить идеологию однопериодной модели заказа, связь которой с данной задачей очевидна, то можно предположить, что в этих условиях выгоднее всего окажется заказ, равный среднему. Проверим это, изменив в исходной таблице (Рис. 263) величину потерь на -0,3 тысячи (Рис. 268).
|
A |
|
B |
C |
D |
E |
F |
G |
|
H |
I |
1 |
Прибыль= |
0.3 |
тыс. |
Потери= |
-0.3 |
тыс. |
|
|
|||
2 |
|
|
|
Возможный спрос (состояние окружения) |
|
|
|||||
3 |
|
|
|
200 |
300 |
400 |
500 |
600 |
|
700 |
EMV |
4 |
|
|
200 |
60 |
60 |
60 |
60 |
60 |
|
60 |
60 |
5 |
Варианты заказа |
|
300 |
30 |
90 |
90 |
90 |
90 |
|
90 |
81 |
6 |
|
400 |
0 |
60 |
120 |
120 |
120 |
|
120 |
87 |
|
7 |
(альтернативы) |
|
500 |
-30 |
30 |
90 |
150 |
150 |
|
150 |
78 |
8 |
|
|
600 |
-60 |
0 |
60 |
120 |
180 |
|
180 |
57 |
9 |
|
|
700 |
-90 |
-30 |
30 |
90 |
150 |
|
210 |
30 |
10 |
Угадали спрос |
60 |
90 |
120 |
150 |
180 |
|
210 |
120 |
||
11 |
Вероятность спроса |
|
0.15 |
0.25 |
0.25 |
0.2 |
0.1 |
|
0.05 |
400 |
|
12 |
|
|
|
|
|
EMVPI= |
120 |
|
|
EVPI= |
33 |
Рис. 268
Как мы видим, оптимальный заказ, соответствующий максимальному значению EMV=87 тыс., действительно равен 400 двигателям. Построенная таблица содержит и другую интересную, с точки зрения формирования заказа,
информацию. Например, из того, что EMV300=81 тыс., а EMV500=78 тыс., можно сделать вывод, что ошибка в величине заказа в меньшую сторону обойдется
дешевле, чем в сторону завышения.
В целом же условия бизнеса ухудшились. Возможные потери, в случае если мы завысили оценку спроса, увеличились. Поэтому ожидаемая прибыль при оптимальном размере заказа и стала меньше.
Здесь же отметим и возросшую цену совершенной информации (EVPI=33 тыс.). Это соответствует общему принципу, который понятен и интуитивно: чем выше риск и вероятные потери, тем дороже информация.
Проверьте, что стоимость совершенной информации обращается в ноль, если возможные потери статут равны нулю. И снова все понятно: если информация не приносит дополнительных денег она ничего не стоит!
Последний вопрос задачи фактически тоже связан с точность имеющейся у нас статистической информации. Допустим, что статистики по снегоходам у нас нет. Приведенные значения вероятностей мы взяли из данных о спросе на какойлибо близкий товар, из экспертных оценок, но совершенно не уверены, что они справедливы в нашем случае. Попробуем, в этой ситуации, привлечь оценки по критериям максимина и минимаксных сожалений.
Оценка по критерию максимина очень проста и не требует каких-либо изменений в проделанных уже расчетах. Вернемся к первоначальной таблице (Рис. 269). Согласно критерию максимина, для каждой альтернативы нужно выбрать тот сценарий будущего, при котором наш выигрыш минимален (это критерий пессимиста – с нами случится самое худшее, какую бы альтернативу мы

ни выбрали), а затем выбрать ту альтернативу, где это «самое худшее» лучше всех остальных. В данной задаче, независимо от выбранной альтернативы, самое худшее – это наименьший спрос– 200 двигателей. Посмотрим по таблице, при каком заказе прибыль для спроса 200 двигателей максимальна. Ясно, что это 60 тыс., и соответствует такая величина прибыли заказу 200 двигателей. Это и есть оптимальное решение по критерию максимина.
|
A |
|
B |
C |
|
D |
|
E |
F |
G |
|
H |
I |
1 |
Прибыль= |
0.3 |
|
тыс. |
|
Потери= |
-0.1 |
тыс. |
|
|
|||
2 |
|
|
|
|
Возможный спрос (состояние окружения) |
|
|
||||||
3 |
|
|
|
200 |
|
300 |
|
400 |
500 |
600 |
|
700 |
EMV |
4 |
|
|
200 |
|
60 |
|
60 |
60 |
60 |
60 |
|
60 |
60 |
5 |
Варианты заказа |
|
300 |
|
50 |
|
90 |
90 |
90 |
90 |
|
90 |
84 |
6 |
|
400 |
|
40 |
|
80 |
120 |
120 |
120 |
|
120 |
98 |
|
7 |
(альтернативы) |
|
500 |
|
30 |
|
70 |
110 |
150 |
150 |
|
150 |
102 |
8 |
|
|
600 |
|
20 |
|
60 |
100 |
140 |
180 |
|
180 |
98 |
9 |
|
|
700 |
|
10 |
|
50 |
90 |
130 |
170 |
|
210 |
90 |
10 |
Угадали спрос |
60 |
|
90 |
|
120 |
150 |
180 |
|
210 |
120 |
||
11 |
Вероятность спроса |
|
0.15 |
|
0.25 |
|
0.25 |
0.2 |
0.1 |
|
0.05 |
400 |
|
12 |
|
|
|
|
|
|
|
EMVPI= |
120 |
|
|
EVPI= |
18 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Макс. |
14 |
|
|
|
200 |
|
300 |
|
400 |
500 |
600 |
|
700 |
потери |
15 |
|
|
200 |
|
0 |
|
30 |
60 |
90 |
120 |
|
150 |
150 |
16 |
Варианты заказа |
|
300 |
|
10 |
|
0 |
30 |
60 |
90 |
|
120 |
120 |
17 |
|
400 |
|
20 |
|
10 |
0 |
30 |
60 |
|
90 |
90 |
|
18 |
(альтернативы) |
|
500 |
|
30 |
|
20 |
10 |
0 |
30 |
|
60 |
60 |
19 |
|
|
600 |
|
40 |
|
30 |
20 |
10 |
0 |
|
30 |
40 |
20 |
|
|
700 |
|
50 |
|
40 |
30 |
20 |
10 |
|
0 |
50 |
Рис. 269
Для оценки по критерию минимаксных сожалений необходимо построить таблицу упущенных возможностей. В этой таблице на месте финансового выигрыша (или потери) в каждой клетке должна содержаться разница между максимально возможной прибылью для данного уровня спроса (строка C10:H10) и прибылью из таблицы C4:H9. Запишем в ячейку C15 формулу =C$10-C4 и распространим ее на всю вторую таблицу C15:H20 (Рис. 211). После этого нам нужно выбрать для каждого размера заказа максимальные упущенные возможности («самое худшее» - по критерию максимальных сожалений). Добавим к таблице столбец «Макс. потери». Запишем в ячейку I15 формулу =МАКС(C15:H15) и протянем ее вниз до ячейки I20. Таким образом, мы получили максимальные упущенные возможности для каждой альтернативы - размера заказа. Обратите внимание, что эти упущенные возможности имеют разную природу. Все числа выше диагонали (здесь наши упущенные возможности равны нулю, так как заказ оказался в точности равным спросу) – это неполученная прибыль. Числа ниже диагонали – прямые финансовые потери. Согласно критерию максимаксных сожалений мы должны учитывать эти два вида потерь на равных основаниях.
Величина максимальных упущенных возможностей с увеличением размера заказа тоже меняется немонотонно - сначала уменьшается, а потом растет. Самое маленькое значение этой величины - 40 тыс. - соответствует заказу в 600 двигателей. Заметьте, что выбор по критерию минимаксных сожалений зависит только от соотношения прибылей и потерь и не учитывает распределение вероятностей. Тем не менее, в данном случае, выбор оказывается близким к выбору в соответствии с критерием максимума EMV.