

7.2. Базы данных: особый подход к управлению данными
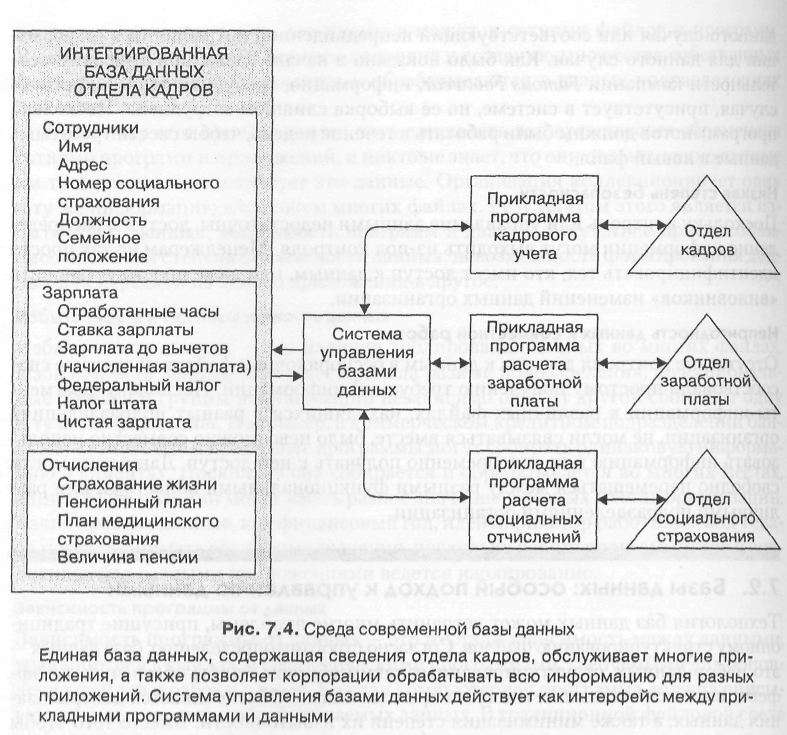
Технология баз данных может устранить многие проблемы, присущие традиционному структурированию файлов. Согласно строгому определению, база данных — это набор данных, структурированных таким образом, чтобы обеспечить их эффективное использование многими приложениями. Обеспечивается централизация данных, а также минимизация степени их избыточности. Вместо того чтобы хранить данные в отдельных файлах, соответствующих каждому отдельному приложению, они фактические хранятся только в одном месте. Единственная база данных обслуживает многие прикладные программы. Например, вместо хранения данных о сотрудниках корпорации в отдельных информационных системах и в отдельных файлах для учета персонала, расчета зарплаты и пособий корпорация может создать единственную общую базу данных по трудовым ресурсам. На рис. 7.4 иллюстрируется концепция подобной базы данных.
Системы управления базами данных
Система управления базами данных (СУБД) — это программное обеспечение, позволяющее централизовать данные, эффективно ими управлять, а также обеспечивать доступ прикладным программам к хранящейся информации. СУБД выступает в качестве интерфейса между прикладными программами и физическими файлами данных. Когда прикладная программа вызывает такой элемент данных, как информация о начисленной зарплате, СУБД находит соответствующую позицию в базе данных и предоатавляет ее прикладной программе. Используя традиционные файлы данных, программист должен указывать размер
и формат каждого элемента данных, использованного в программе, а после этого сообщать компьютеру о том, где они находятся.
С УБД освобождает программиста или конечного пользователя от необходимости разбираться в том, где и в каком виде хранятся данные, путем разделения логического и физического представления данных.
Database (rigorous definition) (базы данных (строгое определение))
Организованное собрание данных, предназначенных для одновременного использования многими приложениями путем хранения и управления ими таким образом, что они оказываются в одном месте.
Database management system (DBMS) (система управления базами данных/СУБД)
Специальное программное обеспечение для создания баз данных и работы с ними и позволяющие отдельным приложениям извлекать необходимые данные без создания собственных файлов или определения данных в своих компьютерных программах.
Логическое представление структурирует данные в том виде, в котором они отображаются для конечного пользователя или специалиста, в то время как физическое представление демонстрирует, каким образом в действительности организованы и структурированы данные на физическом носителе информации. Существует только одно физическое представление данных, которому могут соответствовать различные логические представления. Программное обеспечение управления базами данных представляет физическую базу данных в различных логических представлениях для разных прикладных программ. Например, программа выплаты пособий служащим может использовать логическое представление базы данных по трудовым ресурсам, изображенное на рис. 7.4. Здесь отображается только имя служащего, его адрес, номер социального страхования, пенсионный план, а также данные по пособиям. Система управления базами данных включает три компонента:
• язык определения данных;
• язык манипуляции данными;
• словарь данных.
Язык определения данных — это формальный язык, который используют программисты для указания содержания и структуры базы данных. Этот язык описывает каждый элемент данных, который будет представлен в базе, прежде чем этот элемент будет переведен в форму, необходимую для функционирования прикладных программами.
Б ольшинство
СУБД снабжены специальными языками,
которые называются языками манипуляции
данными. Эти
языки используются в сочетании с
некоторыми обычными языками
программирования третьего и четвертого
поколения для манипуляции данными в
базе. Этот язык включает команды, которые
позволяют конечному пользователю
или программисту выбирать данные из
базы данных для получения запрашиваемой
информации, а
также
для разработки приложений. Наиболее
распространенным языком манипуляции
данными является структурированный
язык запросов (SQL,
Structured
Query
Language).
Комплекс паданий по программированию
не может быть требуемым образом выражен
с помощью типичных языков манипуляции
данными. Однако большинство основных
ольшинство
СУБД снабжены специальными языками,
которые называются языками манипуляции
данными. Эти
языки используются в сочетании с
некоторыми обычными языками
программирования третьего и четвертого
поколения для манипуляции данными в
базе. Этот язык включает команды, которые
позволяют конечному пользователю
или программисту выбирать данные из
базы данных для получения запрашиваемой
информации, а
также
для разработки приложений. Наиболее
распространенным языком манипуляции
данными является структурированный
язык запросов (SQL,
Structured
Query
Language).
Комплекс паданий по программированию
не может быть требуемым образом выражен
с помощью типичных языков манипуляции
данными. Однако большинство основных
Логическое представление
Представление данных в том виде, в котором они должны появляться в приложении программиста или конечного пользователя.
Physical view (физическое представление)
Представление данных в том виде, в котором они действительно должны быть организованы на физическом носителе информации.
Data definition language (язык определения данных)
Компонент системы управления базой данных, определяющий, как представлен каждый элемент в базе данных.
Data manipulation language (язык манипуляции данными)
Язык, связанный с системой управления базой данных, который применяют конечный пользователь и программист для манипуляции данными в базе данных.
S tructured
query
language
(SQL)
(структурированный язык запросов)
tructured
query
language
(SQL)
(структурированный язык запросов)
Стандартный язык манипуляции данными в системах управления реляционными базами данных.
Data dictionary (словарь данных)
Автоматическое или ручное средство программирования, применяемое для хранения и организации информации о данных, находящихся в базе данных.
Data element (элементы данных)
Поле.
СУБД совместимо с языками Кобол, Фортран и другими языками программирования третьего поколения, позволяющими выполнять гибкую и эффективную обработку данных.
Третьим элементом СУБД является словарь данных. Этот файл создается в автоматическом или ручном режиме. В нем содержатся определения элементов данных, а также таких их характеристик, как использование, физическое представление, принадлежность владельцу (лицу в организации, отвечающему за данные), авторизация и безопасность. Многие словари данных могут выводить списки и отчеты об использовании данных, их группировке, размещении программ и т. д. На рис. 7.5 показан пример отчета по словарю данных, показывающий размер, формат, значение; он использует элементы данных базы персонального учета.
Элемент данных представляет собой поле. Кроме списка стандартных имен (АМТ-PAY-BASE) словарь отображает список имен, на которые ссылается элемент в данной системе. Также указываются позиции, бизнес-функции, программы и отчеты, в которых используется этот элемент.
Создавая опись данных, которые содержатся в конкретной базе данных, словарь данных (AMT-PAY-BASE) служит важным средством, позволяющим управлять данными. Например, бизнес-пользователь может обратиться к словарю для поиска определенного элемента данных, используемого при продажах или маркетинге, или даже выяснить всю информацию, касающуюся целого предприятия. Пользователи могут найти в словаре описания имен, форматов, а также специфицированных требований, определяющих доступ к данным для создания отчета. Технические специалисты могут использовать словарь для определения элементов данных и файлов, изменяемых при модификации программы.
Большинство словарей сами по себе пассивны; они просто отображают данные. Более совершенные типы словарей активны; изменения в словаре может автоматически отображаться в связанных с ним программах. Например, чтобы изменить размер почтового кода с пяти до девяти цифр, можно просто обратиться к словарю, изменив там размер кода. При этом не требуется модифицировать и перекомпилировать другие программы, использующие эти почтовые коды.
В идеальной среде базы данных ее элементы определяются только один раз и используются всеми приложениями, использующими данные из этой базы. Благодаря этому исключаются избыточность и противоречивость данных. Прикладные программы, которые написаны с использованием языка манипуляции СУБД, а также совместимых с ним языков программирования, запрашивают эле-
NAME: AMT-PAY-BASE
FOCUS NAME: BASEPAY
PC NAME: SALARY
DESCRIPTION: EMPLOYEE'S ANNUAL SAURY
SIZE: 9 BYTES
TYPE: N (NUMERIC)
DATE CHANGED: 01/01/95
OWNERSHIP: COMPENSATION
UPDATE SECURITY: SITE PERSONNEL
ACCESS SECURITY: MANAGER, COMPENSATION PLANNING AND RESEARCH
MANAGER, JOB EVALUATION SYSTEMS
MANAGER, HUMAN RESOURCES PLANNING
MANAGER, SITE EQUAL OPPORTUNITY AFFAIRS
MANAGER, SITE BENEFITS
MANAGER, CLAIMS PAYING SYSTEMS
MANAGER, QUALIFIED PLANS
MANAGER, SITE EMPLOYMENT/EEO
BUSINESS FUNCTIONS USED BY: COMPENSATION
HR PLANNING
EMPLOYMENT
INSURANCE
PENSION
401K
PROGRAMS USING: PI01000
PI02000
PI03000
PI04000
PI05000
REPORTS USING: REPORT 124 (SALARY INCREASE TRACKING REPORT)
REPORT 448 (GROUP INSURANCE AUDIT REPORT)
REPORT 452 (SALARY REVIEW LISTING)
PENSION REFERENCE LISTING
Рис. 7.5. Пример отчета словаря данных
Этот пример отчета словаря базы данных по персональному учету предоставляет такую вспомогательную информацию, как размер элемента данных, который используют программы и отчеты, информацию о том, какая группа в организации является владельцем элемента данных и может работать с ним. Отчет также показывает другие имена, используемые в организации для именования этого элемента
менты данных из этой базы данных. Элементы данных, вызываемые прикладными программами, извлекаются из базы данных и предоставляются им средствами СУБД. Программисту не требуется подробно указывать, где и каким образом выбираются эти данные.
СУБД может снизить взаимозависимость программ и данных, а также уменьшить стоимость разработки и применения программ. Наличие информации и доступ к ней может улучшаться, поскольку пользователи и программисты могут генерировать требуемые запросы к данным, находящимся в базе. СУБД позволяет организации централизованным образом решать вопросы управления, применения и обеспечения безопасности данных.
R elation
DBMS
(реляционная СУБД)
elation
DBMS
(реляционная СУБД)
Логический тип базы данных, в котором данные представляются в виде двухмерной таблицы. Это позволяет связывать данные, находящиеся в двух таблицах, как будто бы эти две таблицы имеют общий элемент данных.
Tuple (кортеж)
Строка или запись в реляционной базе данных.
Типы баз данных
Современные СУБД используют различные модели для работы с объектами, атрибутами, связями. Каждая такая модель имеет определенные преимущества в своей работе при ее использовании в разных бизнесах.
Реляционные СУБД
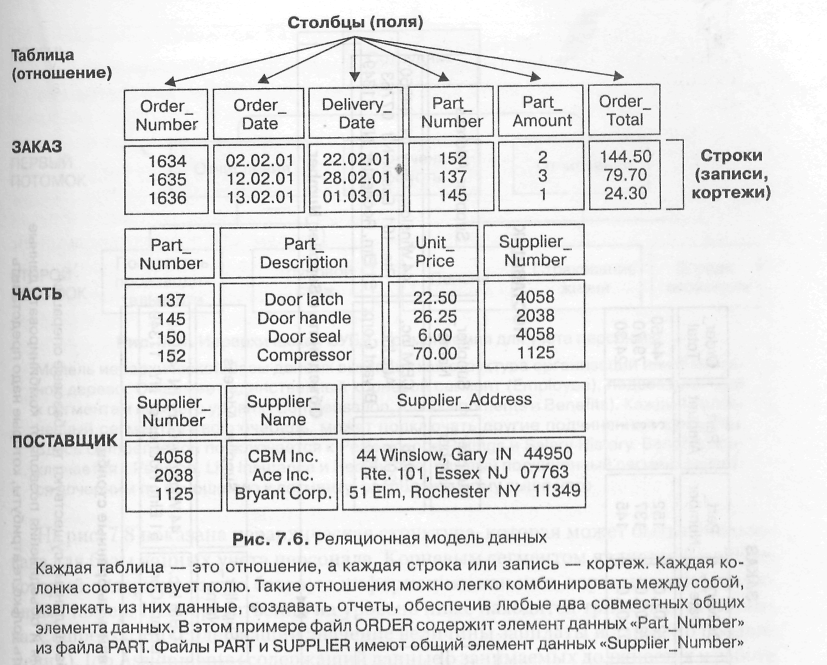
Сегодня наиболее популярным типом баз данных для персональных компьютеров, а также для больших компьютеров и мэйнфреймов являются реляционные базы данных. Реляционная модель данных представляет все данные базы наподобие двухмерных таблиц, называемых отношениями. Эти таблицы напоминают простые файлы, но информация, находящаяся в двух или большем количестве подобных таблиц, может быть извлечена и перестроена несложным способом. Иногда эти таблицы называют файлами.
На рис. 7.6 показана таблица поставщиков, таблица деталей и таблица заказов. В каждой таблице строка является уникальной записью, а столбцы соответствуют полям. Другими словами, каждая строка или запись в отношении является кортежем. Для создания требуемого отчета пользователи часто нуждаются в информации из многих отношений. В этом проявляется сила реляционной модели: можно соотнести данные из одного файла или таблицы с данными из другого файла или таблицы, если в обеих таблицах есть общий элемент данных.
С целью демонстрации этой связи предположим, что мы хотим найти в реляционной базе данных, показанной на рис. 7.6, имена и адреса поставщиков, которые могли бы обеспечить нас деталями 137 и 152. Нам нужна информация из двух таблиц: таблицы поставщиков и таблицы деталей. Заметим, что эти два файла содержат общий элемент: Supplier_Number.
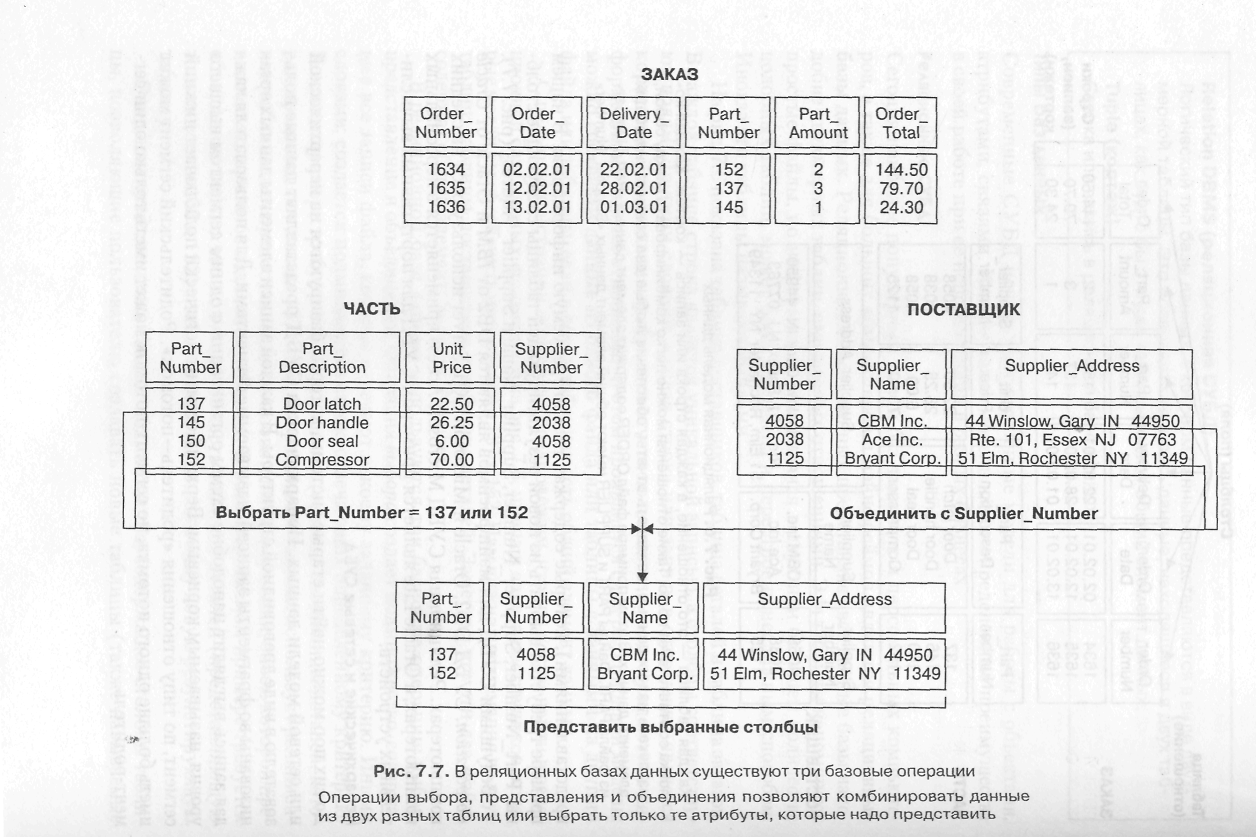
В реляционной базе данных используются три базисные операции: выбор, представление и объединение. Операция выбора создает подмножество, содержащее все записи файла, которые отвечают некоему заданному критерию. Иными словами, создается подмножество строк, отвечающих определенному критерию. В нашем примере требуется выбрать записи (строки) из таблицы деталей, которые представляют детали 137 и 152. Операция объединения использует реляционные таблицы для предоставления пользователю информации, объем которой превышает содержимое отдельной таблицы. В рассматриваемом примере требуется объединить только что полученную часть таблицы деталей (представляющую только детали 137 и 152) с таблицей поставщиков в одну новую результирующую таблицу.
Операция представления создает подмножество, содержащее столбцы таблицы, позволяющие пользователю создавать новые таблицы (также называемые
представлениями), которые содержат только требуемую информацию. В нашем примере требуется выбрать из новой результирующей таблицы следующие столбцы: Part_Number, Supplier_Number, Supplier_Name и Supplier_Address (рис. 7.7).
Ведущими СУБД для мэйнфреймов являются DB2 от IBM и Oracle от Oracle Corporation. СУБД DB2, Oracle и Microsoft SQL Server используются на средних компьютерах. Реляционная СУБД Microsoft Access применяется в персональных компьютерах, a Oracle Lite является примером СУБД для портативных вычислительных устройств.
Иерархические и сетевые СУБД
До сих пор можно найти старые системы, которые базируются на иерархической или сетевой модели данных. Иерархическая СУБД представляет данные пользователю в виде древовидной структуры. В каждой записи элементы данных организованы во фрагменты записей, называемые сегментами. Для пользователя каждая запись выглядит наподобие схемы организации с одним сегментом высшего уровня, называемым корневым. Верхний сегмент логически подключает нижний сегмент, по типу отношения «родитель—потомок». Родительский сегмент может иметь больше одного потомка, но сегмент-потомок может иметь только один сегмент-родитель.
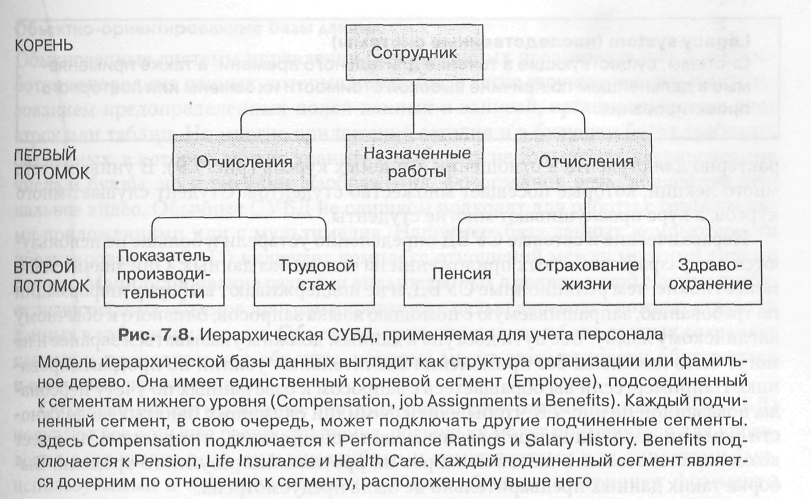
На рис. 7.8 показана иерархическая структура, которая может быть использована для базы данных учета персонала. Корневым сегментом является Employee, который содержит такую базовую информацию, как имя, адрес, идентификационный номер. Непосредственно на уровень ниже находятся три сегмента-потомка: Compensation (содержащий значение величины зарплаты и данные о продвижении), Job Assignments (содержащий данные о занимаемых должностях и работе в разных отделах) и сегмент Benefits (содержащий данные о пособиях и их типах). Сегмент Compensation имеет два дочерних сегмента: Performance Ratings (содержащий данные о ставке работника) и Salary History (содержащие данные о прошлых зарплатах работника). Под сегментом Benefits находятся сегменты Pension, Life Insurance и Health, которые содержат данные по этим типам пособий.
В то время как иерархическая структура
представляет отношение «один ко многим»,
сетевая
СУБД представляет
логически организованные данные по
типу отношений «многие ко многим».
Другими словами, родительские элементы
могут иметь много элементов-потомков,
а дочерние элементы — больше чем один
родительский. Типичное отношение «многие
ко многим» для сетевой СУБД ха-
то время как иерархическая структура
представляет отношение «один ко многим»,
сетевая
СУБД представляет
логически организованные данные по
типу отношений «многие ко многим».
Другими словами, родительские элементы
могут иметь много элементов-потомков,
а дочерние элементы — больше чем один
родительский. Типичное отношение «многие
ко многим» для сетевой СУБД ха-
Hierarchical DBMS (иерархические СУБД)
Более старая логическая модель СУБД организует данные в древовидные структуры. Запись подразделяется на сегменты, подключаемые один к другому в отношении «один ко многим», это взаимоотношение «родитель—потомок».
Network DBMS (сетевые СУБД)
Старая логическая модель СУБД, полезная при наличии отношения «многие ко многим».
L egacy
system
(наследственные системы)
egacy
system
(наследственные системы)
Системы, существующие в течение длительного времени, а также применяемые в дальнейшем по причине высокой стоимости их замены или повторного проектирования.
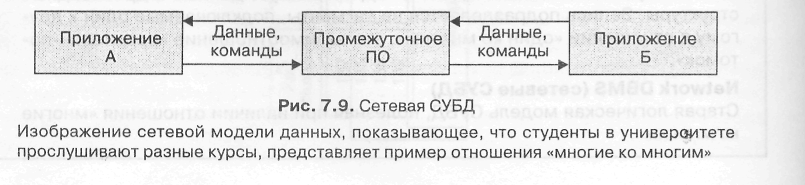
рактерно для студента в отношении читаемых курсов (рис. 7.9). В университете много лекций, которые посещает множество студентов. Студент слушает много курсов, а курс прослушивают многие студенты.
Иерархические и сетевые СУБД определенно устарели и больше не используются для разработки новых приложений на основе баз данных. Они значительно менее гибкие, чем реляционные СУБД, и не поддерживают выборку информации по требованию, запрашиваемую с помощью языка запросов, близкого к обычному английскому языку. Все пути доступа к данным должны указываться заранее и не могут быть изменены без применения значительных усилий по программированию. Например, если вы обращаетесь с запросом к базе данных по учету персонала, показанной на рис. 7.8, чтобы найти фамилии служащих, занятых на должности помощника администратора, вы можете обнаружить, что система не имеет возможности ответить на такой запрос на протяжении разумного времени. Выборка таких данных предварительно не была предусмотрена.
В отличие от упомянутых типов данных реляционные СУБД значительно гибче в предоставлении данных в ответ на текущие запросы, могут собирать информацию из разных источников, а также обеспечивают возможность добавления новых данных и записей без изменения существующих программ и приложений. Однако эти системы могут быть медленными, если для выполнения команд выборки, объединения или представления требуется большое количество обращений к хранящимся на диске данным. Выбор отдельного числа из миллионов вариантов, одной записи за одно обращение может занимать длительное время. Конечно, работу базы данных можно ускорить, заранее формируя запросы.
Иерархические СУБД все еще встречаются в больших давно разработанных системах, которые требуют интенсивной обработки транзакций большого объема. Это наследственные системы, которые существовали на протяжении длительного времени, продолжают использоваться вследствие высокой стоимости их замены или переделки. Банки, страховые компании и другие пользователи, обрабатывающие большие объемы информации, продолжают использовать такие существующие иерархические базы данных, как IMS (Information Management System) от IBM, разработанные в 1969 г. Поскольку реляционные базы данных более мощные, фирмы полностью отказались от иерархических СУБД, но выполнение подобного перехода заняло много времени.
Объектно-ориентированные базы данных
Обыкновенные системы управления базами данных предназначались для обработки однородных данных, которые можно было легко структурировать с использованием предопределенных полей данных и записей, организованных в виде строк или таблиц. Но многие приложения сегодня и в будущем будут требовать баз данных, в которых можно хранить и выбирать не только структурированные числа и буквы, но и рисунки, изображения, фотографии, речь, полнофункциональное видео. Обычные СУБД не слишком подходят для работы с графическими приложениями или с мультимедиа. Например, база данных компьютерного проектирования (CAD) включает комплекс отношений между многими типами данных. Манипулирование разными видами данных в реляционной системе требует значительных объемов программирования с целью перевода сложных структур данных в таблицы и строки. Объектно-ориентированная база данных сохраняет данные и процедуры как объекты, которые могут автоматически обновляться и совместно использоваться.
Объектно-ориентированные системы управления базами данных (ООСУБД) получают все большее распространение, поскольку могут применяться для управления различного рода мультимедийными компонентами или апплетами Java, используемыми в web-приложениях, которые обычно интегрируют фрагменты информации из разных источников. ООСУБД также полезны для хранения таких типов данных, как рекурсивные данные. (Примером могут служить сборочные узлы, являющиеся частями других узлов в приложениях из области машиностроения.) Финансовые и торговые приложения часто используют ООСУБД, поскольку им требуются модели данных, которые легко изменяются в соответствии с новыми экономическими условиями.
Х отя
объектно-ориентированные базы данных
могут сохранять более сложные виды
информации, чем реляционные СУБД, они
относительно более медленные по
сравнению с реляционными СУБД при
обработке большого числа транзакций.
Существуют некие «гибриды»:
объектно-реляционные
СУБД, которые
обладают возможностями как
объектно-ориентированной, так и
реляционной СУБД. Гибридный подход
реализуется тремя разными путями: с
помощью средств, предлагаемых
объектно-ориентированным доступом в
реляционной СУБД, использованием
объектно-ориентированных расширений
существующих СУБД или с помощью гибридного
объектно-реляционного управления базой
данными.
отя
объектно-ориентированные базы данных
могут сохранять более сложные виды
информации, чем реляционные СУБД, они
относительно более медленные по
сравнению с реляционными СУБД при
обработке большого числа транзакций.
Существуют некие «гибриды»:
объектно-реляционные
СУБД, которые
обладают возможностями как
объектно-ориентированной, так и
реляционной СУБД. Гибридный подход
реализуется тремя разными путями: с
помощью средств, предлагаемых
объектно-ориентированным доступом в
реляционной СУБД, использованием
объектно-ориентированных расширений
существующих СУБД или с помощью гибридного
объектно-реляционного управления базой
данными.
Object-oriented DBMS (объектно-ориентированная СУБД)
Подход к управлению данными, в котором предусмотрено хранение как данных, так и процедур, воздействующих на них, в виде объектов, которые можно автоматически выбирать и совместно использовать; объекты могут содержать мультимедиа.
Object-relational DBMS (объектно-реляционная СУБД) Система управления базой данных, которая объединяет возможности реляционной базы данных для хранения традиционной информации и возможности объектно-ориентированной СУБД для хранения графики и мультимедиа.
Запросы в базах данных: элементы SQL
Структурированный язык запросов (SQL) — это основной язык манипулирования данными для реляционных СУБД и основной инструмент для запросов, чтения и обновления реляционной базы данных. Существуют такие версии SQL, которые можно выполнять в среде практически любой операционной системы и на любом компьютере, так что компьютеры способны обрабатывать данные при поступлении к ним команд SQL от других компьютеров. Конечные пользователи и специалисты по информационным системам могут использовать SQL в качестве интерактивного языка запросов для доступа к данным базы, команды SQL могут также встраиваться в прикладные программы, написанные на Коболе, Си и других языках программирования.
Сейчас мы опишем наиболее важные базовые команды SQL. Предусмотрены соглашения для некоторых зарезервированных слов SQL, принимающих специальное значение, например, таких, как SELECT и FROM; все они пишутся заглавными буквами, а также для фраз SQL, которые должны быть написаны в отдельных строках.
SELECT Перечисляет столбцы из таблиц, которые пользователь хотел бы увидеть в результирующей таблице.
FROM Идентифицирует таблицы или представления, из которых следует выбирать столбцы.
WHERE Включает условия выбора специальных строк (записей) из отдельной таблицы и условия для объединения нескольких таблиц.
Команда SELECT
Команда SELECT используется для отбора специфицированных данных из реляционной таблицы. Общая форма команды SELECT, выбирающая указанные столбцы во всех строках таблицы, выглядит так:
SELECT Column_Name, Column_Name...
FROM TableJSTame.
Выбираемые столбцы перечисляются после ключевого слова SELECT, таблицы, из которых их нужно извлечь, перечисляются после ключевого слова FROM. Обратите внимание, что названия столбцов и таблиц не содержат знаков пробелов и должны быть напечатаны как одно слово или с применением символа подчеркивания и что утверждения завершаются знаком точка с запятой. Обратите внимание на рис. 7.6. Предположим, вы хотите увидеть столбцы Part_Number, Part_Description и Unit_Price для каждой детали из таблицы PART. Тогда мы пишем:
SELECT Part_Number, Part_Description, Unit_Price;
FROM PART.
На рис. 7.10 показан результат нашей работы.

Условный выбор
Оператор WHERE используется для указания отображения только определенных строк таблицы исходя из описанных условий. Предположим, например, что требуется отобразить характеристики деталей из таблицы PART, цена которых меньше $25. Для этого используется следующий программный фрагмент:
SELECT Part_Number, Part_Description, Unit _Pnce;
FROM PART;
WHERE Unit_Price < 25.00.
Запрос выдаст результат, показанный на рис. 7.11.
Объединение двух таблиц
Предположим, что требуется получить информацию о названиях, идентификационных номерах и адресах поставщиков каждой детали, размещенной в базе данных. Это можно сделать, объединяя таблицы PART и SUPPLIER, а затем извлекая требуемую информацию. Запрос должен выглядеть таким образом:
SELECT PART.Part_Number, SUPPLIER.Supplier_Number, SUPPLIER.Supplier_Name, SUPPLIER.Supplier_Address;
FROM PART, SUPPLIER;
WHERE PART.Supplier_Number = SUPPLIER.Supplier_Number.
Результат запроса будет выглядеть так, как показано на рис. 7.12. А если вы хотите увидеть названия, адреса и коды поставщиков только для деталей 137 и 152, запрос должен быть сформулирован следующим образом:
SELECT PART.Part_Number, SUPPLIER.Supplier_Number, SUPPLIER.Supplier Name,
SUPPLIER.Supplier_Address.

Пропущена стор 370 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
E ntity-relationship
diagram (диаграмма
«сущность—связь»)
ntity-relationship
diagram (диаграмма
«сущность—связь»)
Методология документирования базы данных иллюстрирует отношения между разными сущностями в базе данных.
Normalization (нормализация)
Процесс создания небольших стабильных структур данных из сложных групп данных при проектировании реляционной базы.
На рис. 7.13 представлен документ, разработанный проектировщиками данных базы, отражающий концептуальную модель данных со всеми взаимосвязями ее объектов (диаграмма «сущность—связь»). Прямоугольники представляют объекты, ромбы — взаимоотношения. Символы I или М на обоих концах ромба представляют отношения между объектами «один к одному», «один ко многим» или «многие ко многим». Рисунок 7.13 показывает, что объект ORDER может иметь больше чем одну PART, a PART может иметь только одного SUPPLIER. Это значит, что многие детали может доставлять один поставщик. Атрибуты для каждого объекта перечислены рядом с объектом, ключевое поле подчеркнуто.
Для эффективного использования реляционной базы данных комплекс сгруппированных данных должен быть рационализован с целью избежания избыточности данных и исключения затруднительных отношений «многие ко многим». Процесс создания небольших стабильных структур данных из сложных групп данных называется нормализацией. Этот процесс показан на рис. 7.14 и 7.15. В бизнесе, моделируемом здесь, заказ может иметь более чем одну деталь, но каждая


деталь поставляется только одним поставщиком. Если вы построили отношение под названием ORDER со всеми включенными здесь полями, вам надо будет повторять имя, описание и цену каждой детали заказа, а также имена и адреса каждого поставщика деталей. Такое отношение содержит то, что называется повторяющимися группами, поскольку в каждом заказе может быть много деталей и поставщиков и он действительно описывает множество объектов: детали, поставщиков, а также заказы. Более эффективный путь организации данных — разбиение ORDER на меньшие отношения, каждое из которых будет описывать отдельный объект. Если мы будем идти шаг за шагом, а затем нормализуем отношение ORDER, то получим отношения, изображенные на рис. 7.15.
Если база данных тщательно спроектирована с ясным пониманием информации, нужной для ведения бизнеса и ее дальнейшего применения, модель базы данных будет, скорее всего, в некотором нормализованном виде. Многие реально существующие базы данных не полностью нормализованы, поскольку это может быть не наиболее целесообразный путь удовлетворения требований бизнеса в отношении информации. Заметим, что реляционная база данных, изображенная на рис. 7.6, не полностью нормализована, поскольку в каждом заказе имеется более чем одна деталь. Проектировщики решили не использовать четыре отношения, показанные на рис. 7.15, поскольку большинство заказов в этом конкретном бизнесе содержит только одну деталь. Проектировщики сочли, что для этого бизнеса будет неэффективно использовать четыре разные таблицы.

Распределенные базы данных
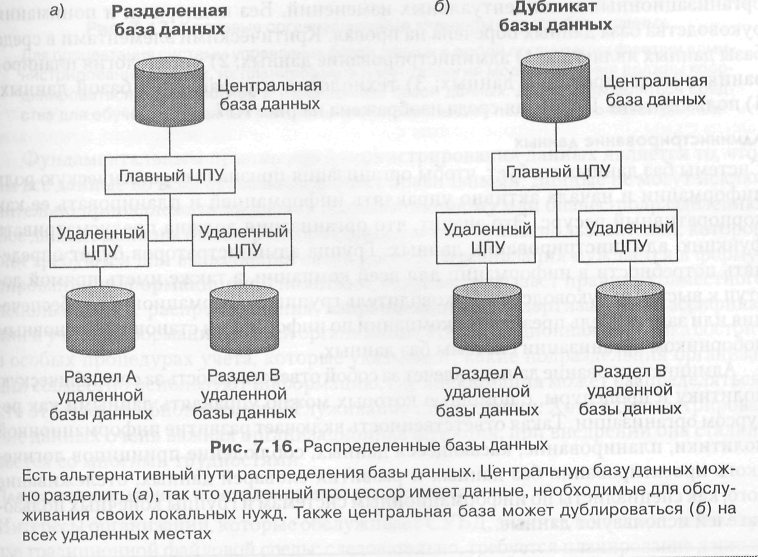
Проект базы данных также должен учитывать, как распределены данные. Информационные системы могут быть спроектированы с использованием централизованной базы данных, которая использует один центральный процессор или несколько процессоров в сети клиент—сервер. И наоборот, база данных может быть распределенной. Распределенная база данных — это такая база, которая физически хранится более чем в одном месте. Одни части базы данных физически хранятся в одном месте, а другие ее части хранятся и обрабатываются в других местах. Есть два основных способа распределения базы данных (рис. 7.16). Центральная база данных (рис. 7.16а) может быть разделена таким образом, что каждый удаленный процессор имеет необходимые данные для обслуживания локальной области. Изменения в локальных файлах могут быть урегулированы с центральной базой данных на пакетной основе, часто ночью. Другая стратегия состоит в тиражировании центральной базы данных (рис. 7.166) на все удаленные места. Например, компания Lufthansa Airlines замещает своей централизованной на мэйнфрейме базой данных тиражированные базы данных, для того чтобы делать информацию мгновенно доступной для диспетчеров полетов. Любые изменения,
D istributed
database
(распределенная база данных)
istributed
database
(распределенная база данных)
База данных, которая физически хранится в нескольких местах. Одни части или копии базы физически находятся в одном месте, а другие части или копии размещены в других местах.
сделанные в СУБД в отделении Lufthansa во Франкфурте, автоматически помещаются в базу данных в Нью-Йорке и Гонконге. Такая стратегия также требует обновления центральной базы данных во внерабочее время.
Распределенные системы уменьшают уязвимость, связанную с наличием единственного массивного центрального ядра. Они увеличивают удобства для локальных пользователей и часто могут выполняться на меньших и не таких дорогостоящих компьютерах. Распределенные системы, однако, зависят от высококачественных телекоммуникационных линий, которые сами по себе уязвимы. Более того, локальные базы могут иногда отступать от требований стандартов и определений центральных данных, они создают проблемы безопасности в связи с широким распределенным доступом к конфиденциальным данным. Проектировщики базы данных в процессе принятия решений обязаны взвешивать все эти факторы.
Требования к управлению системами баз данных
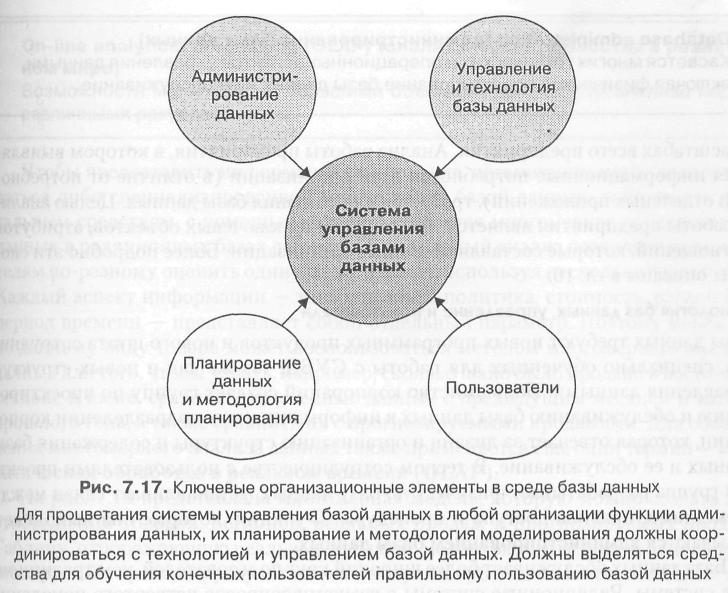
Для развития системы баз данных требуется значительно больше, чем только просто выбрать логическую модель базы данных. База данных — это скорее организационная дисциплина и метод, чем инструмент или технология. Она требует организационных и концептуальных изменений. Без поддержки и понимания руководства база данных обречена на провал. Критическими элементами в среде базы данных являются: 1) администрирование данных; 2) методология планирования и моделирования данных; 3) технология и управление базой данных; 4) пользователи. Подобная среда изображена на рис. 7.17.
Администрирование данных
Системы баз данных требует, чтобы организация признала стратегическую роль информации и начала активно управлять информацией и планировать ее как корпоративный ресурс. Это значит, что организация должна предусматривать функцию администрирования данных. Группа администраторов будет определять потребности в информации для всей компании, а также иметь прямой доступ к высшему руководству. Руководитель группы информационного обеспечения или заместитель президента компании по информации становится основным поборником организации системы баз данных.
А дминистрирование
данных влечет за собой ответственность
за специфическую политику и процедуры,
с помощью которых можно управлять
данными как ресурсом организации.
Такая ответственность включает развитие
информационной политики, планирование,
касающееся данных, соблюдение принципов
логического проектирования баз
данных и развития словарей данных,
отслеживание того, как специалисты по
информационным системам и группы
конечных пользователей используют
данные.
дминистрирование
данных влечет за собой ответственность
за специфическую политику и процедуры,
с помощью которых можно управлять
данными как ресурсом организации.
Такая ответственность включает развитие
информационной политики, планирование,
касающееся данных, соблюдение принципов
логического проектирования баз
данных и развития словарей данных,
отслеживание того, как специалисты по
информационным системам и группы
конечных пользователей используют
данные.
Data administration (администрирование данных)
Специальная организационная функция по управлению ресурсами данных организации, выражающаяся в информационной политике, планировании данных, обслуживании словарей данных и стандартов качества данных..
Фундаментальным принципом администрирования данных является то, чтобы все данные во всей организации были правильными. Данные не могут исключительно принадлежать никакому организационному или бизнес-подразделению. Все данные должны быть в распоряжении любой группы пользователей, которой они требуются для выполнения своей работы. Организация нуждается в формулировании информационной политики, которая указывает правила совместного использования, распространения, запрашивания, стандартизации, классификации и учета информации во всей организации. Информационная политика состоит в особых процедурах учета, которые указывают, какие подразделения организации совместно используют информацию, где информация может распределяться, кто отвечает за обновление и обслуживание информации. Хотя администрирование данных очень важная организационная функция, при внедрении она сталкивается со многими трудностями.
Планирование данных и методология моделирования
И нтересы
организации, которые обслуживает СУБД,
значительно шире, чем в случае
традиционной файловой среды; следовательно,
требуется планирование данных
нтересы
организации, которые обслуживает СУБД,
значительно шире, чем в случае
традиционной файловой среды; следовательно,
требуется планирование данных