

Статистика теневой экономики в зарубежных странах
Каменский А.Н. (МГУ)
Оценка нелегальной иммиграции
(Использование корреляционного анализа для оценки численности
нелегальных иммигрантов в США)
Исследовательские гипотезы
Одним из наиболее беспокойных вопросов в теории и практике международных миграций является проблема нелегальной иммиграции. Основным камнем преткновения в деле становления регулирующих механизмов нелегальной эмиграции является сложность оценки численности нелегальных иммигрантов на той или иной территории. Мы решили рассмотреть эту проблему на примере США - страны, куда на протяжении последних полутора веков устремляются крупные миграционные потоки со всех концов земного шара.
В Соединенных Штатах Америки существует не только отлаженная система учета международных миграций, но и различные системы оценок численности нелегальных иммигрантов, прибывающих в страну. В Статистическом ежегоднике, который издает Бюро переписи Департамента торговли, представлены две системы оценки численности нелегальных иммигрантов, расходящиеся между собой. Одна из них делается Службой иммиграции и натурализации США, то есть опытными чиновниками, а вторая - оценка численности нелегальных иммигрантов по результатам переписи, которой, как правило, руководят научные работники. Вторая система включает максимальную и минимальную оценки, которые расходятся между собой на 30-50% по разным штатам и в целом по США. Мы решили, используя эти две системы данных, выявить и проанализировать зависимости численности нелегальных иммигрантов по этим оценкам с другими сопутствующими статистически определенными показателями социально-трудового характера.
Оговоримся сразу, что несмотря на расхождения между минимальной и максимальной оценками численности нелегальных иммигрантов по результатам переписи и оценкой, представленной Службой иммиграции и натурализации США, мы считаем эти данные достаточно надежными и выражающими параметры явления. Оценка, данная Службой иммиграции и натурализации США, близка к вычисленной нами средней арифметической между максимальной и минимальной оценками, полученными по результатам переписи. Таким образом, можно сделать вывод, что все три оценки как-то подпирают друг друга и дают довольно точное соотношение численности нелегальных иммигрантов по штатам США1.
Мы решили рассмотреть несколько гипотез зависимости нелегальной иммиграции от статистически определенных явлений.
Первая гипотеза.
Основным центром притяжения нелегальных иммигрантов являются легальные иммигранты, создающие благоприятную почву для приглашения, размещения, материальной поддержки и поиска возможных источников дохода будущего нелегального иммигранта. Принцип "легал тянет нелегала". Для того, чтобы проверить эту версию, мы сравним численность иностранно - рожденных с численностью нелегальных иммигрантов.
Вторая гипотеза.
Нелегалы стремятся туда, где больше численность населения, так как в крупных городах легче прожить незаметно, чем в малонаселенной местности, и видимо, легче найти работу. Принцип "В толпе легче спрятать и выжить". Для того, чтобы проверить эту гипотезу мы должны исследовать зависимость численности нелегальных иммигрантов от численности населения для различных штатов.
Третья гипотеза.
Наибольшая часть нелегальных иммигрантов скапливается в пограничных штатах и штатах, где расположены крупные въездные пункты в США, принимающие большое количество иммигрантов. Для этого мы должны точно определить и выделить "въездные штаты" и определить их отклонения от средней тенденции.
В данном материале мы попытались проверить только первую и вторую гипотезу. В качестве инструмента проверки гипотез воспользуемся корреляционным анализом. При проверке первой гипотезы мы подробно опишем весь механизм анализа. Итак, проверим первую гипотезу.
Проверка первой гипотезы
Мы
предполагаем, что численность нелегальных
иммигрантов и численность иностранно-рожденных
связаны между собой. Обозначим через
![]() - численность иностранно-рожденных в
сотнях тысяч человек, а через
- численность иностранно-рожденных в
сотнях тысяч человек, а через![]() - численность нелегальных иммигрантов
по оценке Службы иммиграции и натурализации,
также в сотнях тысяч человек. Будем
считать, что между явлениями существует
линейная зависимость
- численность нелегальных иммигрантов
по оценке Службы иммиграции и натурализации,
также в сотнях тысяч человек. Будем
считать, что между явлениями существует
линейная зависимость![]() .
Вычислим коэффициент корреляции:
.
Вычислим коэффициент корреляции:
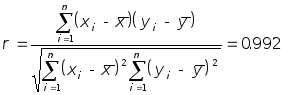 ,
где
,
где
![]() и
и
![]() -выборочные средние. Теперь проверим
статистическую значимость коэффициента
корреляции. Поскольку коэффициент
корреляции является случайной величиной
(как функция случайных величин х и у),
то случайной величиной является любая
его функция, и нам нужно указать функцию,
имеющую одно из известных распределений,
удобных для анализа. Такой функцией
является
-выборочные средние. Теперь проверим
статистическую значимость коэффициента
корреляции. Поскольку коэффициент
корреляции является случайной величиной
(как функция случайных величин х и у),
то случайной величиной является любая
его функция, и нам нужно указать функцию,
имеющую одно из известных распределений,
удобных для анализа. Такой функцией
является
![]() статистика,
рассчитываемая по формуле
статистика,
рассчитываемая по формуле![]() ,
где
,
где![]() - коэффициент корреляции,
- коэффициент корреляции,![]() -
количество наблюдений. Данная функция
имеет распределение Стьюдента с
-
количество наблюдений. Данная функция
имеет распределение Стьюдента с![]() степенями свободы. Число степеней
свободы меньше числа наблюдения на 2,
так как в формулу расчета коэффициента
корреляции входят
степенями свободы. Число степеней
свободы меньше числа наблюдения на 2,
так как в формулу расчета коэффициента
корреляции входят![]() и
и![]() - выборочные средние значения. Мы будем
проверять нулевую гипотезу
- выборочные средние значения. Мы будем
проверять нулевую гипотезу![]() - гипотезу о равентстве нулю коэффициента
корреляции в генеральной совокупности.
Альтернативная гипотеза
- гипотезу о равентстве нулю коэффициента
корреляции в генеральной совокупности.
Альтернативная гипотеза![]() - коэффициент корреляции не равен нулю.
Затем сраниваем вычисленное значение
- коэффициент корреляции не равен нулю.
Затем сраниваем вычисленное значение![]() статистики с критическим, определенным
по таблицам распределния Стьюдента, и
мы принимаем нулевую гипотезу, если
статистики с критическим, определенным
по таблицам распределния Стьюдента, и
мы принимаем нулевую гипотезу, если![]() ,
или отвергаем ее, если
,
или отвергаем ее, если![]() с заданным уровнем значимости
с заданным уровнем значимости![]() .
Уровень значимости характеризует
вероятность того, что будет отвергнута
гипотеза, которая на самом деле является
верной. В данном случае
.
Уровень значимости характеризует
вероятность того, что будет отвергнута
гипотеза, которая на самом деле является
верной. В данном случае![]() .
По таблице распределения Стьюдента
находим, что при уровне значимости
.
По таблице распределения Стьюдента
находим, что при уровне значимости![]() ,
,![]() .
Так как
.
Так как![]() ,
мы отвергаем нулевую гипотезу и можем
сделать вывод о существовании статистически
значимой линейной связи между численностью
нелегальных иммигрантов и иностранно-рожденных
граждан. Теперь рассчитаем параметры
прямой
,
мы отвергаем нулевую гипотезу и можем
сделать вывод о существовании статистически
значимой линейной связи между численностью
нелегальных иммигрантов и иностранно-рожденных
граждан. Теперь рассчитаем параметры
прямой
![]() ,
выражающей данную зависимость. Параметры
прямой подбираются из условия, что сумма
квадратов отклонений
,
выражающей данную зависимость. Параметры
прямой подбираются из условия, что сумма
квадратов отклонений
![]() была минимальной, так называемый метод
наименьших квадратов.
была минимальной, так называемый метод
наименьших квадратов.
![]()
![]() .
.
Параметры такой прямой рассчитываются по следующим формулам:
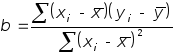
![]() .
В нашем случае
.
В нашем случае
![]() и
и
![]() .
Получаем прямую
.
Получаем прямую
![]() .
Проанализируем статистическую значимость
параметров регрессии. Найдем отклонения
переменной
.
Проанализируем статистическую значимость
параметров регрессии. Найдем отклонения
переменной![]() от оцененной линии регрессии
от оцененной линии регрессии![]() .
Рассчитаем разброс коэффициентов
.
Рассчитаем разброс коэффициентов
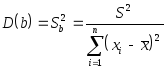 ,
,![]()
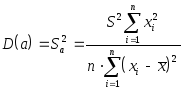 ,
где
,
где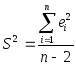
![]() -
мера разброса зависимой переменной
вокруг линии регрессии (необъясненная
регрессия);
-
мера разброса зависимой переменной
вокруг линии регрессии (необъясненная
регрессия);![]() и
и![]() -
стандартные отклонения (ошибки) случайных
величин
-
стандартные отклонения (ошибки) случайных
величин![]() и
и![]() .
В нашем случае
.
В нашем случае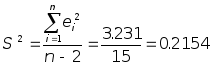 ,
,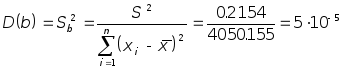 ,
,
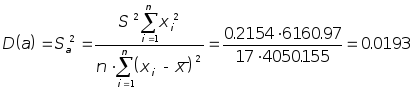 .
Значимость оцененных коэффициентов
регресии
.
Значимость оцененных коэффициентов
регресии
![]() и
и
![]() проверяется с помощью анализа отношения
модуля каждого коэффициента к своему
стандартному отклонению
проверяется с помощью анализа отношения
модуля каждого коэффициента к своему
стандартному отклонению![]() и
и![]() .
Эти величины в случае выполнения исходных
посылок модели имеют
.
Эти величины в случае выполнения исходных
посылок модели имеют![]() распределение
Стьюдента с
распределение
Стьюдента с![]() степенями свободы и называются
степенями свободы и называются![]() статистиками,
соответствующего коэффициента:
статистиками,
соответствующего коэффициента:
![]()
![]()
Для
каждой
![]() статистики
проверяется нулевая гипотеза, то есть
гипотеза о равенстве ее нулю. Очевидно,
статистики
проверяется нулевая гипотеза, то есть
гипотеза о равенстве ее нулю. Очевидно,![]() равнозначно
равенству нулю соответствующего
коэффициента, поскольку
равнозначно
равенству нулю соответствующего
коэффициента, поскольку![]() пропорционально
соответствующему коэффициенту. Зададим
уровень значимости 0.05 при альтернативных
гипотезах, то есть
пропорционально
соответствующему коэффициенту. Зададим
уровень значимости 0.05 при альтернативных
гипотезах, то есть![]() и
и![]() ,
и критические значения для такого уровня
значимости составят для
,
и критические значения для такого уровня
значимости составят для![]() :
:![]() ,
и для
,
и для![]() :
:![]() . в нашем случае и для
. в нашем случае и для![]() и для
и для![]() ,
выполняется условие
,
выполняется условие![]() ,
и мы отвергаем нулевую гипотезу. Кроме
того, в дальнейшем мы будем иметь в виду,
что при оценке значимости коэффициентов
можно пользоваться следующим грубым
правилом. Если стандартная ошибка
коэффициента больше его модуля
,
и мы отвергаем нулевую гипотезу. Кроме
того, в дальнейшем мы будем иметь в виду,
что при оценке значимости коэффициентов
можно пользоваться следующим грубым
правилом. Если стандартная ошибка
коэффициента больше его модуля![]() ,
то он не может быть признан значимым.
Если стандартная ошибка коэффициента
меньше модуля коэффициента, но больше
его половины
,
то он не может быть признан значимым.
Если стандартная ошибка коэффициента
меньше модуля коэффициента, но больше
его половины![]() ,
то сделанная оценка может рассматриваться
как более или менее значимая. Значение
,
то сделанная оценка может рассматриваться
как более или менее значимая. Значение![]() от
2 до 3 свидетельствует о весьма значимой
связи, и
от
2 до 3 свидетельствует о весьма значимой
связи, и![]() есть практически стопроцентное
свидельство ее наличия. В нашем случае
статистическая значимость обоих
коэффициентов весьма высока. Однако,
на этом анализ качества регресии не
заканчивается. Для анализа общего
качества оцененной линейной регрессии
используют коэффициент детерминации
есть практически стопроцентное
свидельство ее наличия. В нашем случае
статистическая значимость обоих
коэффициентов весьма высока. Однако,
на этом анализ качества регресии не
заканчивается. Для анализа общего
качества оцененной линейной регрессии
используют коэффициент детерминации![]() ,
рассчитываемый по формуле
,
рассчитываемый по формуле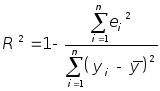 .
Коэффициент детерминации характеризует
долю вариации (разброса) зависимой
переменной, объясненной с помощью
данного уравнения. Метод наименьших
квадратов позволяет найти прямую, для
которой сумма
.
Коэффициент детерминации характеризует
долю вариации (разброса) зависимой
переменной, объясненной с помощью
данного уравнения. Метод наименьших
квадратов позволяет найти прямую, для
которой сумма![]() минимальна, а линия
минимальна, а линия![]() представляет собой одну из возможных
линий, для которых выполняются условия
представляет собой одну из возможных
линий, для которых выполняются условия![]() ,
а коэффициент детерминации
,
а коэффициент детерминации![]() является мерой, позволяющей определить,
в какой степени найденная регрессионная
прямая дает лучший результат для
объяснения поведения зависимой переменной
является мерой, позволяющей определить,
в какой степени найденная регрессионная
прямая дает лучший результат для
объяснения поведения зависимой переменной![]() ,
чем просто горизонтальная прямая
,
чем просто горизонтальная прямая![]() .
Если существует статистически значимая
линейная связь величин
.
Если существует статистически значимая
линейная связь величин![]() и
и![]() ,
то коэффициент детерминации
,
то коэффициент детерминации![]() близок к единице. В нашем случае
близок к единице. В нашем случае![]() ,
то есть наше уравение объясняет 98,4%
зависимости. Для определения статистической
значимости коэффициента детерминации
,
то есть наше уравение объясняет 98,4%
зависимости. Для определения статистической
значимости коэффициента детерминации![]() проверяется нулевая гипотеза для
проверяется нулевая гипотеза для![]() статистики
(статистики Фишера), рассчитываемой по
формуле:
статистики
(статистики Фишера), рассчитываемой по
формуле:![]() . Проверяется гипотеза, что коэффициент
детерминации равен нулю. Если он
действительно равен нулю, то уравнение
регресии имеет вид
. Проверяется гипотеза, что коэффициент
детерминации равен нулю. Если он
действительно равен нулю, то уравнение
регресии имеет вид![]() ,
а коэффициент детерминации
,
а коэффициент детерминации![]() и
и![]() статистика
Фишера также равны нулю. В нашем случае
статистика
Фишера также равны нулю. В нашем случае![]() .
Статистика Фишера настолько велика,
что нет необходимости прибегать к
таблицам, чтобы сделать вывод о
статистической значимости коэффициента
детерминации. Однако, даже близкое к
единице значение коэффициента
детерминации
.
Статистика Фишера настолько велика,
что нет необходимости прибегать к
таблицам, чтобы сделать вывод о
статистической значимости коэффициента
детерминации. Однако, даже близкое к
единице значение коэффициента
детерминации![]() еще не доказывает высокое качество
уравнения регрессии, возможно, величины
имеют некий временной тренд. Поэтому
перейдем к заключительному этапу
проверки качества регресии - проверке
некоторых важных свойств, выполнение
которых предполагалось при оценивании
уравнения регрессии. Одним из основных
предполагаемых свойств отклонений
еще не доказывает высокое качество
уравнения регрессии, возможно, величины
имеют некий временной тренд. Поэтому
перейдем к заключительному этапу
проверки качества регресии - проверке
некоторых важных свойств, выполнение
которых предполагалось при оценивании
уравнения регрессии. Одним из основных
предполагаемых свойств отклонений![]() значений
значений![]() от регрессионной формулы
от регрессионной формулы![]() является их статистическая независимость
между собой. Проверим некоррелированность
соседних величин
является их статистическая независимость
между собой. Проверим некоррелированность
соседних величин![]() .
Соседними считаются соседние по
возрастанию переменной
.
Соседними считаются соседние по
возрастанию переменной![]() .
Для этих величин рассчитывается
коэффициент корреляции, так называемый
коэффициент автокорреляции первого
порядка
.
Для этих величин рассчитывается
коэффициент корреляции, так называемый
коэффициент автокорреляции первого
порядка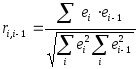 или cвязанную с ним статистику
Дарбина-Уотсона
или cвязанную с ним статистику
Дарбина-Уотсона![]() 2,
рассчитываемую по формуле
2,
рассчитываемую по формуле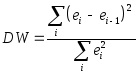 .
Коэффициент автокорреляции и статистика
Дарбина-Уотсона связаны соотношением
.
Коэффициент автокорреляции и статистика
Дарбина-Уотсона связаны соотношением![]() .
Поскольку коэффициент автокорреляции
изменяется в пределах от -1 до 1, то
.
Поскольку коэффициент автокорреляции
изменяется в пределах от -1 до 1, то![]() варьируется от 0 до 4. Причем когда
варьируется от 0 до 4. Причем когда![]() близок к нулю, то есть статистика
близок к нулю, то есть статистика![]() близка
к 2, тогда мы считаем отклонения от линии
регрессии случайными и независимыми
между собой. Это значит, что линейная
функция, вероятно, отражает реальную
взаимосвязь, и скорее всего, не осталось
существенных неучтенных факторов,
влиящих на зависимую переменную, и
какая-то другая нелинейная формула не
превосходит по статистическим
характеристикам линейную. Кроме того,
часть дисперсии, оставшаяся необъясненной,
порождается множеством различных
факторов и может быть описана как
случайная нормальная ошибка.
близка
к 2, тогда мы считаем отклонения от линии
регрессии случайными и независимыми
между собой. Это значит, что линейная
функция, вероятно, отражает реальную
взаимосвязь, и скорее всего, не осталось
существенных неучтенных факторов,
влиящих на зависимую переменную, и
какая-то другая нелинейная формула не
превосходит по статистическим
характеристикам линейную. Кроме того,
часть дисперсии, оставшаяся необъясненной,
порождается множеством различных
факторов и может быть описана как
случайная нормальная ошибка.
Итак,
статистика Дарбина-Уотсона применяется
для проверки гипотезы об отсутствии
автокорреляции остатков
![]() первого порядка (нулевая гипотеза). Для
этого по таблицам находятся при заданном
уровне значимости, числе наблюдений и
независимых переменных, доверительные
интервалы, в пределах которых нулевая
гипотеза принимается, отвергается, или
не может быть ни принята, ни отвергнута.
Для статистики Дарбина-Уотсона в таблице
даны два критических значения
первого порядка (нулевая гипотеза). Для
этого по таблицам находятся при заданном
уровне значимости, числе наблюдений и
независимых переменных, доверительные
интервалы, в пределах которых нулевая
гипотеза принимается, отвергается, или
не может быть ни принята, ни отвергнута.
Для статистики Дарбина-Уотсона в таблице
даны два критических значения![]() и
и![]() ,
которые меньше двух. Нижнее
,
которые меньше двух. Нижнее![]() определяет границу признания наличия
автокорреляции, то есть в пределах
определяет границу признания наличия
автокорреляции, то есть в пределах![]() или
или![]() мы принимает нулевую гипотезу, то есть
делает вывод о существовании автокорреляции
остатков. Верхнее
мы принимает нулевую гипотезу, то есть
делает вывод о существовании автокорреляции
остатков. Верхнее![]() - граница отвержения нулевой гипотезы,
то есть в пределах
- граница отвержения нулевой гипотезы,
то есть в пределах![]() мы отвергаем нулевую гипотезу, делаем
вывод об отсутствии автокорреляции
остатков. И в пределах
мы отвергаем нулевую гипотезу, делаем
вывод об отсутствии автокорреляции
остатков. И в пределах![]() или
или![]() мы не можем ни принять нулевую гипотезу,
ни отвергнуть ее.
мы не можем ни принять нулевую гипотезу,
ни отвергнуть ее.
В нашем
случае
![]() .
По таблицам найдем для оценки линейной
регрессии по 17 наблюдениям с уровнем
значимости 5% критические значения
составляют
.
По таблицам найдем для оценки линейной
регрессии по 17 наблюдениям с уровнем
значимости 5% критические значения
составляют![]() и
и![]() .
И поскольку в нашем случае
.
И поскольку в нашем случае![]() ,
мы отвергаем нулевую гипотезу и делаем
вывод о том, что отклонения от линии
регрессии является случайными и наша
формула
,
мы отвергаем нулевую гипотезу и делаем
вывод о том, что отклонения от линии
регрессии является случайными и наша
формула![]() ,
полученная для описания зависимости
численности нелегальных по оценки
Службы натурализации и иммиграции США
от численности иностранно - рожденных
признается удовлетворительной.
,
полученная для описания зависимости
численности нелегальных по оценки
Службы натурализации и иммиграции США
от численности иностранно - рожденных
признается удовлетворительной.
Проведя соответствующие вычисления для прочих оценок, полученных в результате переписи получаем
для минимальной оценки по переписи
![]() -
уравнение регрессии. Коэффициент
корреляции
-
уравнение регрессии. Коэффициент
корреляции![]() ,
а
,
а![]() статистика
для него
статистика
для него![]() ,
для вывода о статистической значимости
коэффициента корреляции нет нужды
прибегать к таблицам. Стандартные ошибки
параметров регрессии
,
для вывода о статистической значимости
коэффициента корреляции нет нужды
прибегать к таблицам. Стандартные ошибки
параметров регрессии![]() и
и![]() и соответствующие им
и соответствующие им![]() статистики
статистики![]() и
и![]() показывают
высокую статистическую значимость
параметров регрессии. Коэффициент
детерминации
показывают
высокую статистическую значимость
параметров регрессии. Коэффициент
детерминации![]() ,
близок к единице. Статистика Фишера
,
близок к единице. Статистика Фишера![]() cущественно
больше нуля, а статистика Дарбина -
Уотсона
cущественно
больше нуля, а статистика Дарбина -
Уотсона![]() попадает
в интервал отвержения нулевой гипотезы
попадает
в интервал отвержения нулевой гипотезы![]() ,
что позволяет сделать вывод об отсутсвии
автокорреляции остатков.
,
что позволяет сделать вывод об отсутсвии
автокорреляции остатков.
Аналогично, для максимальной оценки по переписи
![]() - уравнение регрессии. В данном случае
коэффициент корреляции
- уравнение регрессии. В данном случае
коэффициент корреляции![]() ,
а
,
а![]() статистика
для него
статистика
для него![]() ,
для вывода о статистической значимости
коэффициента корреляции нет нужды
прибегать к таблицам. Стандартные ошибки
параметров регрессии
,
для вывода о статистической значимости
коэффициента корреляции нет нужды
прибегать к таблицам. Стандартные ошибки
параметров регрессии![]() и
и![]() и соответствующие им
и соответствующие им![]() статистики
статистики![]() и
и![]() показывают
также высокую статистическую значимость
параметров регрессии. Коэффициент
детерминации
показывают
также высокую статистическую значимость
параметров регрессии. Коэффициент
детерминации![]() ,
близок к единице. Статистика Фишера
,
близок к единице. Статистика Фишера![]() cущественно больше нуля, а статистика
Дарбина - Уотсона
cущественно больше нуля, а статистика
Дарбина - Уотсона![]() попадает в интервал отвержения нулевой
гипотезы
попадает в интервал отвержения нулевой
гипотезы![]() ,
что позволяет сделать вывод об отсутствии
автокорреляции остатков.
,
что позволяет сделать вывод об отсутствии
автокорреляции остатков.
Статистистические
параметры для уравнений, полученных
при проверке первой гипотезы, позволяют
сделать вывод о том, что оценка Службы
натурализации и иммиграции США является
наилучшей и мы в дальнейшем будем
пользоваться уравнением регрессии,
полученных на ее основе
![]() .
Например, мы можем по данному уравнению,
зная численность иностранно-рожденных
на некой территории, рассчитать
численность нелегальных иммигрантов.
Пусть на некой территории проживает
2000 иностранно - рожденных, тогда с высокой
достоверностью мы можем оценить
количество нелегальных имигрантов на
этой территории в 61 человек. (
.
Например, мы можем по данному уравнению,
зная численность иностранно-рожденных
на некой территории, рассчитать
численность нелегальных иммигрантов.
Пусть на некой территории проживает
2000 иностранно - рожденных, тогда с высокой
достоверностью мы можем оценить
количество нелегальных имигрантов на
этой территории в 61 человек. (![]() ).
Расчеты проводятся в сотнях тысяч
человек.
).
Расчеты проводятся в сотнях тысяч
человек.
Теперь по той же схеме проведем проверку второй гипотезы.
Проверка второй гипотезы
Теперь
![]() численность
населения в штате в млн человек, а
численность
населения в штате в млн человек, а![]() численность
нелегальных иммигрантов по оценке
Службы натурализации и иммиграции, в
сотнях тысяч человек. Промежуточные
вычисления приводятся в таблице 2.2 в
приложении. Получаем следующее линейное
уравнение, связывающее переменные
численность
нелегальных иммигрантов по оценке
Службы натурализации и иммиграции, в
сотнях тысяч человек. Промежуточные
вычисления приводятся в таблице 2.2 в
приложении. Получаем следующее линейное
уравнение, связывающее переменные![]() - уравнение регрессии. Отметим, что
коэффициент корреляции достаточно
высок
- уравнение регрессии. Отметим, что
коэффициент корреляции достаточно
высок![]() ,
а
,
а![]() статистика
для него
статистика
для него![]() .
Необъясненная дисперсия составляет
.
Необъясненная дисперсия составляет![]() ,
стандартные ошибки параметров регрессии
,
стандартные ошибки параметров регрессии![]()
![]() и
и![]()
![]() ,
соответствующие им
,
соответствующие им![]() статистики
даны в скобках. Коэффициент регрессии
статистики
даны в скобках. Коэффициент регрессии![]() нельзя считать значимым. Кроме того,
хотя коэффициент детерминации
нельзя считать значимым. Кроме того,
хотя коэффициент детерминации![]() достаточно близок к единице, а статистика
Фишера
достаточно близок к единице, а статистика
Фишера![]() ,
но статистика Дарбина - Уотсона
,
но статистика Дарбина - Уотсона![]() попадает в интервал, когда нулевую
гипотезу мы не можем ни принять ни
отвергнуть, поскольку
попадает в интервал, когда нулевую
гипотезу мы не можем ни принять ни
отвергнуть, поскольку![]() .
Итак, необъясненная регрессия составляет
16,2%, нулевую гипотезу об отсутствии
автокорреляции остатков мы не можем ни
принять ни отвергнуть, кроме того
свободный член
.
Итак, необъясненная регрессия составляет
16,2%, нулевую гипотезу об отсутствии
автокорреляции остатков мы не можем ни
принять ни отвергнуть, кроме того
свободный член![]() не является статистически значимым,
все это позволяет сделать вывод, что
зависимость между данными переменными
будет скорее всего нелинейной. Посмотрев
на графики проверки второй гипотезы
(см. приложение) мы можем предположить
существование параболической зависимости.
Итак, попытаемся улучшить уравнение.
При этом мы надеемся избавиться от
автокорреляции остатков, то есть получить
более близкую к двум статистику Дарбина
- Уотсона и, возможно, увеличить долю
объясненной дисперсии для данной
зависимости, то есть
не является статистически значимым,
все это позволяет сделать вывод, что
зависимость между данными переменными
будет скорее всего нелинейной. Посмотрев
на графики проверки второй гипотезы
(см. приложение) мы можем предположить
существование параболической зависимости.
Итак, попытаемся улучшить уравнение.
При этом мы надеемся избавиться от
автокорреляции остатков, то есть получить
более близкую к двум статистику Дарбина
- Уотсона и, возможно, увеличить долю
объясненной дисперсии для данной
зависимости, то есть![]() .
Искомая зависимость будет параболической,
описывается уравнением
.
Искомая зависимость будет параболической,
описывается уравнением![]() .
Используя метод наименьших квадратов,
то есть подбирая коэффициенты таким
образом, чтобы сумма квадратов отклонений
была минимальной, получаем формулу
расчета вектора коэффициента в векторно
- матричной форме
.
Используя метод наименьших квадратов,
то есть подбирая коэффициенты таким
образом, чтобы сумма квадратов отклонений
была минимальной, получаем формулу
расчета вектора коэффициента в векторно
- матричной форме![]() ,
где
,
где![]() - транспонированная матрица - матрица,
строки и столбцы которой меняются
местами, а
- транспонированная матрица - матрица,
строки и столбцы которой меняются
местами, а![]() - матрица, обратная к
- матрица, обратная к![]() - такая, которая при умножении на матрицу
- такая, которая при умножении на матрицу![]() дает единичную матрицу. В нашем случае
имеем
дает единичную матрицу. В нашем случае
имеем![]() - матрица наблюдений вектора значений
независимой переменной
- матрица наблюдений вектора значений
независимой переменной![]() :
: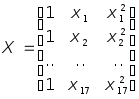 . Матрица
. Матрица![]() в нашем случае имеет размерность 17 на
3,
в нашем случае имеет размерность 17 на
3,![]() вектор - столбец зависимой переменной
имеет размерность 17 на 1, и столбец
вектор - столбец зависимой переменной
имеет размерность 17 на 1, и столбец![]() - столбец коэффициентов размерности 3
на 1 и
- столбец коэффициентов размерности 3
на 1 и![]() - вектор столбец отклонений. Все
промежуточные вычисления даны в таблице
2.4 в приложении и получаем параметры
регрессии
- вектор столбец отклонений. Все
промежуточные вычисления даны в таблице
2.4 в приложении и получаем параметры
регрессии![]() .
Рассчитав дисперсии всех параметров
регрессии и соответствующие им
.
Рассчитав дисперсии всех параметров
регрессии и соответствующие им![]() статистики, получаем
статистики, получаем![]()
![]() , поскольку
, поскольку![]() ,
мы не можем отвергнуть нулевую гипотезу
о равентстве нулю коэффициента
,
мы не можем отвергнуть нулевую гипотезу
о равентстве нулю коэффициента![]() и принимаем
и принимаем![]() .
Но статистическая значимость двух
других коэффициентов весьма высока
.
Но статистическая значимость двух
других коэффициентов весьма высока![]()
![]() ,
,![]()
![]() .
И наше уравнение регрессии примет вид
.
И наше уравнение регрессии примет вид![]() ,
где у - численность нелегальных иммигрантов
в сотнях тысяч человек и х - численность
населения штата в млн человек. Данная
кривая проходит через начало координат.
Заметим, что ненулевой свободный член
не имеет содержательной интерпретации,
поскольку численность нелегальных
иммигрантов входит в общую численность
населения. Коэффициент детерминации
,
где у - численность нелегальных иммигрантов
в сотнях тысяч человек и х - численность
населения штата в млн человек. Данная
кривая проходит через начало координат.
Заметим, что ненулевой свободный член
не имеет содержательной интерпретации,
поскольку численность нелегальных
иммигрантов входит в общую численность
населения. Коэффициент детерминации![]() ,
значит данная нелинейная зависимость
объясняет уже 97%, а не 84,2%, как линейная.
Статистика Фишера
,
значит данная нелинейная зависимость
объясняет уже 97%, а не 84,2%, как линейная.
Статистика Фишера![]() существенно больше нуля и статистика
Дарбина-Уотсона
существенно больше нуля и статистика
Дарбина-Уотсона![]() попадает в интервал отвержения нулевой
гипотезы, то есть
попадает в интервал отвержения нулевой
гипотезы, то есть![]() и можно сделать вывод, что при данной
нелинейной зависимости удалось избавиться
от автокорреляции остатков.
и можно сделать вывод, что при данной
нелинейной зависимости удалось избавиться
от автокорреляции остатков.
Для
остальных оценок не будет приводить
подробные расчеты, все выше сказанное,
включая принятие нулевой гипотезы для
коэффициента
![]() ,
подтверждение статистической значимости
двух других коэффициентов, близкое к
единице значение коэффициента
детерминации, существенно превосходящее
ноль значение статистики Фишера и
значение статистики Дарбина - Уотсона,
попадающее в интервал отвержения нулевой
гипотезы, верно, и дадим лишь итоговые
уравнения:
,
подтверждение статистической значимости
двух других коэффициентов, близкое к
единице значение коэффициента
детерминации, существенно превосходящее
ноль значение статистики Фишера и
значение статистики Дарбина - Уотсона,
попадающее в интервал отвержения нулевой
гипотезы, верно, и дадим лишь итоговые
уравнения:
по минимальной оценке по результатам переписи
![]()
по максимальной оценке по результатам переписи
![]()
по среднему арифметическому минимальной и максимальной оценок по результатам переписи
![]()
Далее, необходимо отметить, что по проведенному статистическому анализу видно, что оценки по переписи лучше отражают зависимость численности нелегальных иммигрантов от численности населения, тогда как оценка Службы натурализации и иммиграции позволяет точнее выявить зависимость численности нелегальных иммигрантов от численности иностранно-рожденных, что согласуется с нашим предположением, что эти оценки дополняют и подпирают друг друга.
Проверим
как от численности иностранно-рожденных
(в сотнях тысяч человек) зависит общее
населения штата (в млн человек): такая
зависимость есть и ее легко можно
подсчитать
![]() .
Вычисления приведены в таблице 3.
.
Вычисления приведены в таблице 3.
Итак, по результатам проведенного исследования можно сделать следующие выводы.
Выводы
1. Численность нелегальных иммигрантов может быть определена не только при помощи оценок экспертов, но и с помощью использования экономико-математических методов, в частности выявлена корреляция численности нелегальных эмигрантов от публикуемых статистических данных.
2. Для решения проблемы оценки численности нелегальных иммигрантов мы полностью рассмотрели две гипотезы. Первая гипотеза: нелегалы скапливаются в районах проживания легально проживающих и занятых иностранцев, что является показателем нескольких моментов. Во-первых, легальные иностранные общины имеют тенденцию к расширению своей численности за счет притока "нелегалов". Во-вторых, "легалы" создают "питательную среду" для "нелегалов", обеспечивая им размещение, проживание и доход на первое время. В-третьих, сама нелегальная община сама становится "питательной средой" для дополнительного притока новой волны нелегальной иммиграции. Вторая гипотеза: мы предположили, что существует тенденция притяжения большей нелегальной иммиграции просто в наиболее населенные штаты США, по принципу "в большей толпе легче спрятаться и выжить".
3. Нами обнаружена прямая зависимость численности нелегальных иммигрантов от численности легально проживающих в стране иностранцев (иностранно-рожденных граждан). Кроме того, численность нелегальных иммигрантов также зависит от общей численности населения штата. Нами найдены формулы этих зависимостей. Оба наши предположения (первая гипотеза и вторая гипотеза) оказались верными на взятый нами момент времени.
4. Проверка статистической надежности данной зависимости показала, что надежность весьма высока, то есть не может быть случайной, и наши формулы верны на 95%.
5. По
результатам проведенного исследования
можно рекомендовать использовать
формулу линейной зависимости
![]() для достаточно достоверной оценки
численности нелегальных эмигрантов
(у) на той или иной территории, зная
численность иностранно - рожденных (х)
на этой территории.
для достаточно достоверной оценки
численности нелегальных эмигрантов
(у) на той или иной территории, зная
численность иностранно - рожденных (х)
на этой территории.
6. По результатам проверки первой гипотезы обнаружено наличие ненулевого свободного члена, то есть только достигнув некого определенного размера (в нашем случае 1700 человек) когда община легальных иммигрантов начинает притягивать нелегальных иммигрантов.
7. При
определении численности нелегальных
иммигрантов от численности населения
данной территории (штата) выявлена
параболическая зависимость, ее формула
![]() ,
где х - численность населения штата в
млн человек, а у - численность нелегальных
иммигрантов в сотнях тысяч человек.
,
где х - численность населения штата в
млн человек, а у - численность нелегальных
иммигрантов в сотнях тысяч человек.
8. Благодаря найденным корреляционных зависимостям можно сделать вывод о том, что и первая и вторая гипотезы верны, и не противоречат одна другой. “Нелегалы” скапливаются в наиболее населенных территориях и местах компактного проживания легальной иностранной общины, и обе эти тенденции совпадают друг с другом.
9. Оценки Бюро переписи населения США лучше отражают зависимость численности нелегальных иммигрантов от численности населения, тогда как оценка Службы натурализации и иммиграции больше зависит от численности иностранно-рожденных.
10. При помощи найденных формул можно достаточно достоверно определить численность нелегальных иммигрантов, не только по территориям и странам, но и по отдельным национальным общинам.
Латов Ю.В. (Академия
управления МВД России)