Chapter 18. Forecasting from an Equation
This chapter describes procedures for forecasting and computing fitted values from a single equation. The techniques described here are for forecasting with equation objects estimated using regression methods. Forecasts from equations estimated by specialized techniques, such as ARCH, binary, ordered, tobit, and count methods, are discussed in the corresponding chapters. Forecasting from a series using exponential smoothing methods is explained in “Exponential Smoothing” on page 350, and forecasting using multiple equations and models is described in Chapter 26, “Models”, on page 777.
Forecasting from Equations in EViews
To illustrate the process of forecasting from an estimated equation, we begin with a simple example. Suppose we have data on the logarithm of monthly housing starts (HS) and the logarithm of the S&P index (SP) over the period 1959M01–1996M01. The data are contained in a workfile with range 1959M01–1998M12.
We estimate a regression of HS on a constant, SP, and the lag of HS, with an AR(1) to correct for residual serial correlation, using data for the period 1959M01–1990M12, and then use the model to forecast housing starts under a variety of settings. Following estimation, the equation results are held in the equation object EQ01:
Dependent Variable: HS
Method: Least Squares
Date: 01/15/04 Time: 15:57
Sample (adjusted): 1959M03 1990M:01
Included observations: 371 after adjusting endpoints
Convergence achieved after 4 iterations
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
|
|
|
|
|
|
|
|
|
C |
0.321924 |
0.117278 |
2.744975 |
0.0063 |
HS(-1) |
0.952653 |
0.016218 |
58.74157 |
0.0000 |
SP |
0.005222 |
0.007588 |
0.688249 |
0.4917 |
AR(1) |
-0.271254 |
0.052114 |
-5.205027 |
0.0000 |
|
|
|
|
|
|
|
|
|
|
R-squared |
0.861373 |
Mean dependent var |
7.324051 |
|
Adjusted R-squared |
0.860240 |
S.D. dependent var |
0.220996 |
|
S.E. of regression |
0.082618 |
Akaike info criterion |
-2.138453 |
|
Sum squared resid |
2.505050 |
Schwarz criterion |
-2.096230 |
|
Log likelihood |
400.6830 |
F-statistic |
|
760.1338 |
Durbin-Watson stat |
2.013460 |
Prob(F-statistic) |
0.000000 |
|
|
|
|
|
|
|
|
|
|
|
Inverted AR Roots |
-.27 |
|
|
|
|
|
|
|
|
|
|
|
|
|


Forecasting from Equations in EViews—545
•Forecast name. Fill in the edit box with the series name to be given to your forecast. EViews suggests a name, but you can change it to any valid series name. The name should be different from the name of the dependent variable, since the forecast procedure will overwrite data in the specified series.
•S.E. (optional). If desired, you may provide a name for the series to be filled with the forecast standard errors. If you do not provide a name, no forecast errors will be saved.
•GARCH (optional). For models estimated by ARCH, you will be given a further option of saving forecasts of the conditional variances (GARCH terms). See Chapter 20, “ARCH and GARCH Estimation”, on page 601 for a discussion of GARCH estimation.
•Forecasting method. You have a choice between Dynamic and Static forecast methods. Dynamic calculates dynamic, multi-step forecasts starting from the first period in the forecast sample. In dynamic forecasting, previously forecasted values for the lagged dependent variables are used in forming forecasts of the current value (see “Forecasts with Lagged Dependent Variables” on page 555 and “Forecasting with ARMA Errors” on page 557). This choice will only be available when the estimated equation contains dynamic components, e.g., lagged dependent variables or ARMA terms. Static calculates a sequence of one-step ahead forecasts, using the actual, rather than forecasted values for lagged dependent variables, if available.
You may elect to always ignore coefficient uncertainty in computing forecast standard errors (when relevant) by unselecting the Coef uncertainty in S.E. calc box.
In addition, in specifications that contain ARMA terms, you can set the Structural option, instructing EViews to ignore any ARMA terms in the equation when forecasting. By default, when your equation has ARMA terms, both dynamic and static solution methods form forecasts of the residuals. If you select Structural, all forecasts will ignore the forecasted residuals and will form predictions using only the structural part of the ARMA specification.
•Sample range. You must specify the sample to be used for the forecast. By default, EViews sets this sample to be the workfile sample. By specifying a sample outside the sample used in estimating your equation (the estimation sample), you can instruct EViews to produce out-of-sample forecasts.
Note that you are responsible for supplying the values for the independent variables in the out-of-sample forecasting period. For static forecasts, you must also supply the values for any lagged dependent variables.
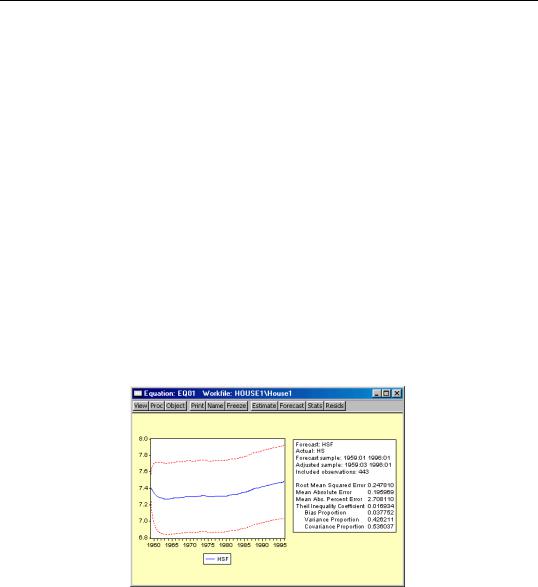
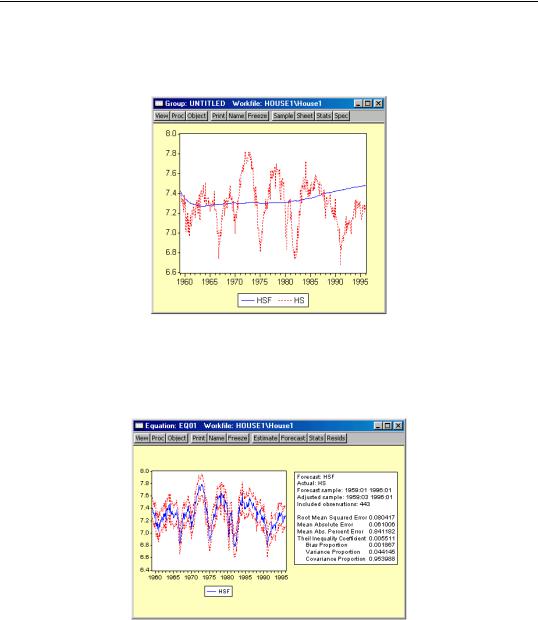
•Output. You can choose to see the forecast output as a graph or a numerical forecast evaluation, or both. Forecast evaluation is only available if the forecast sample includes observations for which the dependent variable is observed.