

The Workfile Window—57
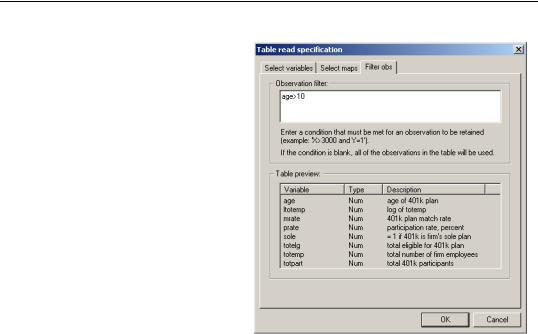
Lastly, the Filter obs page brings up an observation filter specification where you may enter a condition on your data that must be met for a given observation to be read.
When reading the dataset, EViews will discard any observation that does not meet the specified criteria. Here we tell EViews that we only wish to keep observations where AGE>10.
Once you have specified the characteristics of your table read, click on OK to begin the procedure.
EViews will open the foreign dataset, validate the type, create an unstructured workfile, and read the
selected data. When the procedure is completed, EViews will display an untitled group containing the series, and will display relevant information in the status line. In this example, EViews will report that after applying the observation filter it has retained 636 of the 1534 observations in the original dataset.
The Workfile Window
Probably the most important windows in EViews are those for workfiles. Since open workfiles contain the EViews objects that you are working with, it is the workfile window that provides you with access to all of your data. Roughly speaking, the workfile window provides you with a directory for the objects in a given workfile or workfile page. When open, the workfile window also provides you with access to tools for working with workfiles and their pages.
Workfile Directory Display
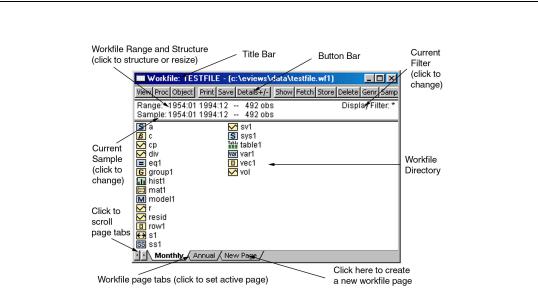
The standard workfile window view will look something like this:
58—Chapter 3. Workfile Basics
In the title bar of the workfile window you will see the “Workfile” designation followed by the workfile name. If the workfile has been saved to disk, you will see the name and the full disk path. Here, the name of the workfile is “TESTFILE”, and it is located in the “C:\EVIEWS\DATA” directory on disk. If the workfile has not been saved, it will be designated “UNTITLED”.
Just below the titlebar is a button bar that provides you with easy access to useful workfile operations. Note that the buttons are simply shortcuts to items that may be accessed from the main EViews menu. For example, the clicking on the Fetch button is equivalent to selecting Object/Fetch from DB... from the main menu.
Below the toolbar are two lines of status information where EViews displays the range (and optionally, the structure) of the workfile, the current sample of the workfile (the range of observations that are to be used in calculations and statistical operations), and the display filter (rule used in choosing a subset of objects to display in the workfile window). You may change the range, sample, and filter by double clicking on these labels and entering the relevant information in the dialog boxes.
Lastly, in the main portion of the window, you will see the contents of your workfile page in the workfile directory. In normal display mode, all named objects are listed in the directory, sorted by name, with an icon showing the object type. The different types of objects and their icons are described in detail in “Object Types” on page 75 of the Command and Programming Reference. You may also show a subset of the objects in your workfile page, as described below.
It is worth keeping in mind that the workfile window is a specific example of an object window. Object windows are discussed in “The Object Window” on page 78.
The Workfile Window—59
Workfile Directory Display Options
You may choose View/Name Display… in the workfile toolbar to specify whether EViews should use upper or lower case letters when it displays the workfile directory. The default is lower case.
You can change the default workfile display to show additional information about your objects. If you select View/Details+/–, or click on the Details +/- button on the toolbar, EViews will toggle between the standard workfile display format, and a display which provides additional information about the date the object was created or updated, as well as the label information that you may have attached to the object.
Filtering the Workfile Directory Display
When working with workfiles containing a large number of objects, it may become difficult to locate specific objects in the workfile directory display. You can solve this problem by using the workfile display filter to instruct EViews to display only a subset of objects in the workfile window. This subset can be defined on the basis of object name as well as object type.
Select View/Display Filter… or double click on the Filter description in the workfile window. The following dialog box will appear:
There are two parts to this dialog. In the edit field (blank space) of this dialog, you may place one or several name descriptions that include the standard wildcard characters: “*” (match any number of characters) and “?” (match any single character).
Below the edit field are a series of check boxes corresponding to various types of EViews

60—Chapter 3. Workfile Basics
objects. EViews will display only objects of the specified types whose names match those in the edit field list.
The default string is “*”, which will display all objects of the specified types. However, if you enter the string:
x*
only objects with names beginning with X will be displayed in the workfile window. Entering:
x?y
displays all objects that begin with the letter X, followed by any single character and then ending with the letter Y. If you enter:
x* y* *z
all objects with names beginning with X or Y and all objects with names ending in Z will be displayed. Similarly, the more complicated expression:
??y* *z*
tells EViews to display all objects that begin with any two characters followed by a Y and any or no characters, and all objects that contain the letter Z. Wildcards may also be used in more general settings—a complete description of the use of wildcards in EViews is provided in Appendix B, “Wildcards”, on page 945.
When you specify a display filter, the Filter description in the workfile window changes to reflect your request. EViews always displays the current string used in matching names. Additionally, if you have chosen to display a subset of EViews object types, a “–” will be displayed in the Display Filter description at the top of the workfile window.