

Object Aliases and Illegal Names—285
To further restrict your search to series with at least quarterly frequency and to display the start and end dates of the results, click Query and again and modify the fields as follows:
Select: name, type, start, end, description
Where: description matches gasoline and freq>=q
If you are interested in seasonally adjusted series, which happen to contain sa or saar in their description in this database, further modify the fields to
Select: name, type, start, end, description
Where: description matches "gasoline and (sa or saar)" and freq>=q
The display of the query results now looks as follows:
Object Aliases and Illegal Names
When working with a database, EViews allows you to create a list of aliases for each object in the database so that you may refer to each object by a different name. The most important use of this is when working with a database in a foreign format where some of the names used in the database are not legal EViews object names. However, the aliasing fea-
286—Chapter 10. EViews Databases
tures of EViews can also be used in other contexts, such as to assign a shorter name to a series with an inconveniently long name.
The basic idea is as follows: each database can have one or more object aliases associated with it where each alias entry consists of the name of the object in the database and the name by which you would like it to be known in EViews.
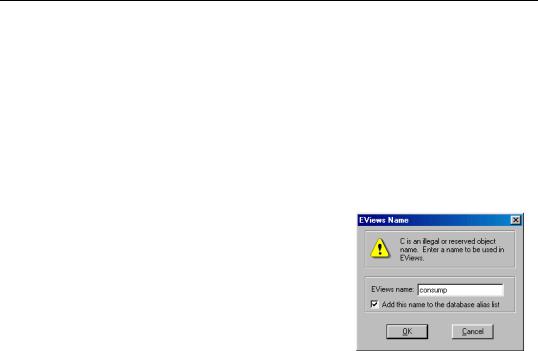
The easiest way to create an object alias for an illegal name is to attempt to fetch the object with the illegal name into EViews. If you are working with query results, you can tell which object names are illegal because they will be displayed in the database window in red. When you try to fetch an object with an illegal name, a dialog will appear.
The field labeled EViews Name initially contains the illegal name of the database object. You should edit this to form a legal EViews object name. In this example, we could change the name C to CONSUMP. The checkbox labeled Add this name to the database alias list (which is not checked by default), determines whether you want to create a permanent association between the name you have just typed and the illegal name. If you check the box, then whenever you use the edited object name in the future, EViews will take it to
refer to the underlying illegal name. The edited name acts as an alias for the underlying name. It is as though you had renamed the object in the database to the new legal name, except that you have not actually modified the database itself, and your changes will not affect other users of the database.
When EViews displays an object in the database window for which an alias has been set, EViews will show the alias, rather than the underlying name of the object. In order to indicate that this substitution has been done, EViews displays the name of the aliased object in blue.
Creating an alias can cause shadowing of object names. Shadowing occurs when you create an alias for an object in the database, but the name you use as an alias is the name of another object in the database. Because the existence of the alias will stop you from accessing the other object, that object is said to be shadowed. To indicate that an object name being displayed has been shadowed, EViews displays the name of shadowed objects in green. You will not be able to fetch an object which has been shadowed without modifying either its name or the alias which is causing it to be shadowed. Even if the shadowed series is explicitly selected with the mouse, operations performed on the series will use the series with the conflicting alias, not the shadowed series.
Maintaining the Database—287
You can view a list of the aliases currently defined for any database by clicking on the View button at the top of the database window, then selecting Object Aliases. A list of all the aliases will be displayed in the window.
Each line represents one alias attached to the database and follows the format:
alias = database_object_name
You can edit the list of aliases to delete unwanted entries, or you can type in, or cut-and- paste, new entries into the file. You must follow the rule that both the set of aliases and the set of database names do not contain any repeated entries. (If you do not follow this rule, EViews will refuse to save your changes). To save any modifications you have made, simply switch back to the Object Display view of the database. EViews will prompt you for whether you want to save or discard your edits.
The list of currently defined database aliases for all databases is kept in the file OBALIAS.INI in the EViews installation directory. If you would like to replicate a particular set of aliases onto a different machine, you should copy this file to the other machine, or use a text editor to combine a portion of this file with the file already in use on the other machine. You must exit and restart EViews to be sure that EViews will reread the aliases from the file.
Maintaining the Database
In many cases an EViews database should function adequately without any explicit maintenance. Where maintenance is necessary, EViews provides a number of procedures to help you perform common tasks.
Database File Operations
Because EViews databases are spread across multiple files, all of which have the same name but different extensions, simple file operations like copy, rename and delete require multiple actions if performed outside of EViews. The Proc button in the database window toolbar contains the procedures Copy the database, Rename the database, and Delete the database that carry out the chosen operation on all of the files that make up the database.

288—Chapter 10. EViews Databases
Note that file operations do not automatically update the database registry. If you delete or rename a database that is registered, you should either create a new database with the same name and location, or edit the registry.
Packing the Database
If many objects are deleted from an EViews database without new objects being inserted, a large amount of unused space will be left in the database. In addition, if objects are frequently overwritten in the database, there will be a tendency for the database to grow gradually in size. The extent of growth will depend on the circumstances, but a typical database is likely to stabilize at a size around 60% larger than what it would be if it were written in a single pass.
A database can be compacted down to its minimum size by using the pack procedure. Simply click on the button marked Proc in the toolbar at the top of the database window, then select the menu item Pack the Database. Depending on the size of the database and the speed of the computer which you are using, performing this operation may take a significant amount of time.
You can get some idea of the amount of space that will be reclaimed during a pack by looking at the Packable Space percentage displayed in the top right corner of the database window. A figure of 30%, for example, indicates that roughly a third of the database file consists of unused space. A more precise figure can be obtained from the Database Statistics view of a database. The number following the label “unused space” gives the number of unused bytes contained in the main database file.
Dealing with Errors
EViews databases are quite robust, so you should not experience problems working with them on a regular basis. However, as with all computer files, hardware or operating system problems may produce conditions under which your database is damaged.
The best way to protect against damage to a database is to make regular backup copies of the database. This can be performed easily using the Copy the Database procedure documented above. EViews provides a number of other features to help you deal with damaged databases.
Damaged databases can be divided into two basic categories depending on how severely the database has been damaged. A database which can still be opened in a database window but generates an error when performing some operations may not be severely damaged and may be reparable. A database which can no longer be opened in a database window is severely damaged and will need to be rebuilt as a new database.
EViews has two procedures designed for working with databases which can be opened: Test Database Integrity and Repair Database. Both procedures are accessed by clicking