

Pooled Data—829
Pooled Data
As noted previously, all of your pooled data will be held in ordinary EViews series. These series can be used in all of the usual ways: they may, among other things, be tabulated, graphed, used to generate new series, or used in estimation. You may also use a pool object to work with sets of the individual series.
There are two classes of series in a pooled workfile: ordinary series and cross-section specific series.
Ordinary Series
An ordinary series is one that has common values across all cross-sections. A single series may be used to hold the data for each variable, and these data may be applied to every cross-section. For example, in a pooled workfile with firm cross-section identifiers, data on overall economic conditions such as GDP or money supply do not vary across firms. You need only create a single series to hold the GDP data, and a single series to hold the money supply variable.
Since ordinary series do not interact with cross-sections, they may be defined without reference to a pool object. Most importantly, there are no naming conventions associated with ordinary series beyond those for ordinary EViews objects.
Cross-section Specific Series
Cross-section specific series are those that have values that differ between cross-sections. A set of these series are required to hold the data for a given variable, with each series corresponding to data for a specific cross-section.
Since cross-section specific series interact with cross-sections, they should be defined in conjunction with the identifiers in pool objects. Suppose, for example, that you have a pool object that contains the identifiers “_USA”, “_JPN”, “_KOR” and “_UK”, and that you have time series data on GDP for each of the cross-section units. In this setting, you should have a four cross-section specific GDP series in your workfile.
The key to naming your cross-section specific series is to use names that are a combination of a base name and a cross-section identifier. The cross-section identifiers may be embedded at an arbitrary location in the series name, so long as this is done consistently across identifiers.
You may elect to place the identifier at the end of the base name, in which case, you should name your series “GDP_USA”, “GDP_JPN”, “GDP_KOR”, and “GDP_UK”. Alternatively, you may choose to put the section identifiers in front of the name, so that you have the names “_USAGDP”, “_JPNGDP”, “_KORGDP”, and “_UKGDP”. The identifiers may


Setting up a Pool Workfile—831
and to refer to them collectively as the pool series “ASIA_?”. While not particularly difficult to do, this direct approach becomes more cumbersome the greater the number of crosssection identifiers.
More easily, we may use the special pool series expression:
@ingrp(asia)
to define a special virtual pool series in which each observation takes a 0 or 1 indicator for whether an observation is in the specified group. This expression is equivalent to creating the four cross-section specific series, and referring to them as “ASIA_?”.
We must emphasize that pool series specifiers using the “?” and the @INGRP function may only be used through a pool object, since they have no meaning without a list of cross-section identifiers. If you attempt to use a pool series outside the context of a pool object, EViews will attempt to interpret the “?” as a wildcard character (see Appendix B, “Wildcards”, on page 945). The result, most often, will be an error message saying that your variable is not defined.
Setting up a Pool Workfile
Your goal in setting up a pool workfile is to obtain a workfile containing individual series for ordinary variables, sets of appropriately named series for the cross-section specific data, and pool objects containing the related sets of identifiers. The workfile should have frequency and range matching the time series dimension of your pooled data.
There are two basic approaches to setting up such a workfile. The direct approach involves first creating an empty workfile with the desired structure, and then importing data into individual series using either standard or pool specific import methods. The indirect approach involves first creating a stacked representation of the data in EViews, and then using EViews built-in reshaping tools to set up a pooled workfile.
Direct Setup
The direct approach to setting up your pool workfile involves three distinct steps: first creating a workfile with the desired time series structure; next, creating one or more pool objects containing the desired cross-section identifiers; and lastly, using pool object tools to import data into individual series in the workfile.
Creating the Workfile and Pool Object
The first step in the direct setup is to create an ordinary EViews workfile structured to match the time series dimension of your data. The range of your workfile should represent the earliest and latest dates or observations you wish to consider for any of the cross-sec- tion units.

Setting up a Pool Workfile—833
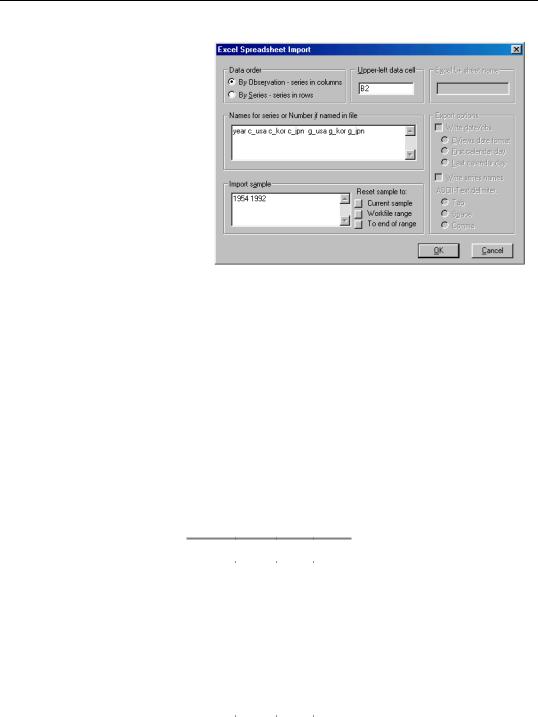
EViews pooled workfiles are structured to work naturally with data that are unstacked, since the sets of cross-section specific series in the pool workfile correspond directly to the multiple columns of unstacked source data. You may read unstacked data directly into EViews using the standard import procedures described in “Frequency Conversion” on page 115. Simply read each cross-section specific
variable as an individual series, making certain that the names of the resulting series follow the pool naming conventions given in your pool object. Ordinary series may be imported in the usual fashion with no additional complications.
In this example, we use the standard EViews import tools to read separate series for each column. We create the individual series “YEAR”, “C_USA”, “C_KOR”, “C_JPN”, “G_USA”, “G_JPN”, and “G_KOR”.
Stacked Data
Pooled data can also be arranged in stacked form, where all of the data for a variable are grouped together in a single column.
In the most common form, the data for different cross-sections are stacked on top of one another, with all of the sequentially dated observations for a given cross-section grouped together. We may say that these data are stacked by cross-section:
id |
year |
c |
g |
_usa |
1954 |
61.6 |
17.8 |
_usa |
… |
… |
… |
_usa |
… |
… |
… |
_usa |
1992 |
68.1 |
13.2 |
…… … …
_kor |
1954 |
77.4 |
17.6 |
_kor |
… |
… |
… |
_kor |
1992 |
na |
na |

Setting up a Pool Workfile—835
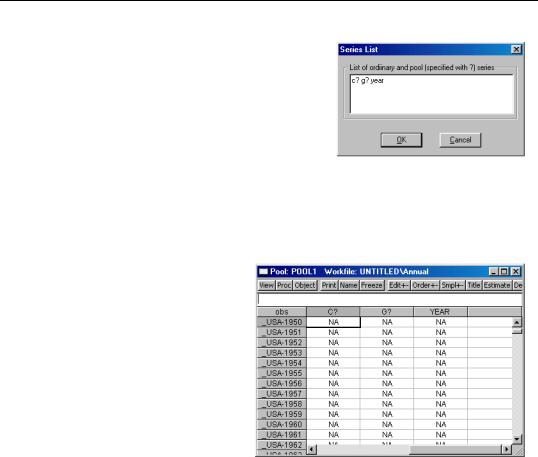
For example, if we have a pool object that contains the identifiers “_USA”, “_UK”, “_JPN”, and “_KOR”, we can instruct EViews to create the series C_USA, C_UK, C_JPN, C_KOR, and G_USA, G_UK, G_JPN, G_KOR, and YEAR simply by entering the pool series names “C?”, “G?” and the ordinary series name “YEAR”, and pressing OK.
EViews will open a stacked spreadsheet view of the
series in your list. Here we see the series stacked by cross-section, with the pool or ordinary series names in the column header, and the cross-section/date identifiers labeling each row. Note that since YEAR is an ordinary series, its values are repeated for each crosssection in the stacked spreadsheet.
If desired, click on Order +/– to toggle between stacking methods to match the organization of the data to be imported. Click on Edit +/– to turn on edit mode, and enter or cut-and-paste into the window.
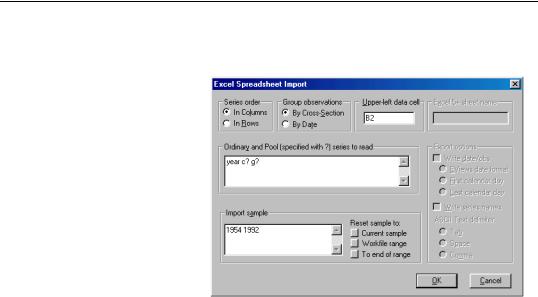
Alternatively, you can import stacked data from a file using import tools built into the pool object. While the data in the file may be stacked either by cross-sec- tion or by period, EViews does
require that the stacked data are “balanced”, and that the cross-sections ordering in the file matches the cross-sectional identifiers in the pool. By “balanced”, we mean that if the data are stacked by cross-section, each cross-section should contain exactly the same number of periods—if the data are stacked by date, each date should have exactly the same number of cross-sectional observations arranged in the same order.
We emphasize that only the representation of the data in the import file needs to be balanced; the underlying data need not be balanced. Notably, if you have missing values for some observations, you should make certain that there are lines in the file representing the missing values. In the two examples above, the underlying data are not balanced, since information is not available for Korea in 1992. The data in the file have been balanced by including an observation for the missing data.
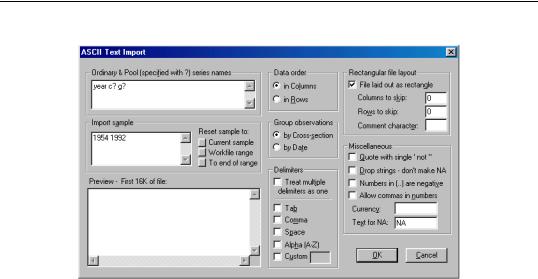
To import stacked pool data from a file, first open the pool object, then select Proc/Import Pool data (ASCII, .XLS, .WK?)…It is important that you use the import procedure associated with the pool object, and not the standard file import procedure.
Setting up a Pool Workfile—837
For a discussion of the text specific settings in the dialog, see “Importing ASCII Text Files” on page 120.
Indirect Setup (Restructuring)
Second, you may create an ordinary EViews workfile containing your data in stacked form, and then use the workfile reshaping tools to create a pool workfile with the desired structure and contents.
The first step in the indirect setup of a pool workfile is to create a workfile containing the contents of your stacked data file. You may manually create the workfile and import the stacked series data, or you may use EViews tools for opening foreign source data directly into a new workfile (“Creating a Workfile by Reading from a Foreign Data Source” on page 53).
Once you have your stacked data in an EViews workfile, you may use the workfile reshaping tools to unstack the data into a pool workfile page. In addition to unstacking the data into multiple series, EViews will create a pool object containing identifiers obtained from patterns in the series names. See “Reshaping a Workfile” beginning on page 241 for a general discussion of reshaping, and “Unstacking a Workfile” on page 244 for a more specific discussion of the unstack procedure.
The indirect method is almost always easier to use than the direct approach and has the advantage of not requiring that the stacked data be balanced. It has the disadvantage of using more computer memory since EViews must have two copies of the source data in memory at the same time.