


Building a Model—795
•You can use the Make model procedure from an estimation object to create a model containing the equation or equations in that object.
Adding Equations to the Model
The equations in a model can be classified into two types: linked equations and inline equations. Linked equations are equations that import their specification from other objects in the workfile. Inline equations are contained inside the model as text.
There are a number of ways to add equations to your model:
•To add a linked equation: from the workfile window, select the object which contains the equation or equations you would like to add to the model, then copy-and- paste the object into the model equation view window.
•To add an equation using text: select Insert… from the right mouse button menu. In the text box titled: Enter one or more lines…, type in one or more equations in standard EViews format. You can also add linked equations from this dialog by typing a colon followed by the name of the object you would like to link to, for example “:EQ1”, because this is the text form of a linked object.
In an EViews model, the first variable that appears in an equation will be considered the endogenous variable for that equation. Since each endogenous variable can be associated with only one equation, you may need to rewrite your equations to ensure that each equation begins with a different variable. For example, say we have an equation in the model:
x / y = z
EViews will associate the equation with the variable X. If we would like the equation to be associated with the variable Y, we would have to rewrite the equation:
1 / y * x = z
Note that EViews has the ability to handle simple expressions involving the endogenous variable. You may use functions like LOG, D, and DLOG on the left-hand side of your equation. EViews will normalize the equation into explicit form if the Gauss-Seidel method is selected for solving the model.
Removing equations from the model
To remove equations from the model, simply select the equations using the mouse in Equation view, then use Delete from the right mouse button menu to remove the equations.
Both adding and removing equations from the model will change which variables are considered endogenous to the model.

Working with the Model Structure—797
You can open any linked objects directly from the equation view. Simply select the line representing the object using the mouse, then choose Open Link from the right mouse button menu.
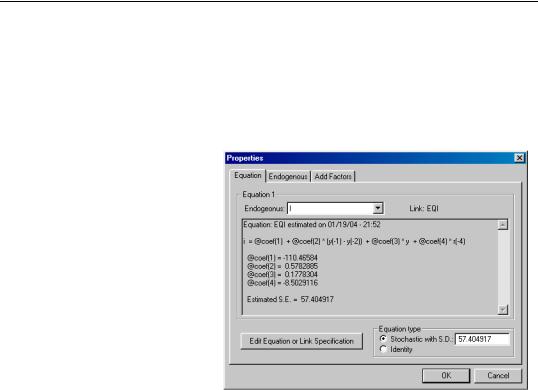
The contents of a line can be examined in more detail using the equation properties dialog. Simply select the line with the mouse, then choose Properties… from the right mouse button menu. Alternatively, simply double click on the object to call up the dialog.
For a link to a single equation, the dialog shows the functional form of the equation, the values of any estimated coefficients, and the standard error of the equation residual from the estimation. If the link is to an object containing many equations, you can move between the different equations imported from the object using the Endogenous list box at the top of the dialog. For an inline equation, the dialog simply shows the text of the equation.
The Edit Equation or Link Specification button allows you to edit the text of an inline equation or to modify a link to point to an object with a different name. A link is represented in text form as a colon followed by the name of the object. Note that you cannot modify the specification of a linked object from within the model object, you must work directly with the linked object itself.
In the bottom right of the dialog, there are a set of fields that allow you to set the stochastic properties of the residual of the equation. If you are only performing deterministic simulations, then these settings will not affect your results in any way. If you are performing stochastic simulations, then these settings are used in conjunction with the solution options to determine the size of the random innovations applied to this equation.
The Stochastic with S.D. option for Equation type lets you set a standard deviation for any random innovations applied to the equation. If the standard deviation field is blank or is set to “NA”, then the standard deviation will be estimated from the historical data. The Identity option specifies that the selected equation is an identity, and should hold without error even in a stochastic simulation. See “Stochastic Options” on page 810 below for further details.

Working with the Model Structure—799
Block structure refers to whether the model can be split into a number of smaller parts, each of which can be solved for in sequence. For example, consider the system:
block 1 |
x = y + 4 |
|
|
|
y = 2*x – 3 |
|
|
block 2 |
z = x + y |
|
|
Because the variable Z does not appear in either of the first two equations, we can split this equation system into two blocks: a block containing the first two equations, and a block containing the third equation. We can use the first block to solve for the variables X and Y, then use the second block to solve for the variable Z. By using the block structure of the system, we can reduce the number of variables we must solve for at any one time. This typically improves performance when calculating solutions.
Blocks can be classified further into recursive and simultaneous blocks. A recursive block is one which can be written so that each equation contains only variables whose values have already been determined. A recursive block can be solved by a single evaluation of all the equations in the block. A simultaneous block cannot be written in a way that removes feedback between the variables, so it must be solved as a simultaneous system. In our example above, the first block is simultaneous, since X and Y must be solved for jointly, while the second block is recursive, since Z depends only on X and Y, which have already been determined in solving the first block.
The block structure view displays the structure of the model, labeling each of the blocks as recursive or simultaneous. EViews uses this block structure whenever the model is solved. The block structure of a model may also be interesting in its own right, since reducing the system to a set of smaller blocks can make the dependencies in the system easier to understand.
Text View
The text view of a model allows you to see the entire structure of the model in a single screen of text. This provides a quick way to input small models, or a way to edit larger models using copy-and-paste.
The text view consists of a series of lines. In a simple model, each line simply contains the text of one of the inline equations of the model. More complicated models may contain one of more of the following:
•A line beginning with a colon “:” represents a link to an external object. The colon must be followed by the name of an object in the workfile. Equations contained in the external object will be imported into the model whenever the model is opened, or when links are updated.