




Estimating a Panel Equation—903
You should be aware that when you select a fixed or random effects specification, EViews will automatically add a constant to the common coefficients portion of the specification if necessary, to ensure that the effects sum to zero.
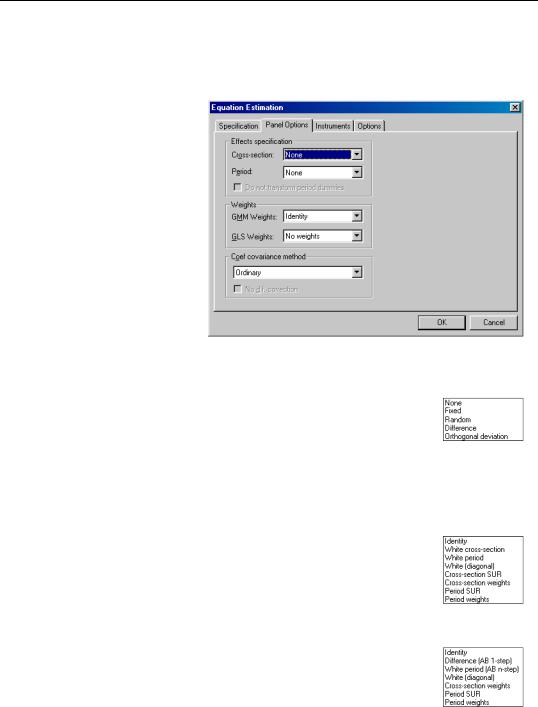
Next, you should specify settings for GLS Weights. You may choose to estimate with no weighting, or with Cross-section weights, Cross-sec- tion SUR, Period weights, Period SUR. The Cross-section SUR setting allows for contemporaneous correlation between cross-sections, while
the Period SUR allows for general correlation of residuals across periods for a specific cross-section. Cross-section weights and Period weights allow for heteroskedasticity in the relevant dimension.
For example, if you select Cross section weights, EViews will estimate a feasible GLS specification assuming the presence of cross-section heteroskedasticity. If you select Cross-sec- tion SUR, EViews estimates a feasible GLS specification correcting for both cross-section heteroskedasticity and contemporaneous correlation. Similarly, Period weights allows for period heteroskedasticity, while Period SUR corrects for both period heteroskedasticity and general correlation of observations within a given cross-section. Note that the SUR specifications are both examples of what is sometimes referred to as the Parks estimator. See the pool discussion of “Generalized Least Squares” on page 864 for additional details.
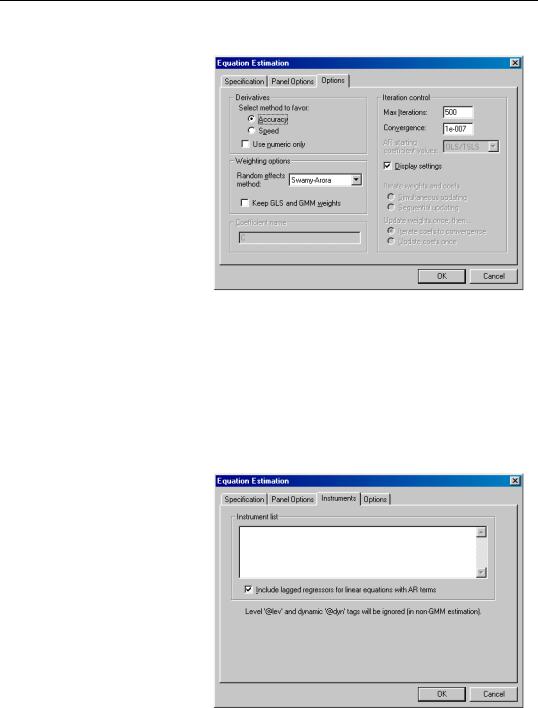
Lastly, you should specify a method for computing coefficient covariances. You may use the combo box labeled Coef covariance method to select from the various robust methods available for computing the coefficient standard errors. The covariance calculations may be chosen to be robust under vari-
ous assumptions, for example, general correlation of observations within a cross-section, or perhaps cross-section heteroskedasticity. Click on the checkbox No d.f. correction to perform the calculations without the leading degree of freedom correction term.
Each of the methods is described in greater detail in “Robust Coefficient Covariances” on page 869 of the pool chapter.
You should note that some combinations of specifications and estimation settings are not currently supported. You may not, for example, estimate random effects models with crosssection specific coefficients, AR terms, or weighting. Furthermore, while two-way random effects specifications are supported for balanced data, they may not be estimated in unbalanced designs.
Estimating a Panel Equation—905
page. First, in the edit box labeled Instrument list, you will list the names of the series or groups of series you wish to use as instruments.
Next, if your specification contains AR terms, you should use the checkbox to indicate whether EViews should automatically create instruments to be used in estimation from lags of the dependent and regressor variables in the original specification. When estimating an equation specified by list that contains AR terms, EViews transforms the linear model and estimates the nonlinear differenced specification. By default, EViews will add lagged values of the dependent and independent regressors to the corresponding lists of instrumental variables to account for the modified specification, but if you wish, you may uncheck this option.
See the pool chapter discussion “Instrumental Variables” on page 867 for additional detail.
GMM Estimation
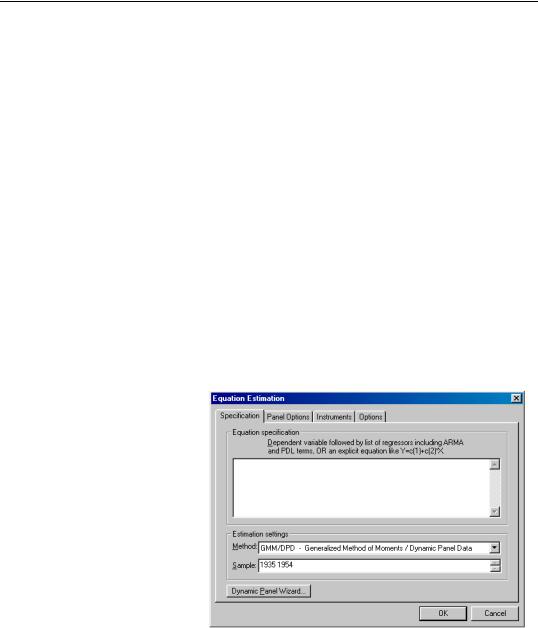
To estimate a panel specification using GMM techniques, you should select GMM / DPD - Generalized Method of Moments / Dynamic Panel Data in the Method combo box at the bottom of the main (Specification) dialog page. Again, you should make certain that your workfile has a panel structure. EViews will respond by displaying a four page dialog that differs significantly from the previous dialogs.
GMM Specification
The specification page is similar to the earlier dialogs. Like the earlier dialogs, you will enter your equation specification in the upper edit box and your sample in the lower edit box.
Note, however, the presence of the Dynamic Panel Wizard... button on the bottom of the dialog. Pressing this button opens a wizard that will aid you in filling out the dialog so that
you may employ dynamic panel data techniques such as the Arellano-Bond 1-step estimator for models with lagged endogenous variables and cross-section fixed effects. We will return to this wizard shortly (“GMM Example” on page 917).

Estimating a Panel Equation—907
cally referred to as Arellano-Bond 1-step estimation. Similarly, you may choose the White period (AB 1-step) weights if you wish to compute Arellano-Bond 2-step or multi-step estimation. Note that the White period weights have been relabeled to indicate that they are typically associated with a specific estimation technique.
Note also that if you estimate your model using difference or orthogonal deviation methods, some GMM weighting methods will no longer be available.
GMM Instruments
Instrument specification in GMM estimation follows the discussion above with a few additional complications.
First, you may enter your instrumental variables as usual by providing the names of series or groups in the edit field. In addition, you may tag instruments as period-specific predetermined instruments, using the “@DYN” keyword, to indicate that the number of implied instruments expands dynamically over time as additional predetermined variables become available.
To specify a set of dynamic instruments associated with the series X, simply enter “@DYN(X)” as an instrument in the list. EViews will, by default, use the series X(-2), X(- 3), ..., X(-T), as instruments for each period (where available). Note that the default set of instruments grows very quickly as the number of periods increases. With 20 periods, for example, there are 171 implicit instruments associated with a single dynamic instrument. To limit the number of implied instruments, you may use only a subset of the instruments by specifying additional arguments to “@DYN” describing a range of lags to be used.
For example, you may limit the maximum number of lags to be used by specifying both a minimum and maximum number of lags as additional arguments. The instrument specification:
@dyn(x, -2, -5)
instructs EViews to include lags of X from 2 to 5 as instruments for each period.
If a single argument is provided, EViews will use it as the minimum number of lags to be considered, and will include all higher ordered lags. For example:
@dyn(x, -5)
includes available lags of X from 5 to the number of periods in the sample.
Second, in specifications estimated using transformations to remove the cross-section fixed effects (first differences or orthogonal deviations), use may use the “@LEV” keyword to instruct EViews to use the instrument in untransformed, or level form. Tagging an instrument with “@LEV” indicates that the instrument is for the transformed equation If