


Chapter 10. EViews Databases
An EViews database resembles a workfile in that it is used to contain a collection of EViews objects. It differs from a workfile in two major ways. First, unlike a workfile, the entire database need not be loaded into memory in order to access an object inside it; an object can be fetched or stored directly to or from the database on disk. Second, unlike a workfile page, the objects in a database are not restricted to being of a single frequency or range. A database could contain a collection of annual, monthly, and daily series, all with different numbers of observations.
EViews databases also differ from workfiles in that they support powerful query features which can be used to search through the database to find a particular series or a set of series with a common property. This makes databases ideal for managing large quantities of data.
While EViews has its own native storage format for databases, EViews also allows direct access to data stored in a variety of other formats through the same database interface. You can perform queries, copy objects to and from workfiles and other databases, and rename and delete objects within a database, all without worrying about in what format the data is actually stored.
Database Overview
An EViews database is a set of files containing a collection of EViews objects. In this chapter we describe how to:
•Create a new database or open an existing database.
•Work with objects in the database, including how to store and fetch objects into workfiles, and how to copy, rename and delete objects in the database.
•Use auto-series to work with data directly from the database without creating a copy of the data in the workfile.
•Use the database registry to create shortcuts for long database names and to set up a search path for series names not found in the workfile.
•Perform a query on the database to get a list of objects with particular properties.
•Use object aliases to work with objects whose names are illegal or awkward.
•Maintain a database with operations such as packing, copying, and repairing.
•Work with remote database links to access data from remote sites.
262—Chapter 10. EViews Databases
Database Basics
What is an EViews Database?
An EViews native format database consists of a set of files on disk. There is a main file with the extension .EDB which contains the actual object data, and a number of index files with extensions such as .E0, .E1A and .E1B which are used to speed up searching operations on the database. In normal use, EViews manages these files for the user, so there is no need to be aware of this structure. However, if you are copying, moving, renaming, or deleting an EViews database from outside of EViews (using Windows Explorer for example), you should perform the operation on both the main database file and all the index files associated with the database. If you accidentally delete or damage an index file, EViews can regenerate it for you from the main data file using the repair command (see “Maintaining the Database” on page 287).
The fact that EViews databases are kept on disk rather than in memory has some important consequences. Any changes made to a database cause immediate changes to be made to the disk files associated with the database. Therefore, unlike workfiles, once a change is made to a database, there is no possibility of discarding the change and going back to the previously saved version. Because of this, you should take care when modifying a database, and should consider keeping regular backup copies of databases which you modify frequently.
EViews also allows you to deal with a variety of foreign format databases through the same interface provided to EViews’ native format databases. Foreign databases can have many different forms, including files on disk, or data made available through some sort of network server. See “Foreign Format Databases” on page 289 for a discussion of the different types of foreign databases that EViews can access.
Creating a Database
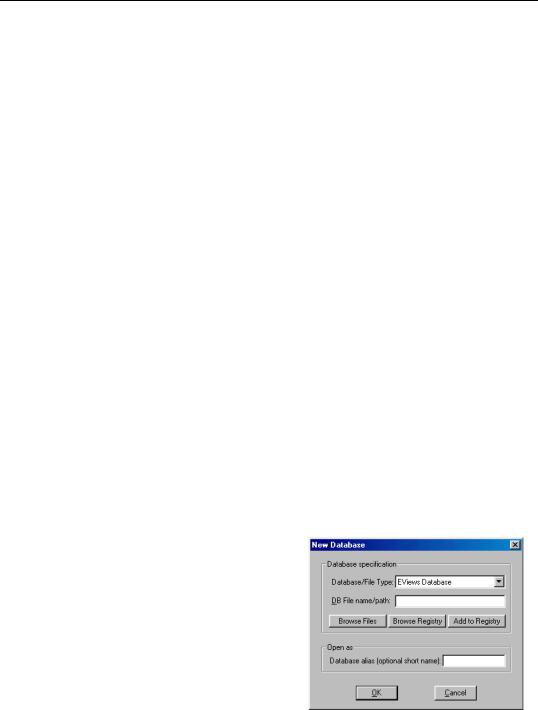
To create a database, simply select File/New/Database… from the main menu.
For a native EViews database, simply enter a name for the database in the field labeled DB File name/path, then click on the button marked OK. This will create a new EViews database in the current path.
To create a database in a different directory, you can enter the full path and database name in the DB File name/path edit field. Alternatively, you can browse to the desired directory. Simply click on the Browse Files button to call

Database Basics—263
up the common file dialog, and then navigate to the target directory. Enter the name of the new database in the File name edit field, then click on the OK button to accept the information and close the file dialog. EViews will put the new path and filename in the DB File name/path edit field.
The Database/File Type field allows you to create different types of databases. See “Foreign Format Databases” on page 289 for a discussion of working with different database types.
The Open As field allows you to specify the shorthand that will be associated with this database. A shorthand is a short text label which is used to refer to the database in commands and programs. If you leave this field blank, a default shorthand will be assigned automatically (see “Database Shorthands” on page 265).
The Browse Registry and Add to Registry buttons provide a convenient way to recall information associated with a previously registered database or to include the new database in the database registry (see “The Database Registry” on page 275).
A database can also be created from the command line or in a program using the command:
dbcreate db_name
where db_name is the name of the database using the same rules given above.
The Database Window
When you create a new database, a database window will open on the screen.
The database window provides a graphical interface which allows you to query the database, copy-and- paste objects to and from your workfile, and perform basic maintenance on the database. Note that some
database operations can also be carried out directly without first opening the database window.
To open a database window for an existing database, select File/Open/Database… from the main menu. The same dialog will appear as was used during database creation. To open an EViews database, use the Browse Files button to select a file using the common file dialog, then click on OK to open the file. A new window should appear representing the open database.
From the command line or in a program, you can open a database window by typing:
264—Chapter 10. EViews Databases
dbopen db_name
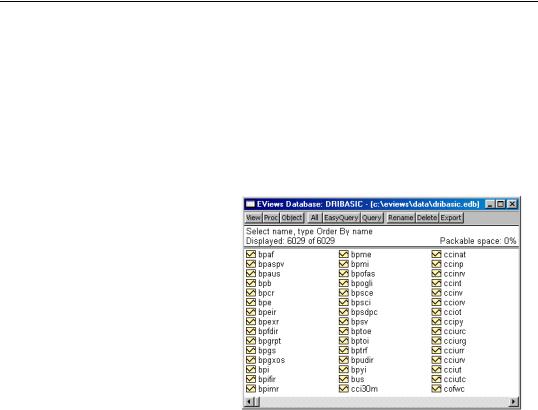
Unlike a workfile window, a database window does not display the contents of the database when it is first opened, although it does tell you how many objects are in the database. The second line of the window text shows the number of objects currently displayed (zero when the window is first opened) followed by the total number of objects stored in the database.
You can bring up an alphabetical listing of every object in the database by clicking on the All button:
As for a workfile, each object is preceded by a small icon that identifies the type of the object. When performing an All query, no other information about the object is visible. However, by double clicking on an object you can bring up a full description of the object including its name, type, modification date, frequency, start and end date (for series), and label.
For large databases, the All button generally displays too many
objects and not enough information about each object. The database query features (“Querying the Database” on page 277) allow you to control precisely which objects should be displayed, and what information about each object should be visible. The text form of the query currently being displayed is always visible in the top line of the database window.
When working with foreign databases, the object names may appear in color to indicate that they are illegal names or that an alias has been attached to an object name (see “Object Aliases and Illegal Names” on page 285).
The “Packable space” field in the database window displays the percentage of unused space in the database that can be recovered by a database pack operation (see “Packing the Database” on page 288).
A brief technical note: having a database window open in EViews generally does not keep a file open at the operating system level. EViews will normally open files only when it is performing operations on those files. Consequently, multiple users may have a database open at the same time and can perform operations simultaneously. There are some limits imposed by the fact that one user cannot read from a database that another user is writing to at the same time. However, EViews will detect this situation and continue to retry the

Database Basics—265
operation until the database becomes available. If the database does not become available within a specified time, EViews will generate an error stating that a “sharing violation” on the database has occurred.
For some foreign formats, even minor operations on a database may require full rewriting of the underlying file. In these cases, EViews will hold the file open as long as the database window is open in order to improve efficiency. The formats that currently behave this way are Aremos TSD files, RATS portable files and TSP portable files. When using these formats, only one user at a time may have an open database window for the file.
Database Shorthands
In many situations, EViews allows you to prefix an object name with a database identifier to indicate where the series is located. These database identifiers are referred to as “shorthands”. For example, the command:
fetch db1::x db2::y
indicates to EViews that the object named X is located in the database with the shorthand db1 and the object named y is located in the database with the shorthand db2.
Whenever a database is opened or created, it is assigned a shorthand. The shorthand can be specified by the user in the Open as field when opening a database, or using the “As” clause in the dbopen command (see dbopen (p. 266) in the Command and Programming Reference). If a shorthand is explicitly specified when opening a database, an error will occur if the shorthand is already in use.
If no shorthand is provided by the user, a shorthand is assigned automatically. The default value will be the name of the database after any path or extension information has been removed. If this shorthand is already in use, either because a database is already open with the same name, or because an entry in the database registry already uses the name, then a numerical suffix is appended to the shorthand, counting upwards until an unused shorthand is found.
For example, if we open two databases with the same name in a program:
dbopen test.edb
dbopen test.dat
then the first database will receive the shorthand “TEST” and the second database will receive the shorthand “TEST1”. If we then issue the command:
fetch test::x
the object X will be fetched from the EViews database TEST.EDB. To fetch X from the Haver database TEST.DAT we would use:

266—Chapter 10. EViews Databases
fetch test1::x
To minimize confusion, you should assign explicit shorthands to databases whenever ambiguity could arise. For example, we could explicitly assign the shorthand TEST_HAVER to the second database by replacing the second dbopen command with:
dbopen test.dat as test_haver
The shorthand attached to a database remains in effect until the database is closed. The shorthand assigned to an open database is displayed in the title bar of the database window.
The Default Database
In order to simplify common operations, EViews uses the concept of a default database. The default database is used in several places, the most important of which is as the default source or destination for store or fetch operations when an alternative database is not explicitly specified.
The default database is set by opening a new database window, or by clicking on an already open database window if there are multiple databases open on the screen. The name of the default database is listed in the status line at the bottom of the main EViews window (see Chapter 4, “Object Basics”, on page 73, for details). The concept is similar to that of the current workfile with one exception: when there are no currently open databases there is still a default database; when there are no currently open workfiles, the current workfile is listed as “none.”
EViews .DB? files
Early versions of EViews and MicroTSP supported a much more limited set of database operations. Objects could be stored on disk in individual files, with one object per file. Essentially, the disk directory system was used as a database and each database entry had its own file. These files had the extension “.DB” for series, and .DB followed by an additional character for other types of objects. EViews refers to these collectively as .DB? files.
While the new database features added to EViews provide a superior method of archiving and managing your data, .DB? files provide backward compatibility and a convenient method of distributing data to other programs. Series .DB files are now supported by a large number of programs including TSP, RATS, and SHAZAM. Additionally, some organizations such as the National Bureau of Economic Research (NBER), distribute data in .DB format.