


Panel Estimation Examples—909
select Undated Panel, and enter “TOWNID” as the Identifier series. EViews will prompt you twice to create a CELLID series to uniquely identify observations. Click on OK to both questions to accept your settings.
EViews restructures your workfile so that it is an unbalanced panel workfile. The top portion of the workfile window will change to show the undated structure which has 92 cross-sections and a maximum of 30 observations in a cross-section.
Next, we open the equation specification dialog by selecting Quick/Estimate Equation from the main EViews menu.
First, following Baltagi and Chang (1994) (also described in Baltagi, 2001), we estimate a fixed effects specification of a hedonic housing equation. The dependent variable in our specification is the median value MV, and the regressors are the crime rate (CRIM), a
dummy variable for the property along Charles River (CHAS), air pollution (NOX), average number of rooms (RM), proportion of older units (AGE), distance from employment centers (DIS), proportion of African-Americans in the population (B), and the proportion of lower status individuals (LSTAT). Note that you may include a constant term C in the specification. Since we are estimating a fixed effects specification, EViews will add one if it is not present so that the fixed effects estimates are relative to the constant term and add up to zero.
Click on the Panel Options tab and select Fixed for the Cross-section effects. To match the Baltagi and Chang results, we will leave the remaining settings at their defaults. Click on OK to accept the specification.


Panel Estimation Examples—911
Dependent Variable: MV
Method: Panel EGLS (Cross-section random effects)
Date: 02/16/04 Time: 12:28
Sample: 1 506
Cross-sections included: 92
Total panel (unbalanced) observations: 506
Wallace and Hussain estimator of component variances
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
|
|
|
|
|
|
|
|
|
C |
9.684427 |
0.207691 |
46.62904 |
0.0000 |
CRIM |
-0.737616 |
0.108966 |
-6.769233 |
0.0000 |
ZN |
0.072190 |
0.684633 |
0.105443 |
0.9161 |
INDUS |
0.164948 |
0.426376 |
0.386860 |
0.6990 |
CHAS |
-0.056459 |
0.304025 |
-0.185703 |
0.8528 |
NOX |
-0.584667 |
0.129825 |
-4.503496 |
0.0000 |
RM |
0.908064 |
0.123724 |
7.339410 |
0.0000 |
AGE |
-0.871415 |
0.487161 |
-1.788760 |
0.0743 |
DIS |
-1.423611 |
0.462761 |
-3.076343 |
0.0022 |
RAD |
0.961362 |
0.280649 |
3.425493 |
0.0007 |
TAX |
-0.376874 |
0.186695 |
-2.018658 |
0.0441 |
PTRATIO |
-2.951420 |
0.958355 |
-3.079674 |
0.0022 |
B |
0.565195 |
0.106121 |
5.325958 |
0.0000 |
LSTAT |
-2.899084 |
0.249300 |
-11.62891 |
0.0000 |
|
|
|
|
|
|
|
|
|
|
|
Effects Specification |
|
|
|
|
|
|
|
|
|
|
|
|
|
Cross-section random S.D. / Rho |
|
0.126983 |
0.4496 |
|
Idiosyncratic random S.D. / Rho |
|
0.140499 |
0.5504 |
|
|
|
|
|
|
|
|
|
|
|
Note that the estimates of the component standard deviations must be squared to match the component variances reported by Baltagi and Chang (0.016 and 0.020, respectively).
Next, we consider an example of estimation with standard errors that are robust to serial correlation. For this example, we employ data on job training grants used in examples from Wooldridge (2002, p. 276 and 282).
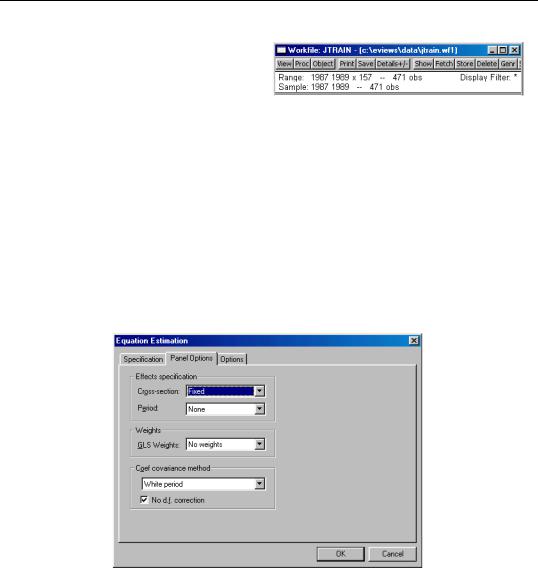
As before, the first step is to structure the workfile as a panel workfile. Click on Range: to bring up the dialog, and enter “YEAR” as the date identifier and “FCODE” as the cross-section ID.

Panel Estimation Examples—913
Dependent Variable: LSCRAP
Method: Panel Least Squares
Date: 02/16/04 Time: 13:28
Sample: 1987 1989
Cross-sections included: 54
Total panel (balanced) observations: 162
White period standard errors & covariance (no d.f. correction)
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
|
|
|
|
|
|
|
|
|
C |
0.597434 |
0.062489 |
9.560565 |
0.0000 |
D88 |
-0.080216 |
0.095719 |
-0.838033 |
0.4039 |
D89 |
-0.247203 |
0.192514 |
-1.284075 |
0.2020 |
GRANT |
-0.252315 |
0.140329 |
-1.798022 |
0.0751 |
GRANT_1 |
-0.421589 |
0.276335 |
-1.525648 |
0.1301 |
|
|
|
|
|
|
|
|
|
|
Effects Specification
Cross-section fixed (dummy variables)
R-squared |
0.927572 |
Mean dependent var |
0.393681 |
Adjusted R-squared |
0.887876 |
S.D. dependent var |
1.486471 |
S.E. of regression |
0.497744 |
Akaike info criterion |
1.715383 |
Sum squared resid |
25.76593 |
Schwarz criterion |
2.820819 |
Log likelihood |
-80.94602 |
F-statistic |
23.36680 |
Durbin-Watson stat |
1.996983 |
Prob(F-statistic) |
0.000000 |
|
|
|
|
|
|
|
|
Note that EViews automatically adjusts for the missing values in the data. There are only 162 observations on 54 cross-sections used in estimation. The top portion of the output indicates that the results use robust White period standard errors with no d.f. correction.
Alternately, we may estimate a first difference estimator for these data with robust standard errors (Wooldridge example 10.6, p. 282). Open a new equation dialog by clicking on Quick/Estimate Equation..., or modify the existing equation by clicking on the Estimate button on the equation toolbar. Enter the specification:
d(lscrap) c d89 d(grant) d(grant_1)
in the Equation specification edit box on the main page, select None in the Cross-section effects specification combo box, and White period with No d.f. correction for the coefficient covariance method on the Panel Options page. The reported results are given by:



Panel Estimation Examples—917
Dependent Variable: D(LUCLMS)
Method: Panel Two-Stage Least Squares
Date: 02/16/04 Time: 17:11
Sample (adjusted): 1983 1988
Cross-sections included: 22
Total panel (balanced) observations: 132
Instrument list: C D(LUCLMS(-2)) D(EZ)
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
|
|
|
|
|
|
|
|
|
C |
-0.201654 |
0.040473 |
-4.982442 |
0.0000 |
D(LUCLMS(-1)) |
0.164699 |
0.288444 |
0.570992 |
0.5690 |
D(EZ) |
-0.218702 |
0.106141 |
-2.060493 |
0.0414 |
|
|
|
|
|
|
|
|
|
|
|
Effects Specification |
|
|
|
|
|
|
|
|
|
|
|
|
|
Period fixed (dummy variables) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
R-squared |
0.280533 |
Mean dependent var |
-0.235098 |
|
Adjusted R-squared |
0.239918 |
S.D. dependent var |
0.267204 |
|
S.E. of regression |
0.232956 |
Sum squared resid |
6.729300 |
|
Durbin-Watson stat |
2.857769 |
J-statistic |
|
9.39E-29 |
Instrument rank |
8.000000 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Note that the instrument rank in this equation is 8 since the period dummies also serve as instruments, so you have the 3 instruments specified explicitly, plus 5 for the non-collinear period dummy variables.
GMM Example
To illustrate the estimation of dynamic panel data models using GMM, we employ the unbalanced 1031 observation panel of firm level data from Layard and Nickell (1986), previously examined by Arellano and Bond (1991). The analysis fits the log of employment
(N) to the low of the real wage (W), log of the capital stock (K), and the log of industry output (YS).
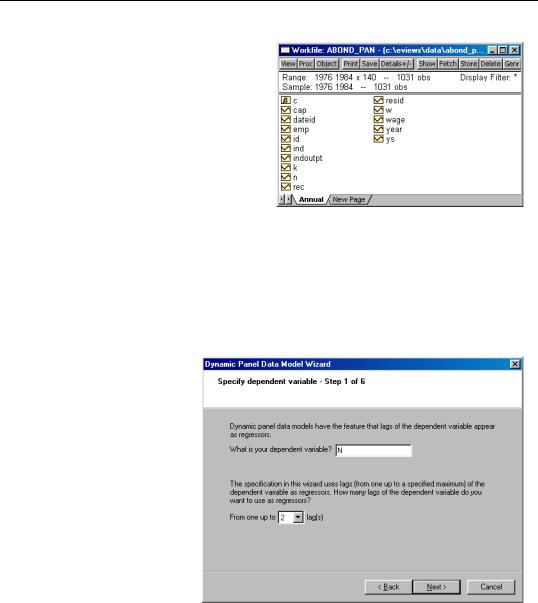
Panel Estimation Examples—919
w w(-1) k ys ys(-1)
in the regressor edit box to include these variables. Since the desired specification will include time dummies, make certain that the checkbox for Include period dummy variables is selected, then click on Next to proceed.
The next page of the wizard is used to specify a transformation to remove the cross-section fixed effect. You may choose to use first Differences or Orthogonal deviations. In addition, if your specification includes period dummy variables, there is a checkbox asking whether you wish to transform the period dummies, or to enter them in levels. Here we specify the first difference transforma-
tion, and choose to include untransformed period dummies in the transformed equation. Click on Next to continue.
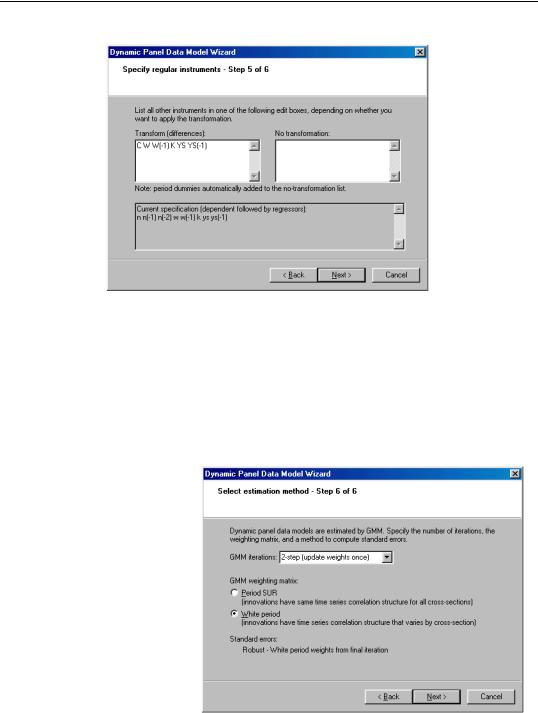
The next page is where you will specify your dynamic period-specific (predetermined) instruments. The instruments should be entered with the “@DYN” tag to indicate that they are to be expanded into sets of predetermined instruments, with optional arguments to indicate the lags to be included. If no arguments are provided, the default is to include all valid lags (from -2 to “-infinity”).
Here, we instruct EViews that we wish to use the default lags for N as predetermined instruments.

Panel Estimation Examples—921
to convergence), to iterate the weight calculations. In the first case, EViews will provide you with choices for computing the standard errors, but here only White period robust standard errors are allowed. Clicking on Next takes you to the final page. Click on Finish to return to the Equation Estimation dialog.
EViews has filled out the Equation Estimation dialog with our choices from the DPD wizard. You should take a moment to examine the settings that have been filled out for you since, in the future, you may wish to enter the specification directly into the dialog without using the wizard. You may also, of course, modify the settings in the dialog prior to continuing. For example, click on the Panel Options tab and check the No d.f. correction setting in the covariance calculation to match the original Arellano-Bond results (Table 4(b), p. 290). Click on OK to estimate the specification.
The top portion of the output describes the estimation settings, coefficient estimates, and summary statistics. Note that both the weighting matrix and covariance calculation method used are described in the top portion of the output.
Dependent Variable: N
Method: Panel Generalized Method of Moments
Transformation: First Differences
Date: 05/29/03 Time: 11:50
Sample (adjusted): 1978 1984
Number of cross-sections used: 140
Total panel (unbalanced) observations: 611
White period instrument weighting matrix
Linear estimation after one-step weighting
Instrument list: W W(-1) K YS YS(-1) @DYN(N) @LEV(@SYSPER)
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
|
|
|
|
|
|
|
|
|
N(-1) |
0.474150 |
0.085303 |
5.558409 |
0.0000 |
N(-2) |
-0.052968 |
0.027284 |
-1.941324 |
0.0527 |
W |
-0.513205 |
0.049345 |
-10.40027 |
0.0000 |
W(-1) |
0.224640 |
0.080063 |
2.805796 |
0.0052 |
K |
0.292723 |
0.039463 |
7.417748 |
0.0000 |
YS |
0.609775 |
0.108524 |
5.618813 |
0.0000 |
YS(-1) |
-0.446371 |
0.124815 |
-3.576272 |
0.0004 |
@LEV(@ISPERIOD("1979")) |
0.010509 |
0.007251 |
1.449224 |
0.1478 |
@LEV(@ISPERIOD("1980")) |
0.014142 |
0.009959 |
1.420077 |
0.1561 |
@LEV(@ISPERIOD("1981")) |
-0.040453 |
0.011551 |
-3.502122 |
0.0005 |
@LEV(@ISPERIOD("1982")) |
-0.021640 |
0.011891 |
-1.819843 |
0.0693 |
@LEV(@ISPERIOD("1983")) |
-0.001847 |
0.010412 |
-0.177358 |
0.8593 |
@LEV(@ISPERIOD("1984")) |
-0.010221 |
0.011468 |
-0.891270 |
0.3731 |
|
|
|
|
|
|
|
|
|
|