

4.4. Регрессионный анализ
Регрессионный анализ служит для нахождения по результатам эксперимента связи выходной характеристики устройства (процесса) с факторами, которые влияют на эту характеристику.
В качестве модели регрессии используются прямая линия или различные математические кривые: участки параболы, гиперболы, экспоненты и т.п. Экспериментальные данные могут быть аппроксимированы с требуемой точностью функциями различного вида, поэтому выбор вида функции не может быть формализован. Его осуществляет экспериментатор, руководствуясь следующими соображениями: регрессионная модель должна быть простой, удобной для дальнейшего использования и адекватной. Под адекватностью модели понимают ее способность предсказывать с требуемой точностью значения у в некоторой области значений х. Вид модели выбирают таким образом, чтобы при обязательном соблюдении адекватности она была наиболее простой и удобной.
На практике во многих случаях приближенно («на глаз») графически проводят линию, описывающую зависимость среднего значения у от х, и, исходя из ее вида, выбирают регрессионную модель.
Очень часто зависимость y от x можно принять линейной (линейная модель):
 (4.4.1)
(4.4.1)
Для упрощения способов нахождения коэффициентов регрессии важно принять следующие допущения:
1. результаты наблюдений у1, у2, ..., уi, ..., уп (где п – число наблюдений над величиной y) представляют собой независимые, нормально распределенные случайные величины;
2. дисперсии D(yi) равны друг другу, или пропорциональны какой-то известной функции Ф(y);
3. переменные х1, x2, ..., xk являются независимыми и измеряются с пренебрежимо малой погрешностью по сравнению с величиной [yi].
Методы вычисления коэффициентов регрессии базируются обычно на аппарате матричного исчисления; при этом в наиболее громоздких случаях используются стандартные программы на ЭВМ.
Результаты эксперимента записываются в виде матрицы наблюдавшихся значений:
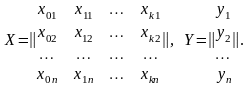 (4.4.2)
(4.4.2)
По этим данным можно найти точечные оценки коэффициентов регрессии. Для этого, используя метод наименьших квадратов, составляют n несовместных уравнений:
 (4.4.3)
(4.4.3)
Из этой системы уравнений можно определить (k + 1) коэффициентов регрессии. Решение делают в матричной форме. Всю систему уравнений записывают в матричной форме в виде ХA = Y, где:
 (4.4.4)
(4.4.4)
Матрицу
 при этом
определяют из уравнения
при этом
определяют из уравнения
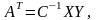 (4.4.5)
(4.4.5)
где
– транспонированная матрица A;
 – обратная матрица произведения
С = ХТХ,
равная
= (ХТХ)-1.
В
соответствии
с
этим уравнением для получения матрицы
A
(а
значит, и всех оценок коэффициентов
регрессии) необходимо произвести ряд
преобразований, которые хотя и
являются стандартными в матричном
исчислении, но в общем виде не наглядны,
поэтому ход таких вычислений
представлен ниже на конкретном числовом
примере.
– обратная матрица произведения
С = ХТХ,
равная
= (ХТХ)-1.
В
соответствии
с
этим уравнением для получения матрицы
A
(а
значит, и всех оценок коэффициентов
регрессии) необходимо произвести ряд
преобразований, которые хотя и
являются стандартными в матричном
исчислении, но в общем виде не наглядны,
поэтому ход таких вычислений
представлен ниже на конкретном числовом
примере.
Пример 4.4.1. Результаты эксперимента представлены в таблице.
N |
x1 |
x2 |
y |
N |
x1 |
x2 |
y |
N |
x1 |
x2 |
y |
1 |
0 |
0 |
10 |
4 |
1 |
0 |
14 |
7 |
2 |
2 |
40 |
2 |
0 |
1 |
17 |
5 |
2 |
0 |
18 |
8 |
0 |
-1 |
3 |
3 |
0 |
2 |
20 |
6 |
1 |
1 |
24 |
9 |
-1 |
-1 |
3 |
Число факторов k = 2. Количество опытов п = 9.
Необходимо провести регрессионный анализ, определив значения коэффициентов регрессии.
Решение. Пусть полином для функции у (модель) линейный:
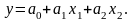
Составим матрицу X и транспонированную матрицу:
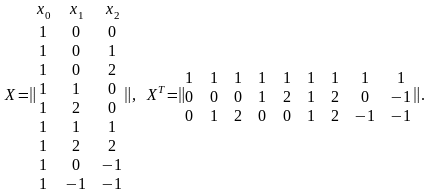
Найдем произведение
 ,
складывая почленно произведения
элементов строк
и столбцов X:
,
складывая почленно произведения
элементов строк
и столбцов X:
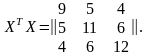
Для вычисления обратной матрицы (ХТХ)–1 найдем сначала определитель матрицы ХТХ:
= 9 (11 12 – 6 6) – 5 (5 12 – 4 6) + 4 (5 6 – 4 11) = 628.
Матрицу (ХТХ)–1 составим из определителя и дополнений матрицы ХТХ:
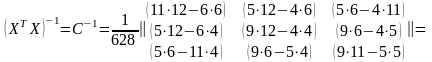
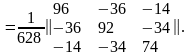
Далее запишем матрицу Y и найдем произведение ХТY:
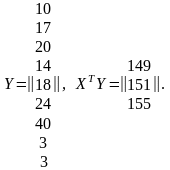
Далее

Таким образом: a0 = 10,65; a1 = 5,2; a2= 6,8, и уравнение регрессии получает следующий конкретный вид:
y = 10,65 + 5,2 х1 + 6,8 х2.
Далее необходимо проихвести проверку адекватности полученного уравнения опытным данным. Это необходимо, так как вид зависимости был заранее неизвестен и выбирался наиболее простой.
Адекватность проверяют обычно по критерию Фишера F:
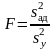 . (4.4.6)
. (4.4.6)
Оценку
дисперсий
 и
и
 производят по формулам
производят по формулам
 , (4.4.7)
, (4.4.7)
где
 – измеренное значение величины y,
– измеренное значение величины y,
 –
расчетное значение величины y,
вычисленное
по полученному уравнению регрессии
при подстановке в него опытных значений
xj;
k
– количество
коэффициентов в уравнении регрессии;
п
– количество опытов;
п
–
k
=
f
–
число степеней свободы,
–
расчетное значение величины y,
вычисленное
по полученному уравнению регрессии
при подстановке в него опытных значений
xj;
k
– количество
коэффициентов в уравнении регрессии;
п
– количество опытов;
п
–
k
=
f
–
число степеней свободы,
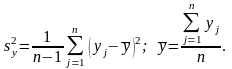 (4.4.8)
(4.4.8)
Критерий F
(таблица П. 4.
«Значения
 (верхние значения) и
(верхние значения) и
 (нижние значения) для различных степеней
свободы f1
и f2»)
позволяет
сравнить общий разброс относительно
линии регрессии с разбросом в точке.
Задавая уровень значимости q
(обычно q
выбирают равным
0,05), по таблице Фишера для (п
– k)
степеней
свободы находят значение критерия
F.
Если оно больше
вычисленного выше, то полученная в виде
уравнения регрессии модель адекватна
результатам эксперимента, если же нет
– то требуется выбрать другой, более
сложный вид уравнения. Однако здесь
необходимо соблюдать условие, чтобы
число опытов было не меньше числа
оцениваемых коэффициентов.
(нижние значения) для различных степеней
свободы f1
и f2»)
позволяет
сравнить общий разброс относительно
линии регрессии с разбросом в точке.
Задавая уровень значимости q
(обычно q
выбирают равным
0,05), по таблице Фишера для (п
– k)
степеней
свободы находят значение критерия
F.
Если оно больше
вычисленного выше, то полученная в виде
уравнения регрессии модель адекватна
результатам эксперимента, если же нет
– то требуется выбрать другой, более
сложный вид уравнения. Однако здесь
необходимо соблюдать условие, чтобы
число опытов было не меньше числа
оцениваемых коэффициентов.
Если число опытов в каждой точке (т.е. при каждом сочетании значений факторов) больше единицы и различно, то находят по формуле:
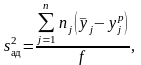 (4.4.9)
(4.4.9)
где
nj
–
число параллельных (повторных) опытов
в j-й
строке матрицы;
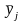 –
среднее
арифметическое из nj
параллельных
опытов. Из этой формулы видно, что
различие между экспериментальным и
расчетным значениями имеет тем большее
значение, чем больше число повторных
опытов.
–
среднее
арифметическое из nj
параллельных
опытов. Из этой формулы видно, что
различие между экспериментальным и
расчетным значениями имеет тем большее
значение, чем больше число повторных
опытов.
Следующий этап анализа состоит в проверке значимости коэффициентов. Его можно осуществлять двумя равноценными способами: проверкой по t-критерию Стьюдента или построением доверительного интервала. Если опытные данные получены в результате полного факторного эксперимента или регулярных дробных реплик, то доверительные интервалы для всех коэффициентов (в том числе и эффектов взаимодействия) равны друг другу.
На этом этапе найдем сначала дисперсию коэффициента регрессии s2 (aj) по формуле:
 (4.4.10)
(4.4.10)
Дисперсии всех коэффициентов равны друг другу, так как они зависят только от погрешности измерений и числа опытов. Доверительный интервал для j-го коэффициента определяется по формуле
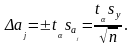 (4.4.11)
(4.4.11)
Здесь
 – квантиль распределения Стьюдента
при числе степеней свободы, с которыми
определялась дисперсия для вероятности,
равной выбранному уровню значимости.
– квантиль распределения Стьюдента
при числе степеней свободы, с которыми
определялась дисперсия для вероятности,
равной выбранному уровню значимости.
Коэффициент значим, если его абсолютная величина больше доверительного интервала, т.е. если его среднее влияние на у больше, чем разбросы за счет неточности модели и «мешающих» факторов.
Очень часто в качестве модели используют степенной полином вида
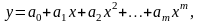 (4.4.12)
(4.4.12)
где а1, а2, ..., ат – параметры модели.
Такая модель при правильном выборе степени полинома позволяет с любой необходимой точностью аппроксимировать любую истинную регрессионную зависимость. Достоинством модели является также то, что функция линейна относительно неизвестных параметров a0, а1, а2, ..., аm, что упрощает обработку наблюдений. В данном случае вопрос выбора вида модели сводится к выбору порядка m полинома.
После выбора вида регрессионной модели вычисляют ее параметры. Для модели (4.4.12) необходимо получить оценки параметров a0, а1, а2, ..., аm, что можно сделать на основе метода, рассмотренного в § 3.5.
Предположим,
что yi
(i
= 1, 2, ..., п)
– это значения
выходного параметра объекта, определяемые
регрессионной зависимостью от xi,
а li
– соответствующие результаты измерений
выходного параметра. Разность
 в общем
случае отлична от нуля из-за наличия
погрешностей измерения и возмущающих
воздействий на объект исследования.
в общем
случае отлична от нуля из-за наличия
погрешностей измерения и возмущающих
воздействий на объект исследования.
Здесь и далее считаем, что отклонение аддитивно (не зависит от значения у) и распределено нормально с нулевым математическим ожиданием.
Для регрессионной модели (4.4.12) запишем систему нормальных уравнений:
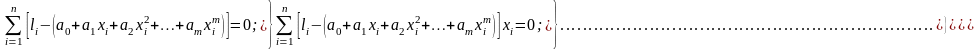 (4.4.13)
(4.4.13)
Преобразовав (4.4.13) к стандартному виду, получим:
 (4.4.15)
(4.4.15)
В результате решения системы уравнений (4.4.15), линейных относительно искомых параметров a0, а1, а2, ..., аm, получим их оценки
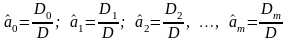 ,
,
где

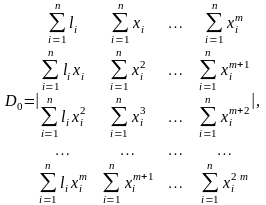

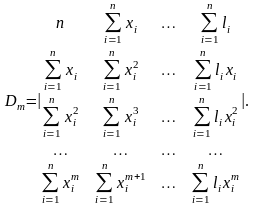
Бывает так, что модель нелинейной регрессионной зависимости целесообразно искать в виде функции, отличной от степенного полинома (4.4.12), например, в виде
 (4.4.16)
(4.4.16)
который содержит два неизвестных параметра а и b. Применение полинома (4.4.12) при той же точности модели может потребовать более высокого порядка полинома, что повышает трудоемкость вычислений.
Однако
использование таких нелинейных
(относительно параметров) функций
осложняет вычисление их параметров. В
некоторых частных случаях решение
задачи упрощается, если искусственно
преобразовать нелинейную модель в
линейную. Например, для функции (4.3.16)
необходимо сделать замену переменной
вида
 Тогда получим линейную модель
Тогда получим линейную модель
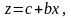 (4.4.17)
(4.4.17)
где
 .
.
При
этом необходимо соответственно
преобразовать исходные экспериментальные
данные – вычислить совокупность
значений z.
Затем методом наименьших квадратов
находят оценки
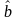 и
и
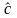 параметров линейной модели (4.4.17) и
осуществляют обратный переход к
нелинейной модели (4.4.16).
параметров линейной модели (4.4.17) и
осуществляют обратный переход к
нелинейной модели (4.4.16).