


Глава
Иерархический кластерный анализ
25
Эта процедура предназначена для выявления относительно однородных групп наблюдений (или переменных) по заданным характеристикам при помощи алгоритма, который вначале рассматривает каждое наблюдение (переменную) как отдельный кластер, а затем последовательно объединяет кластеры, пока не останется только один. Можно анализировать исходные переменные или воспользоваться набором стандартизирующих преобразований. Расстояния или меры сходства формируются процедурой Расстояния (Proximities). Чтобы помочь в выборе наилучшего решения, на каждом шаге выводятся разнообразные статистики.
Пример. Можно ли разбить телевизионные шоу на группы, так чтобы в каждой группе зрители, которых они привлекают, были схожи? С помощью иерархического кластерного анализа Вы можете разделить (кластеризовать) телевизионные шоу (наблюдения) на однородные группы, исходя из характеристик их зрителей. Это можно использовать при сегментации рынка. Или Вы можете разбить города (наблюдения) на однородные группы, что позволит отбирать сравнимые города для проверки различных маркетинговых стратегий.
Статистики. Порядок агломерации, матрица расстояний (или сходств) и состав кластеров для одного решения или диапазона решений. Графики: дендрограммы и сосульчатые диаграммы.
Данные. Переменные могут быть количественными, бинарными или частотами. Масштаб измерения переменных важен — различия в масштабах могут повлиять на полученные кластерные решения. Если масштаб переменных сильно различается (например, одна переменная измерена в долларах, а другая — в годах), то следует подумать об их стандартизации (она может быть проведена автоматически с помощью процедуры Иерархическая кластерный анализ).
Порядок наблюдений. Если во входных данных существуют совпадающие расстояния или сходства или они появляются в обновленных кластерах в процессе объединения, то результирующее кластерное решение может зависеть от порядка наблюдений в файле Возможно, что вы захотите получить несколько различных решений с наблюдениями, упорядоченными случайным образом, чтобы проверить стабильность данного решения.
Предположения. Используемые расстояния или меры сходства должны соответствовать анализируемым данным (более полную информацию относительно выбора расстояний и мер сходства можно найти в описании процедуры Proximities (Расстояния)). Кроме того, в анализ необходимо включать все переменные, имеющие отношение к проблеме.
Игнорированиеважныхпеременныхможетпривестикрешению, вводящемувзаблуждение. Поскольку иерархический кластерный анализ является разведочным методом, его результаты следует считать предварительными, пока они не будут подтверждены на независимой выборке.
© Copyright IBM Corporation 1989, 2011. |
200 |

201
Иерархический кластерный анализ
Как запустить процедуру Иерархический кластерный анализ
E Выберите в меню:
Анализ > Классификация > Иерархическая кластеризация...
Рисунок 25-1
Диалоговое окно Иерархический кластерный анализ
EЕсли Вы кластеризуете наблюдения, выберите, по крайней мере, одну числовую переменную. При кластеризации переменных выберите, по крайней мере, три числовые переменные.
По желанию можно выбрать идентифицирующую переменную для вывода меток наблюдений.
202
Глава 25
Задание метода иерархического кластерного анализа
Рисунок 25-2
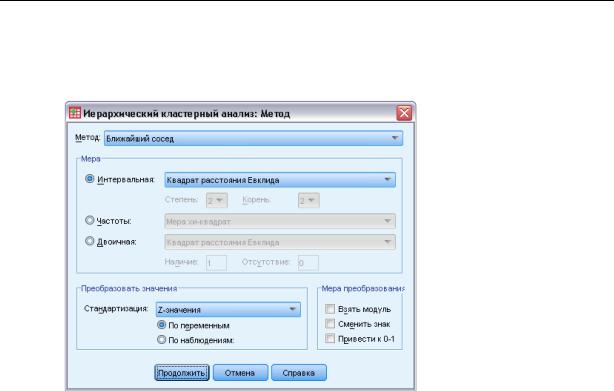
Диалоговое окно Иерархический кластерный анализ: Метод
Метод кластеризации. Возможные альтернативы: Межгрупповые связи, Внутригрупповые связи, Ближайший сосед, Дальний сосед, Центроидная кластеризация, Медианная кластеризация, Метод Варда.
Мера. Позволяет задать расстояние или меру сходства, которые будет использованы при кластеризации. Выберите тип данных и соответствующее расстояние или меру сходства:
Интервальная. Возможные альтернативы: Евклидово расстояние, Квадрат расстояния Евклида, Косинус, Корреляция Пирсона, Чебышев, Блок, Минковского, Настроенная.
Частоты. Возможные альтернативы: Мера хи-квадрат и Мера фи-квадрат.
Бинарная. Имеющиеся альтернативы: Евклидово расстояние, Квадрат расстояния Евклида, Различие размеров, Различие структур, Дисперсия, Разброс, Форма, Простая совпадений, 4-точечная корреляция фи, Лямбда, D Андерберга, Дайс, Хаманн, Жаккар, Кульчинский 1, Кульчинский 2, Ланс и Виллиамс, Очиай, Роджерс и Танимото, Рассел и Рао, Сокал и Сниат 1, Сокал и Сниат 2, Сокал и Сниат 3, Сокал и Сниат 4, Сокал и Сниат 5, Y Юла и Q Юла.
Преобразовать значения. Позволяет стандартизировать значения данных либо для наблюдений, либо для переменных до вычисления близостей (недоступно для бинарных данных). Возможные методы стандартизации: Z значения, Диапазон от −1 до 1, Диапазон от 0 до 1, Максимальная величина 1, Среднее 1 и Стд. отклонение 1
Преобразовать меры. Позволяет преобразовать значения, порожденные мерой расстояния. Преобразования выполняются после того, как вычислены значения меры расстояния. Возможные варианты преобразований: Взять модуль, Сменить знак, Привести к 0–1.
203
Иерархический кластерный анализ
Статистики для процедуры Иерархический кластерный анализ
Рисунок 25-3
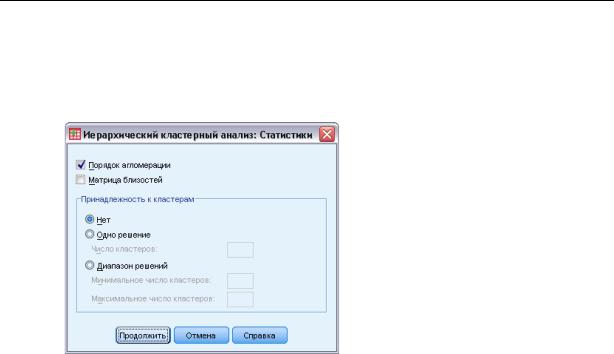
Диалоговое окно Иерархический кластерный анализ: Статистики
Порядок агломерации. Выводятся наблюдения или кластеры, объединяемые на каждом этапе, расстояния между объединяемыми наблюдениями или кластерами и уровень кластеризации, на котором к кластеру последний раз добавлялось наблюдение (или переменная).
Матрица близостей. Выводятся расстояния или сходства между объектами.
Принадлежность к кластерам. Выводится кластер, к которому отнесено каждое наблюдение для одного или нескольких этапов объединения кластеров. Возможными вариантами являются одно решение и диапазон решений.