


Глава
Дискриминантный анализ
21
При дискриминантном анализе происходит создание прогностической модели для принадлежности к группе. Данная модель строит дискриминантную функцию (или, когда групп больше двух, набор дискриминантных функций) в виде линейной комбинации предикторных переменных, обеспечивающую наилучшее разделение групп. Эти функции строятся по набору наблюдений, для которых их принадлежность к группам известна, и могут в дальнейшем применяться к новым наблюдениям с известными значениями предикторных переменных, но неизвестной групповой принадлежностью.
Примечание: Группирующая переменная может иметь более чем два значения. Коды для группирующей переменной должны быть целыми, однако вам необходимо задать их максимальное и минимальное значения. Наблюдения со значениями вне этих границ исключаются из анализа.
Пример. Люди в странах с умеренным климатом ежедневно потребляют в среднем больше калорий, чем живущие в тропиках, а большая часть населения в странах с умеренным климатом живет в городах. Исследователь желает построить на основе данной информации функцию для определения того, насколько хорошо можно разделить индивидуумов по этим двум группам стран (на основе данной информации). Исследователь считает, что также важными факторами могут явиться количество населения в стране и ее экономические показатели. Дискриминантный анализ позволяет оценить коэффициенты линейной дискриминантной функции, напоминающей правую часть уравнения множественной линейной регрессии. Если обозначить коэффициенты дискриминантной функции как a, b, c и d, то ее можно записать в следующем виде:
D=a*климат +b*горожанин ли +c*население +d*валовой внутренний продукт на душу населения
Если данные переменные являются существенными для разделения двух климатических зон, значения D будут различными для стран с умеренным и тропическим климатом. При использовании метода пошагового отбора переменных может оказаться, что нет необходимости включать в функцию все четыре переменные.
Статистики. Для каждой переменной: средние значения, стандартные отклонения, однофакторный дисперсионный анализ Для каждой переменной: M - статистика Бокса, внутригрупповая корреляционная матрица, внутригрупповая ковариационная матрица, ковариационные матрицы для отдельных групп, общая ковариационная матрица. Для каждой канонической дискриминантной функции: собственное значение, процент дисперсии, каноническая корреляция, лямбда Уилкса, хи-квадрат. Для каждого шага: априорные вероятности, коэффициенты функции Фишера, нестандартизованные коэффициенты функции, лямбда Уилкса для каждой канонической функции.
© Copyright IBM Corporation 1989, 2011. |
163 |
164
Глава 21
Данные. Группирующая переменная должна иметь ограниченное число различных категорий, кодированных целыми числами. Независимые переменные, являющиеся номинальными, должны быть перекодированы в фиктивные переменные или переменные контрастов.
Предположения. Наблюдения должны быть независимыми. Предикторные переменные должны подчиняться многомерному нормальному распределению, а внутригрупповые ковариационные матрицы должны совпадать для всех групп. Групповая принадлежность предполагается взаимоисключающей (т.е. ни одно наблюдение не принадлежит более чем одной группе) и совместно исчерпывающей (т.е. каждое наблюдение принадлежит какой-либо группе). Процедура наиболее эффективна в ситуации, когда группирующая переменная является истинно категориальной; если принадлежность к группе определяется значениями непрерывной переменной (например, высокий IQ (коэффициент интеллекта) низкий IQ ), то имеет смысл обратиться к линейной регрессии, чтобы воспользоваться преимуществом большей информативности непрерывной переменной.
Для выполнения дискриминантного анализа
E Выберите в меню:
Анализ > Классификация > Дискриминантный анализ...
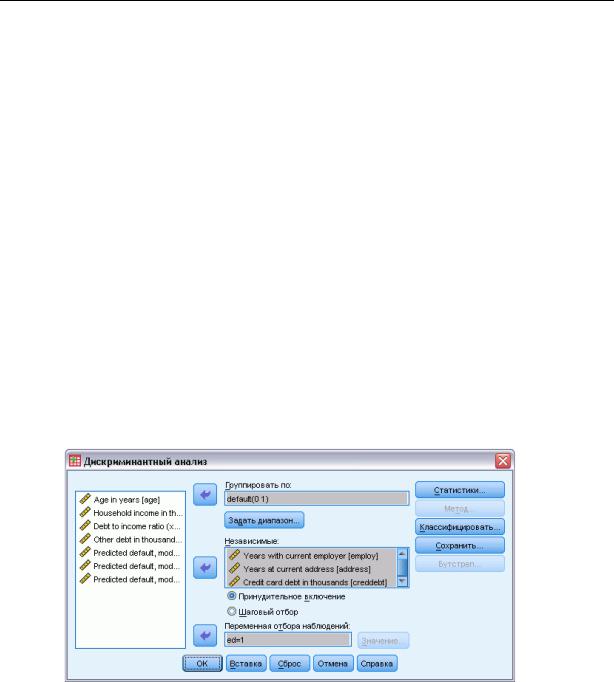
Рисунок 21-1
Диалоговое окно Дискриминантный анализ
EВыберите целочисленную группирующую переменную и щелкните мышью по кнопке Задать диапазон, чтобы задать нужные категории.
EВыберите независимые или предикторные переменные. (Если у группирующей переменной нет целых значений, то переменная с целыми значениями может быть создана с помощью пункта Автоматическая перекодировка меню Преобразовать.)
E Выберите метод ввода независимых переменных.
165
Дискриминантный анализ
Вводить независимые вместе. Одновременно вводятся все независимые переменные, удовлетворяющие критериям допуска (толерантности).
Шаговый отбор. Для включения и исключения переменных используется шаговый метод.
E При желании вы можете осуществить отбор наблюдений при помощи переменной отбора.
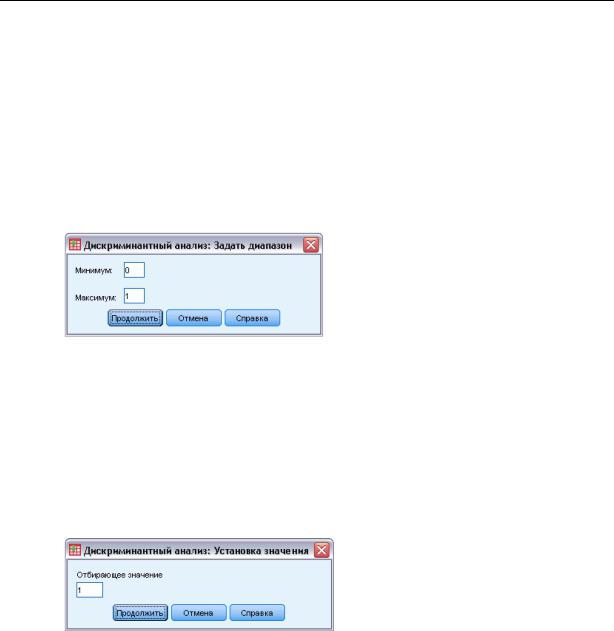
Задание диапазона в процедуре Дискриминантный анализ
Рисунок 21-2
Диалоговое окно Дискриминантный анализ: Задать диапазон
Укажите минимальное и максимальное значения группирующей переменной. Наблюдения со значениями вне заданного диапазона не будут использованы в дискриминантном анализе, но будут отнесены в одну из имеющихся групп на основании результатов анализа. Минимальное и максимальное значения должны быть целочисленными.
Отбор наблюдений для процедуры дискриминантного анализа
Рисунок 21-3
Диалоговое окно Дискриминантный анализ: Установка значения
Как отобрать наблюдения для анализа
E В диалоговом окне Дискриминантный анализ выберите переменную отбора.
EЩелкните по Значение, чтобы ввести целое число в качестве значения отбора.
При построении дискриминантных функций используются только наблюдения с заданным значением переменной отбора. Статистики и результаты классификации выводятся как для отобранных, так и не отобранных наблюдений. Это предоставляет механизм для классификации новых наблюдений на основе ранее существовавших данных или для разделения ваших данных на обучающее и контрольное подмножества, чтобы выполнить проверку адекватности построенной модели.
166
Глава 21
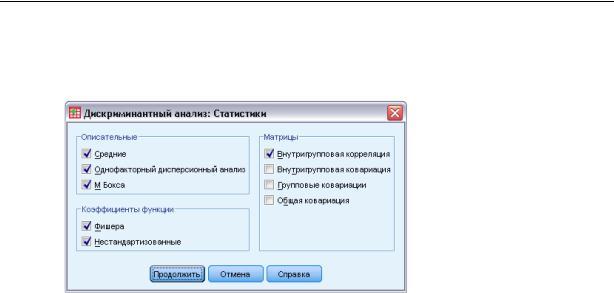
Статистики в процедуре Дискриминантный анализ
Рисунок 21-4
Диалоговое окно Дискриминантный анализ: Статистики
Описательные статистики. Доступны параметры: средние значения (включая стандартные отклонения), одномерный дисперсионный анализ, а также M-критерий Бокса.
Средние. Выводятся общее и групповые средние, а также стандартные отклонения для независимых переменных.
Одномерный дисперсионный анализ. Проводит однофакторный дисперсионный анализ для проверки гипотезы о равенстве групповых средних для каждой независимой переменной.
M Бокса. Критерий равенства групповых ковариационных матриц. Если p не значимо, а выборка достаточно велика, то нет достаточных свидетельств того, что матрицы различаются. Этот критерий чувствителен к отклонениям от многомерной нормальности.
Коэффициенты функции. Возможен вывод классификационных коэффициентов Фишера и нестандартизованных коэффициентов.
Фишера. Коэффициенты классифицирующей функции Фишера, которые можно напрямую использовать для классификации. Для каждой группы создается отдельный набор коэффициентов, при этом наблюдение относится к группе, которой соответствует наибольшее значение дискриминантной функции (значение классифицирующей функции).
Нестандартизованные. Вывод нестандартизованных значений коэффициентов дискриминантной функции.
Матрицы. Доступными матрицами коэффициентов для независимых переменных являются: внутригрупповая корреляционная матрица, внутригрупповая ковариационная матрица, ковариационные матрицы для отдельных групп и общая ковариационная матрица.
Внутригрупповая корреляция. Выводится объединенная внутригрупповая корреляционная матрица, полученная путем усреднения ковариационных матриц отдельных групп перед вычислением корреляций.