

204
Глава 25
Графики для процедуры Иерархический кластерный анализ
Рисунок 25-4
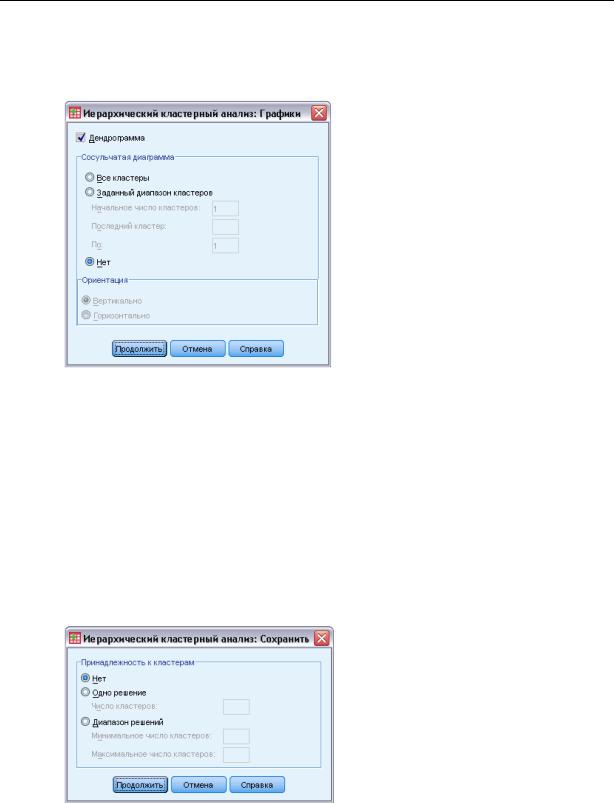
Диалоговое окно Иерархический кластерный анализ: Графики
Дендрограмма. Выводится дендрограмма . Дендрограммы могут использоваться при исследовании взаимного притяжения формируемых кластеров и предоставить информацию о том, какое число кластеров сохранить.
Сосульчатый. Выводится сосульчатая диаграмма для всех кластеров или кластеров из заданного диапазона. Cосульчатые диаграммы дают информацию о том, как наблюдения объединяются в кластеры на каждой итерации анализа. Панель Ориентация позволяет выбрать между вертикальной и горизонтальной диаграммами.
Сохранение новых переменных в процедуре Иерархический кластерный анализ
Рисунок 25-5
Диалоговое окно Иерархический кластерный анализ: Сохранить

205
Иерархический кластерный анализ
Принадлежность к кластерам. Позволяет сохранить принадлежность к кластерам для одного решения или диапазона решений. Сохраненные переменные можно затем использовать в последующем анализе для изучения других различий между группами.
Дополнительные возможности синтаксиса команды
CLUSTER
Процедура иерархической кластеризации использует синтаксис команды CLUSTER. Язык синтаксиса команд также позволяет:
Использовать несколько методов кластеризации за один прогон процедуры.
Считывать и анализировать матрицу близостей.
Сохранять матрицу близостей для дальнейшего анализа.
Задавать любые значения порядков и корней для настраиваемой (степенной) меры расстояния.
Задавать имена сохраняемых переменных.
Полную информацию о синтаксисе языка команд можно найти в Руководстве по синтаксису.

Глава
Кластерный анализ методом K26 средних
Эта процедура пытается выявить относительно однородные группы наблюдений на основе выбранных характеристик, используя алгоритм, позволяющий обработать большое число наблюдений. Однако этот алгоритм требует указания числа кластеров. Вы можете задать начальные центры кластеров, если такая информация вам доступна. Вы можете выбрать один из двух методов классификации наблюдений, либо итеративно обновляя центры кластеров, либо ограничиваясь только классификацией. Вы можете сохранить принадлежность к кластерам, информацию о расстояниях и окончательные центры кластеров. Дополнительно Вы можете задать переменную, значения которой будут использоваться в качестве меток наблюдений при выводе результатов. Вы можете также запросить вывод F-статистик дисперсионного анализа. Относительные величины этих статистик дают информацию о вкладе каждой переменной в разделение групп.
Пример. Можно ли разбить телевизионные шоу на группы, так чтобы в каждой группе зрители, которых они привлекают, были схожи? С помощью кластерного анализа методом k-средних Вы можете разделить (кластеризовать) телевизионные шоу (наблюдения) на
k однородных групп, исходя из характеристик их зрителей. Это можно использовать при сегментации рынка. Или Вы можете разбить города (наблюдения) на однородные группы, что позволит отбирать сравнимые города для проверки различных маркетинговых стратегий.
Статистики. Полное решение: начальные центры кластеров, таблица дисперсионного анализа. Для каждого наблюдения: информация о кластерах, расстояние от центра кластера.
Данные. Переменные должны быть количественными и измеренными в интервальной шкале или шкале отношений. Если переменные являются бинарными или частотами, воспользуйтесь процедурой Иерархический кластерный анализ.
Порядок наблюдений и начальных центров кластеров. Алгоритм, используемый по умолчанию для выбора начальных центров кластеров, не является инвариантным относительно порядка наблюдений. Параметр Использовать скользящие средние в диалоговом окне Итерации делает получающееся в результате решение потенциально
зависимым от порядка наблюдений, независимо от того, как выбираются начальные центры кластеров. При использовании любого из этих методов, вы, возможно, захотите получить несколько различных решений с наблюдениями, расположенными в случайном порядке, чтобы удостовериться в стабильности данного решения. Задание начальных центров кластеров и не использование параметра Использовать скользящие средние позволит избежать проблем, связанных с порядком наблюдений. Однако упорядочение начальных центров кластеров может повлиять на решение, если имеются совпадающие расстояния от наблюдений до центров кластеров. Чтобы оценить стабильность данного решения, можно сравнить результаты анализа с различными перестановками значений начальных центров.
© Copyright IBM Corporation 1989, 2011. |
206 |
207
Кластерный анализ методом K средних
Предположения. Для вычисления расстояний используется простое евклидово расстояние. Если необходимо задать другой тип расстояния или меры сходства, обратитесь к процедуре Иерархический кластерный анализ. Масштабирование переменных играет важную роль.
Если ваши переменные имеют различный масштаб измерений (например, одна переменная измерена в долларах, а вторая - в годах), то результаты могут быть некорректными. В этой ситуации необходимо подумать о стандартизации ваших переменных до выполнения кластерного анализа методом k-средних (это можно сделать при помощи процедуры Описательные статистики). Предполагается, что выбрано подходящее число кластеров, а в анализ включены все существенные переменные. Если Вы неправильно выбрали число кластеров или не включили важные переменные, то полученные результаты также могут ввести Вас в заблуждение.
Как запустить Кластерный анализ методом k-средних
E Выберите в меню:
Анализ > Классификация > Кластеризация К-средними...
Рисунок 26-1
Диалоговое окно Кластерный анализ методом K средних
E Выберите переменные для использования в кластерном анализе.
EЗадайте число кластеров. (Оно должно быть не меньше двух и не больше числа наблюдений
вфайле данных.)
E Выберите либо метод Итерации и классификация, либо метод Только классификация.