

Глава
Линейные модели
15
Линейные модели предсказывают значения непрерывных целевых переменных, основываясь на взаимосвязи между целевой переменной и одним или несколькими предикторами.
Линейные модели относительно просты и дают легко интерпретируемую математическую формулу для скоринга. Свойства этих моделей хорошо понятны, и их обычно можно построить очень быстро, по сравнению с моделями других типов (такими как нейронные сети или деревья решений) на том же наборе данных.
Пример. Страховая компания с ограниченными ресурсами для исследования страховых требований домовладельцев желает построить модель для оценки стоимости требований. Применяя эту модель в центрах обслуживания, сотрудники компании могут ввести информацию от требовании, разговаривая по телефону с клиентом, и немедленно получить “ожидаемую” стоимость требования, основываясь на прошлых данных.
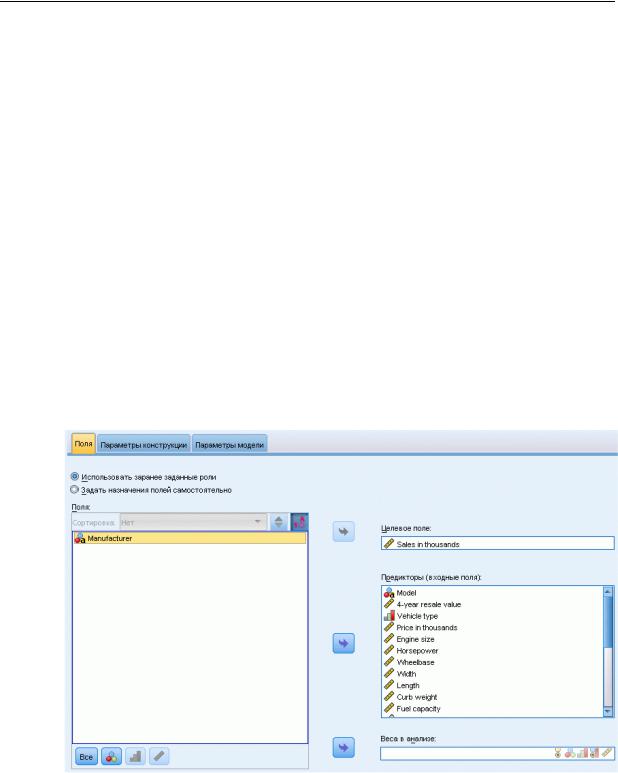
Рисунок 15-1
Вкладка Поля
Требования к полям. Должны быть целевое и, по крайней мере, одно входное поля. По умолчанию не используются поля с предопределенными ролями Двойного назначения и Нет. Целевое поле должно быть непрерывным (количественным). Для предикторов (входные) отсутствуют ограничения на тип измерений; категориальные (номинальные
© Copyright IBM Corporation 1989, 2011. |
91 |
92
Глава 15
и порядковые) поля используются в модели в качестве факторов, а непрерывные поля используются как ковариаты.
Примечание: если категориальное поле содержит более 1000 категорий, то процедура не выполняется, и модель не строится.
Как запустить процедуру построения линейной модели
Для этой процедуры требуется модуль Statistics Base.
Выберите в меню:
Анализ > Регрессия > Автоматизированные линейные модели...
E Удостоверьтесь, что есть, по крайней мере, одна целевая и одна входная переменная.
EЩелкните по Параметры конструкции , чтобы задать необязательные параметры сборки
имодели.
EЩелкните по Параметры модели , чтобы сохранить оценки в активном наборе данных и экспортировать модель во внешний файл.
EЩелкните по Запуск , чтобы запустить процедуру и создать объекты модели.
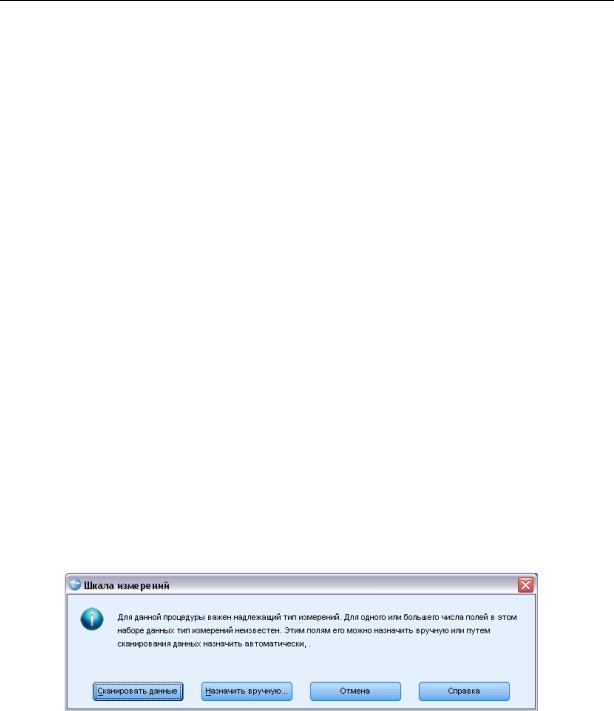
Вслучае, когда тип измерений для одной или нескольких переменных (полей) в наборе данных неизвестен, выводится предупреждающее сообщение о типе измерений. Так как тип измерений влияет на вычисление результатов для этой процедуры, все переменные должны иметь заданный тип измерений.
Рисунок 15-2
Предупреждение о типе измерений
Сканировать данные. Считывает данные в активном наборе данных и назначает тип измерений по умолчанию любым полям с неизвестным типом измерений. Это может занять некоторое время, если набор данных большой.
Назначить вручную. Открывает диалоговое окно, в котором перечисляются все поля
снеизвестным типом измерений. Можно использовать это диалоговое окно, чтобы назначить тип измерений таким полям. Тип измерений можно также назначит на вкладке Переменные Редактора данных.

93
Линейные модели
Поскольку тип измерений важен для этой процедуры, нельзя получить доступ к диалоговому окну, позволяющему запустить эту процедуру, пока для всех полей не будет задан тип измерений.
Цели
Какова Ваша главная цель?
Создать стандартную модель. Данный метод строит единичную модель для предсказания целевой переменной, используя предикторы. Вообще говоря, стандартные модели легче поддаются интерпретации и могут требовать меньше времени при скоринге, чем построенные с применением бустинга, бэггинга или ансамблей больших наборов данных.
Повысить точность модели (бустинг). Данный метод строит модель ансамбля, используя бустинг, который генерирует последовательность моделей для получения более точных предсказаний. Ансамбли могут занять больше времени для их построения и скоринга, чем стандартная модель.
Бустинг генерирует последовательность “компонентных моделей”, каждая из которых строится по целому набору данных. Прежде чем строить каждую последовательную компонентную модель, записи взвешиваются на основе остатков для предшествующей компонентной модели. Наблюдениям с большими остатками придаются относительно большие веса в анализе, с тем чтобы следующая компонентная модель была сконцентрирована на том, чтобы хорошо предсказывать такие записи. Вместе такие компонентные модели образуют модель ансамбля. Модель ансамбля выполняет скоринг новых записей, пользуясь правилом объединения; доступные правила зависят от типа измерений целевой переменной.
Повысить стабильность модели (бэггинг). Данный метод строит модель ансамбля,
используя бэггинг (бутстреп-агрегирование), который генерирует множественные модели для получения более надежных предсказаний. Ансамбли могут занять больше времени для их построения и скоринга, чем стандартная модель.
Бутстреп-агрегирование (бэггинг) формирует реплики обучающего набора данных путем выбора с возвращением из исходного набора данных. В результате создаются бутстреп-выборки исходного набора данных равного объема. Затем по каждой реплике формируется “компонентная модель”. Вместе такие компонентные модели образуют модель ансамбля. Модель ансамбля выполняет скоринг новых записей, пользуясь правилом объединения; доступные правила зависят от типа измерений целевой переменной.
Создать модель для очень больших наборов данных (требуется IBM® SPSS® Statistics Server). Данный метод строит модель ансамбля путем расщепления набора данных на отдельные блоки данных. Выберите этот вариант, если ваш набор данных слишком велик для построения моделей перечисленных выше, или для инкрементного построения модели. Данный вариант может потребовать меньше времени для построения, но больше времени для скоринга, чем стандартная модель. Этот вариант требует соединения с SPSS Statistics Server.

94
Глава 15
Основные параметры
Рисунок 15-3
Основные параметры
Автоматически подготовить данные. Этот параметр позволяет процедуре выполнить внутренние преобразования целевой переменой и предикторов, чтобы максимизировать прогностическую силу модели. Все преобразования сохраняются вместе с моделью и применяются к новым данным при скоринге. Исходные версии преобразованных полей исключаются из модели. По умолчанию выполняются автоматические преобразования данных, описанные ниже.
Обработка дат и времени. Каждый предиктор, являющейся переменной дат, преобразуется в новый непрерывный предиктор, содержащий время, прошедшее, начиная с опорной даты (1970-01-01). Каждый предиктор, являющийся переменной времени, преобразуется в новый непрерывный предиктор, содержащий время, прошедшее, начиная с опорного момента времени (00:00:00).
Корректировка шкалы измерений. Непрерывные предикторы, содержащие менее 5 различных значений, преобразуются в порядковые предикторы. Порядковые
предикторы, содержащие более 10 различных значений, преобразуются в непрерывные предикторы.
Обработка выбросов. Значения непрерывных предикторов, которые лежат вне границ отсечения (определяемых тремя стандартными отклонениями от среднего значения), заменяются значением границы отсечения.
Обработка пропущенных значений. Пропущенные значения номинальных предикторов заменяются модой обучающего разбиения. Пропущенные значения порядковых предикторов заменяются медианой обучающего разбиения. Пропущенные