

208
Глава 26
EДополнительно можно выбрать идентификационную переменную, чтобы метить наблюдения.
Эффективность кластерного анализа методом k-средних
Алгоритм k-средних эффективен прежде всего потому, что он не нуждается в вычислении всех попарных расстояний между наблюдениями, в отличие от большинства других алгоритмов кластеризации, включая тот, что используется в процедуре иерархического кластерного анализа.
Для достижения максимальной эффективности возьмите выборку из наблюдений и используйте метод Итерации и классификация, чтобы определить центры кластеров.
Выберите Записать окончательные в. Затем вернитесь к полному файлу данных и выберите
Только классификация в качестве метода и выберите Прочитать начальные из, чтобы классифицировать весь файл с использованием центров, оцененных по выборке. Вы можете записывать в файл или набор данных, а также считывать из них. Наборы данных доступны для последующего использования в том же сеансе но не сохраняются как файлы до тех пор, пока они не будут сохранены явно до окончания текущего сеанса. Имена наборов данных должны удовлетворять требованиям к именам переменных.
Итерации в кластерном анализе методом k-средних
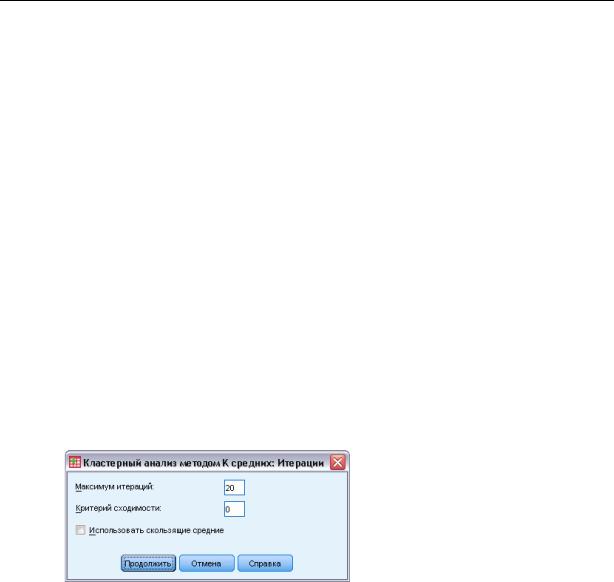
Рисунок 26-2
Диалоговое окно Кластерный анализ методом K средних: Итерации
Примечание: Эти параметры доступны, только если вы выберите метод Итерации и классификация в диалоговом окне Кластерный анализ методом K средних.
Максимум итераций.Ограничивает число итераций для алгоритма k-средних. Алгоритм останавливается после заданного здесь числа итераций, даже если не выполняется критерий сходимости. Это число должно быть от 1 до 999.
Если необходимо воспроизвести алгоритм, использовавшийся командой QUICK CLUSTER в старых версиях (до 5.0), установите Максимум итераций равным 1.
Критерий сходимости. Задает условие прекращения итераций. Оно выражает долю минимального расстояния между начальными центрами кластеров, поэтому должно быть больше 0, но не превышать 1. Если значение критерия равно, например, 0.02, итерации прекращаются, когда полная итерация не сдвигает ни один из центров кластеров на расстояние, превышающее 2% от наименьшего расстояния между центрами любых начальных кластеров.
209
Кластерный анализ методом K средних
Использовать скользящие средние. Позволяет запросить обновление центров кластеров после классификации очередного наблюдения. Если этот пункт не отмечен, новые центры кластеров вычисляются после распределения по кластерам всех наблюдений.
Сохранение новых переменных в кластерном анализе методом k-средних
Рисунок 26-3
Диалоговое окно Кластерный анализ методом K средних: Сохранить новые переменные
Вы можете сохранить следующую информацию о решении в виде новых переменных для использования в последующем анализе:
Принадлежность к кластеру. Создается новая переменная, показывающая окончательную принадлежность каждого наблюдения к кластеру. Значения этой новой переменной могут меняться от 1 до числа кластеров.
Расстояние от центра кластера. Создается новая переменная, показывающая евклидово расстояние между каждым наблюдением и центром кластера, куда оно было отнесено.
Параметры процедуры Кластерный анализ методом К-средних
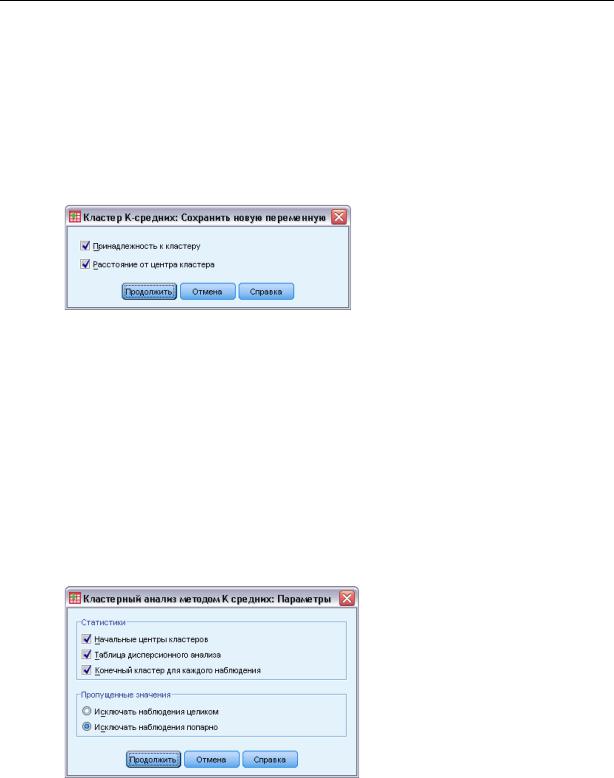
Рисунок 26-4
Диалоговое окно Кластерный анализ методом K средних: Параметры
Статистики. Вы можете выбрать следующие статистики: начальные центры кластеров, таблица дисперсионного анализа, а также информация о принадлежности к кластерам для каждого наблюдения.

210
Глава 26
Начальные центры кластеров. Начальная оценка положения средних для каждого кластера. По умолчанию, отбираются объекты, находящиеся на значительном расстоянии друг от друга, причем столько, сколько задано кластеров. Начальные центры кластеров используются на первом этапе грубой классификации, а затем обновляются.
Таблица дисперсионного анализа. Выводится таблица дисперсионного анализа, включающая одномерный F-критерий для каждой кластерной переменной. F-критерий приводится для чисто ориентировочных целей, и выдаваемые вероятности не подлежат интерпретации. Таблица не выдается, если все наблюдения попадают в один кластер.
Конечный кластер для каждого наблюдения. Для каждого наблюдения указывается финальный кластер, к которому оно отнесено, и евклидово расстояние до центра этого кластера. Выводится также евклидово расстояние между центрами финальных кластеров.
Пропущенные значения. Возможными альтернативами являются Исключать целиком и Исключать наблюдения попарно.
Исключать целиком. Наблюдения с пропущенными значениями в любой из кластерных переменных исключаются из анализа.
Исключать попарно. Наблюдения относятся к кластерам на основании расстояний, вычисленных по всем переменным с непропущенными значениями.
Команда QUICK CLUSTER: дополнительные возможности
Процедура Кластерный анализ методом k-средних использует синтаксис команды QUICK CLUSTER. Язык синтаксиса команд также позволяет:
Использовать первые k наблюдений в качестве начальных центров кластеров, тем самым избегая прохода по данным, обычно применяемого, чтобы их оценить.
Задать начальные центры кластеров напрямую, как часть командного синтаксиса.
Задавать имена сохраняемых переменных.
Полную информацию о синтаксисе языка команд можно найти в Руководстве по синтаксису.