


95
Линейные модели
значения непрерывных предикторов заменяются средним значением обучающего разбиения.
Контролируемое объединение. Эта операция делает модель более “экономной” путем уменьшения числа полей, обрабатываемых в связи с целевым полем. Идентифицируются подобные категории, основываясь на взаимосвязи между входным
и целевым полями. Категории, которые не различаются значимо (т.е. имеющие p-значение больше 0,1), объединяются. Если все категории объединяются в одну, то исходная и полученная версии поля исключаются из модели, поскольку они не представляют ценности как предиктор.
Доверительный уровень. Это доверительный уровень, используемый при вычислении интервальных оценок коэффициентов модели, представленных на панели Коэффициенты. Задайте значение, большее 0 и меньшее 100. Значение по умолчанию равно 95.
Подбор модели
Рисунок 15-4
Параметры подбора модели
Метод подбора модели. Выберите один из методов подбора модели (подробности ниже) или Включить все предикторы, когда все имеющиеся предикторы просто вводятся в модель как члены главных эффектов. По умолчанию используется Прямой шаговый .

96
Глава 15
Прямой шаговый отбор. Этот метод начинает работу с модели без эффектов, добавляя и удаляя эффекты по одному на каждом шаге до тех пор, пока ни один эффект нельзя будет добавить, руководствуясь критериями шагового отбора.
Критерии для включения/исключения. Это статистика, используемая для определения того, следует ли эффект добавить в модель или исключить из нее. Информационный критерий (AICC) основывается на правдоподобии обучающего множества для
данной модели и скорректирован с целью штрафовать излишне сложные модели. F-статистики основывается на статистическом критерии снижения модельной ошибки. Скорректированный R-квадрат основывается на точности подгонки для обучающего множества и скорректирован с целью штрафовать излишне сложные модели. Критерий предотвращения сверхобучения (СКО) основывается на точности подгонки (среднем квадрате ошибки или СКО) для множества предотвращения сверхобучения. Множество предотвращения сверхобучения представляет собой случайную подвыборку, содержащую приблизительно 30% наблюдений из исходного набора данных, которая не используется при обучении модели.
Если выбран любой критерий, отличный от F-статистики , то на каждом шаге в модель добавляется эффект, соответствующий максимальному положительному приращению значения критерия. Все эффекты в модели, соответствующие уменьшению значения критерия, удаляются.
Если в качестве критерия выбран F-статистики , то на каждом шаге в модель добавляется эффект, дающий наименьшее p-значение, при условии, что оно меньше порогового значения, заданного в Включать эффекты с p-значениями, меньшими чем. Значение по умолчанию равно 0,05. Все эффекты в модели с p-значением, превосходящим пороговое значение, заданное в Исключать эффекты с p-значениями, большими чем, удаляются.
Значение по умолчанию равно 0.10.
Задать максимальное число эффектов в окончательной модели. По умолчанию все имеющиеся эффекты могут быть включены в модель. Как альтернатива, если шаговый алгоритм, заканчивая работу на некотором шаге, имеет заданное максимальное число эффектов в модели, то он останавливает работу, сохраняя текущий набор эффектов.
Задать максимальное число шагов. Шаговый алгоритм останавливается после определенного числа шагов. По умолчанию это утроенное число имеющихся эффектов. Как альтернатива, задайте положительное целое для максимума числа шагов.
Выбор наилучших подмножеств. Проверяются “все возможные” модели или, по крайней мере, большая совокупность возможных моделей, чем при прямом пошаговом отборе, для выбора наилучших в соответствии с критерием наилучших подмножеств. Информационный критерий (AICC) основывается на правдоподобии обучающего множества для данной модели и скорректирован с целью штрафовать излишне сложные модели. Скорректированный R-квадрат основывается на точности подгонки для обучающего множества и скорректирован с целью штрафовать излишне сложные модели. Критерий предотвращения сверхобучения (СКО) основывается на точности подгонки (среднем квадрате ошибки или СКО) для множества предотвращения сверхобучения. Множество предотвращения сверхобучения представляет собой случайную подвыборку, содержащую приблизительно 30% наблюдений из исходного набора данных, которая не используется при обучении модели.
В качестве наилучшей модели выбирается модель с наибольшим значением критерия.
97
Линейные модели
Примечание: Выбор наилучших подмножеств требует большего объема вычислений, чем прямой шаговый отбор. Когда выполняется выбор наилучших подмножеств в сочетании с бустингом, бэггингом или очень большими наборами данных, то для построения модели потребуется значительно больше времени, чем при построении стандартной модели с использованием прямого пошагового отбора.
Ансамбли
Рисунок 15-5
Параметры ансамблей
Данные параметры определяют поведение ансамбля, которое имеет место, когда на вкладке Цели запрашивается бэггинг, бустинг или очень большие наборы данных. Параметры, которые не применяются к выбранной цели, игнорируются.
Бэггинг и очень большие наборы данных. Это правило, которое при скоринге ансамбля используется, чтобы объединить предсказанные значения для базовых моделей с целью вычисления значения для ансамбля.
Принятое по умолчанию правило объединения для непрерывных целевых полей.
Предсказанные значения для ансамбля в случае непрерывных целевых полей могут быть вычислены с использованием среднего значения или медианы предсказанных значений для базовых моделей.
Обратите внимание на то, что если цель состоит в повышении точности модели, выбор правила объединения игнорируется. При бустинге всегда используется взвешенное решение большинством голосов для скоринга категориальных целевых полей и взвешенная медиана для скоринга непрерывных целевых полей.
Бустинг и бэггинг. Задайте число базовых моделей для построения, когда целью является повышение точности или стабильности; для бэггинга это число бутстреп-выборок. Оно должно быть положительным целым.
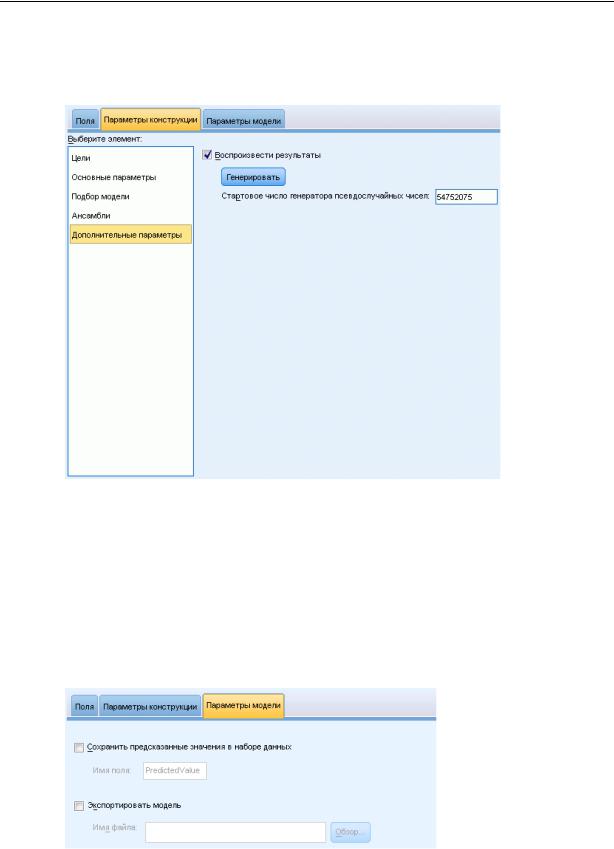
98
Глава 15
Дополнительные параметры
Рисунок 15-6
Дополнительные параметры
Воспроизвести результаты. Задание стартового числа генератора псевдослучайных чисел позволяет воспроизвести результаты. Генератор псевдослучайных чисел используется для выбора записей, попадающих в множество предотвращения сверхобучения. Задайте целое число или щелкните по Генерировать, чтобы сгенерировать псевдослучайное целое число в диапазоне между 1 и 2147483647 включительно. Значение по умолчанию равно 54752075.
Параметры модели
Рисунок 15-7
Вкладка Параметры модели