

1.2. Скорочена характеристика методів прогнозування
У практичному сенсі будемо мати на увазі, що стосовно операційно-комерційного підходу система прогнозування може бути дешевою (спрощеною) і дорогою (ускладненою). Прості і відносно дешеві методи використовують при створенні проектів нової продукції, плануванні матеріальних запасів: найчастіше це методи під назвою “рухоме середнє” або “експоненціальне згладжування”.
Методи техніко-економічних розрахунків дозволяють визначати показники одночасно із заходами які забезпечують їх змінення. Використовуються методи здебільшого у випадках коротко – і середньо строкової перспективи і найчастіше на верхніх рівнях управління і планування.
Недоліки цих методів:
1. Методи трудомісткі у реалізації і мають низку вірогідність.
2. Складно кількісно визначити вплив кожного фактору якщо вони взаємопов’язані і важко виділити потрібний без виключення дій інших
3. Неможливо використовувати у довгостроковому прогнозуванні.
Методи не дуже поширені у сфері операційного менеджменту, тому є сенс не наводити більш розгорнуту характеристику.
1.2.1. Аналіз часових рядів
В основу комплексу методів аналіза часових рядів, покладено ідею, що минулі характеристики попиту можна використовувати для прогнозування майбутнього попиту. Характеристики попиту минулих часів можуть включати декілька компонентів, наприклад, таких як тренди, сезонні або цикличні коливання.
До групи входять методи короткострокового прогнозування (до трьох місяців), середньострокового (від трьох місяців до двох років), довгострокового (більше ніж два роки). За суттю поняття аналіз часових рядів поєднує клас методів для яких характерним є виділення у сукупності даних трендів і усунення випадкових подій (шумів). Тобто випадкові зміни не повинні враховуватись. На вибір методу і його коректність впливають:
часовий обрій прогнозування;
початкові дані;
потрібна точність прогнозу;
фінанси, що виділені для розробки прогнозу;
рівень кваліфікації персоналу;
ступінь гнучкості організації (фірми);
наслідки негативних результатів.
Екстрополяційні методи у явному вигляді не враховують причинних зв’язків. Найбільш поширені із них: екстраполяції за трендом часового ряду; авторегресії; експоненційного згладжування і гармонічних терезів.
Прогнозування за трендом часового ряду. Сутність підходу полягає в тому щоб знайти аналітичний вираз функції показника, що прогнозується від часу і у екстраполяції отриманої залежності на перспективу. Окрім аналітичної функції, для отримання прогностичних оцінок застосовуються методи згладжування часових рядів на підставі ковзаючих і виважено ковзаючих середніх.
За методом авто - регресії використовують таку модель:
![]() ,
де: у(t),
y(t-1),…,y(t-l)
– рівні показника, що прогнозується у
t-му,
(t-1),…,(t-l)-му
році; а0,
а1,…,
аl
– параметри; εt
– випадковий залишок. В основу покладена
тенденція зміни, що буде визначати
рівень цих змін і в майбутньому.
,
де: у(t),
y(t-1),…,y(t-l)
– рівні показника, що прогнозується у
t-му,
(t-1),…,(t-l)-му
році; а0,
а1,…,
аl
– параметри; εt
– випадковий залишок. В основу покладена
тенденція зміни, що буде визначати
рівень цих змін і в майбутньому.
Метод екстраполяційного згладжування засновано на встановленні загальної тенденції згладжування часового ряду за допомогою ковзаючої середньої, де вагові значення підпорядковуються експоненціальному закону. Чим ближче наближений показаник до часу прогнозування тим більша його вага. (табл.1.1, п.2.3). Тенденція, що встановлена, розповсюджується на наступні періоди. Загальним для цих методів є те , що аргументом тут виступає час, який сам по собі не є причиною події. Тому така ситуація не дає можливості виявити і проаналізувати вплив окремих факторів.
Хоча екстраполяційні методи не дозволяють прогнозувати період часу, вони легко формалізуються і надають змоги отримати прогноз по одному часовому ряду, що важливо у разі відсутності інформації про фактори впливу. У практичному сенсі бажано, щоб період прогнозування був у межах 5-7 років.
Підхід експоненційного згладжування використовується, якщо значення (впливовість) даних з часом зменшується. Формальна сутність методу в тому, що кожне значення періодів спрямованих у майбутнє зменшується на 1-α, де: α – константа згладжування. Припустимо, що α = 0,05. В такому разі, коефіцієнт згладжування може бути розраховано таким чином:
Поточний період- α(1-α)º |
0,05 |
Дані на один період, що позаду –α(1-α)1 |
0,0475 |
Дані на два періоди, що позаду - α(1-α)2 |
0,0451 |
Дані на три періоди, що позаду - α(1-α)3 |
0,0429 |
Для реалізації методу достатньо таких даних: дані останнього прогнозу, існуючий (поточний) попит і кількісне значення α – константи згладжування. Останній показник визначає рівень згладжування і швидкість реакції на різницю між прогнозними і поточними подіями. Вибір α залежить від сутності об'єкту, здатності змінюватись, досвіду менеджера, швидкості реагування на ситуацію.
Зауважимо, що чим вище темп зростання випуску товару, тим вищою повинна бути швидкість реагування на параметри процесу: α= 2/n+1, де: n – кількість періодів усереднення. У разі однократного експоненційного згладжування використовується залежність: Ft = Ft-1+α(At-1 – Ft-1) ,
де: Ft – експоненційно згладжений прогноз на t період;
Ft-1 – експоненційно згладжений прогноз для попереднього періоду;
Аt-1 - фактичний попит у попередній період;
α - константа згладжування (експоненційний коефіцієнт).
Переваги методу:
1. Експоненційні моделі відносно прості і надійні .
2. Зрозумілі користувачеві.
3. Не потребують для розрахунків багато часу.
4. Вимоги щодо комп’ютерної пам’яті незначні.
5. Тестування щодо точності моделі спрощене.
Приклади кривих згладжування при різних значеннях α наведені на рис. 1.1


Рисунок 1.1. Графіки згладжування в залежності від значень константи
Трендові ефекти у разі експоненційного згаджування
Спадний, або висхідний тренд веде до “відставання” експоненційного прогнозу від фактичного положення. Коригується результат введенням тренду. В цих випадках окрім коефіцієнту згладжування – α використовується константа згладжування тренду – δ.
FJTt = Ft - Tt, де: FJTt – прогноз, що включає тренд t-го періоду; Ft – експоненційно згладжений прогноз; Тt – експоненційно згладжений тренд на період t: Tt=Tt-1+αδ(At-1 –FJTt-1). Ft = FJTt-1+α(At-1 - FJTt-1),
де: FJTt-1 - прогноз, що включає тренд попереднього періоду;
Аt-1 - фактичний попит попереднього періоду.
Приклад 1.1
Хай початковий прогноз Ft-1 = 100 одиниць виробів. Тренд Tt-1 = 10; α=20; δ=30. Розробити прогноз на наступний термін при умові, що значення фактичного попиту дорівнює 115 од., а його прогнозне значення = 100.
![]() ;
;
![]() ;
;
![]() ;
;
![]()
Якщо значення фактичного попиту буде дорівнювати 120 одиницям замість 121, то процедура повторюється і прогноз на наступний період зміниться:
![]()
![]()
![]()
![]()
У разі
необхідності швидкого реагування
результату прогнозу на події, що
відбуваються в перебігу періоду
протяжності базової лінії (рис.1.1) може
бути застосовано метод в основу якого
покладена думка, що кожний новий прогноз
отримується на підставі переміщення
попереднього прогнозу у напрямку, який
дав би кращі результати в порівнянні
із старим прогнозом. Формальна запис
методу:
![]() ;
де: t-
тимчасовий період; F(t)-
прогноз в період часу t;
F(t+1)
- відображає прогноз
в часовий період, що настає безпосередньо
за моментом t;
α-
конcтанта
згладжування; e(t)-
погрішність, тобто відмінність між
прогнозом у момент t
і фактичним результатом, що спостерігали
у цей момент t.
;
де: t-
тимчасовий період; F(t)-
прогноз в період часу t;
F(t+1)
- відображає прогноз
в часовий період, що настає безпосередньо
за моментом t;
α-
конcтанта
згладжування; e(t)-
погрішність, тобто відмінність між
прогнозом у момент t
і фактичним результатом, що спостерігали
у цей момент t.
Вибір константи згладжування.
На окрему увагу заслуговує відшукування константи згладжування, значення якої знаходиться в діапазоні 0÷1. Якщо реальний попит стабільний, то для зниження впливу коливань використовують меншу величину α. Якщо попит збільшується, або зменшується – брати більші значення. В таких випадках для відслідковування і коректування α слід застосовувати автоматизовані процедури спостереження.
Існує два засоби управління значеннями α.
1. Вимірюється величина похибки між прогнозом і фактичним значенням попиту. В залежності від ступеня похибки на практиці використовуються такі значення α: якщо похибка велика, то приймається α = 0,8, якщо не значна, то α = 0,2.
2. Використовують трекінгову похибку, тобто змінюють значення α на трекінг коефіцієнта α. Трекінг коефіцієнта α є відношення поточної експоненційно згладженої похибки і експоненційно згладженої абсолютної похибки.
Основні джерела похибок.
1. Перенесення трендів, що використовувались у попередньому на поточні прогнози. З практики відомо, що поточні похибки завжди більші ніж ті, що спрогнозовані на підставі моделей.
2. Похибки можна поділити на систематичні (похибки вимірювання) і випадкові. Систематичні виникають у наслідок дії постійних факторів, що типові для методу вимірювання. Випадкові - це ті які не пояснюються тією моделлю прогнозу, яка використовувалась.
Виміри похибок прогнозування
Для прикладного прогнозування важливе значення мають свідчення щодо можливих похибок методу. У цих процедурах виміру похибок
використовуються такі поняття:
- стандартна похибка;
- середнє квадратів відхилень;
- середнє абсолютних відхилень;
- трекінг для врахування позитивних і негативних систематичних відхилень.
Якщо два перших не потребують додаткових тлумачень (достатньо відомі), то на два останніх слід звернути особливу увагу:
Середнє
абсолютне відхилення
– МАD
(Mean
Absolute
Deviation)
– це середнє значення похибки у прогнозах
яке вимірює розкид фактичного процесу,
що спостерігається, від деякого
очікуваного процесу:
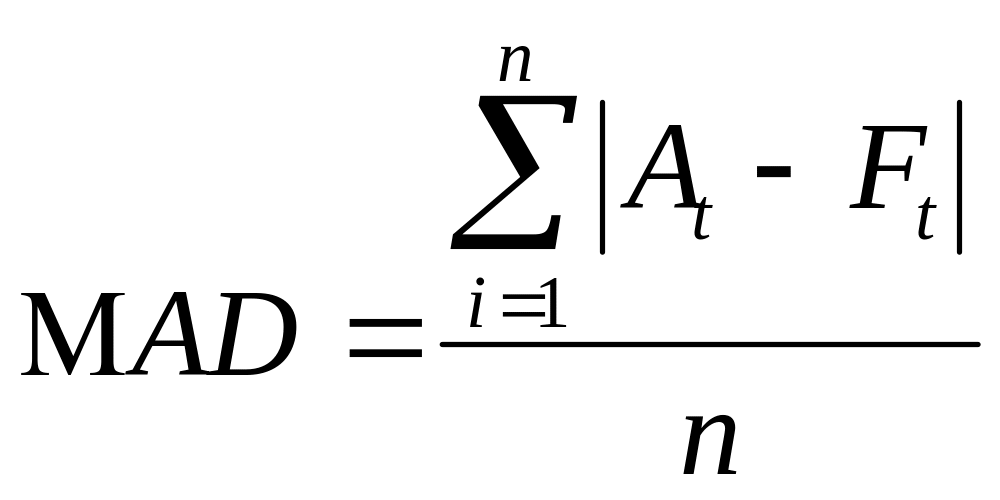 ,
,
де: t - номер чергового періоду;
Аt - поточний попит у даному періоді;
Ft – попит, що прогнозується у даному періоді;
n - загальна кількість періодів;
| | - символ модуля ( абсолютна величина).
Зауважимо,
що при нормальному розподілі похибок,
середнє абсолютне відхилення пов’язане
із стандартним відхиленням, тобто:
![]() ;
;
![]()
Значення MAD
вказує
на діапазон
похибок. При управлінні, наприклад,
запасами MAD
зручно використовувати для визначення
резервного запасу:
![]() ,
,
де:
![]() -
прогноз МАD для
t-го
періоду;
-
прогноз МАD для
t-го
періоду;
α - константа згладжування (найчастіше в межах від 0,05 до 0,2);
А![]() -
фактичний попит (t-1)-го
періоду;
-
фактичний попит (t-1)-го
періоду;
F - попит, що прогнозується на (t-1) період.
Трекінг
-
TS
у прикладному призначенні
показує на скільки точно прогноз
відповідає збільшенню або зменшенню
фактичного попиту. Формально трекінг
можна визначити як відношення
алгебраїчної
суми відхилень прогнозу і MAD:
![]() ;
де:
RSFE
(Running
Sum of Forecast Errors)
-
алгебраічна
сума похибок прогнозу, що враховує
позначку похибки: (-) – компенсувати,
(+) – навпаки;
MAD
–
середнє усіх абсолютних відхилень (не
залежно від того - позитивне чи негативне
це відхилення).
;
де:
RSFE
(Running
Sum of Forecast Errors)
-
алгебраічна
сума похибок прогнозу, що враховує
позначку похибки: (-) – компенсувати,
(+) – навпаки;
MAD
–
середнє усіх абсолютних відхилень (не
залежно від того - позитивне чи негативне
це відхилення).
Розрахунки вказаних параметрів краще використовувати якщо вони надаються у табличній формі (табл. 1.3).
Приклад 1.2
Розрахувати середнє абсолютне відхилення (MAD), суми похибок прогнозу (RSFE) і трекінга (TS) для періоду у шість місяців, де прогнозуємий місячний попит було встановлено однаковим і який дорівнював 1000 одиницям [17]..
Таблиця 1.3. Розозраховані значення вимірів похибок прогнозу
Місяць року |
Прогноз попиту |
Фактич. попит |
Відхи- лення |
RSFE |
Абсолют. відхилен- ня |
Сума абсолют. відхилень |
MAD |
TS=RSFE/MAD
|
1 |
1000 |
950 |
-50 |
-50 |
50 |
50 |
50 |
-1 |
2 |
1000 |
1070 |
+70 |
+20 |
70 |
120 |
60 |
0,33 |
3 |
1000 |
1100 |
+100 |
+120 |
100 |
220 |
73,3 |
1,64 |
4 |
1000 |
960 |
-40 |
-80 |
40 |
260 |
65 |
1,2 |
5 |
1000 |
1090 |
+90 |
+170 |
90 |
350 |
70 |
2,4 |
6 |
1000 |
1050 |
+50 |
+220 |
50 |
400 |
66,7 |
3,3 |
Примітка: Для 6-го місяця МАD становить – 400/6 = 66,7. TS = RSFE/MAD = 220/66,7 = 3,3 MAD
Аналіз даних таблиці. З таблиці середнє абсолютне відхилення 66,7 одиниць, а трекинг 3,3 МАD. Трекінг змінюється від 1 до 3,3 і пов’язано з тим, що поточний попит більший за прогнозований у чотирьох із шости періодів. Якщо фактичний попит не був би менший за прогнозований в 1-му періоді і не скомпенсував би постійну позитивну похибку - RSFE, то трекінг був би більшим і можна було б прийти висновку, що прийнятий попит у 1000 од. не є вдалим прогнозом
Для збільшення наочності за даними розрахунків може бути розбудовано графік якщо на осі абсцис відкласти номери місяців (рис.1.2)
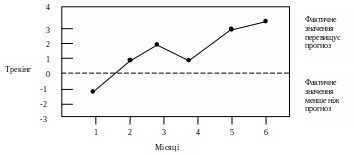

Рисунок 1.2. Графік трекінга розбудований за даними таблиці 1.3
Для припустимих відхилень трекінгу встановлюють контрольні межі (табл.1.4). Ці межі залежать від прогнозованого попиту (більш доходні товари або більший об’єм продажу слід контролювати найчастіше) і від часу, що є у розпорядженні персоналу (у разі звужених припустимих меж більша кількість прогнозів буде знаходитись поза межами, тому знадобиться більше часу для дослідження).
Таблиця 1.4. Контрольні межі відхилень
Контрольн і м е ж і |
||
Відхилення MAD |
Відносне число стандарт- них відхилень |
Відсоток точок, що розміщуються в контрольних межах |
+1 |
0,798 |
57,048 |
+2 |
1,596 |
88,946 |
+3 |
2,394 |
98,334 |
±4 |
3,192 |
99,856 |
Враховуючи зв’язок трекингу з MAD можна обрати контрольні межі за необхідним відсотком точок, що входять до зони припустимих відхилень MAD. Зауважимо, що у вірно сформованій моделі прогнозування, сума похибок прогнозу повинна дорівнювати 0. MAD часто використовують для прогнозування саме похибок. Тому бажано щоб MAD было більш чутливим до останніх даних. Щоб цьому сприяти, розраховують експоненціально згладжене MAD як прогноз для діапазону похибок наступного періоду. Ця процедура схожа на процедуру однократного експоненціального згладжування, що розглянуто нами вище, де значення MAD показує діапазон похибки. Якщо справа, наприклад, стосується управління запасами, то таку процедуру з MAD можна використати для визначення рівня резервних запасів (формалізми див. на стор.21)
При прогнозуванні процесів у якості інструментарію використовується Excel, спеціальні пакети комп'ютерних програм і графічне представлення результатів на кожному етапі аналізу.
Просте ковзаюче середнє
Для кращого усвідомлення і аналізу наведеио декілька формальних модифікацій і підходів щодо використання методу.
Якщо попит стабільний, не сезонний і має лише випадкову флуктуацію, то формула попиту виглядатиме таким чином:
1.
Просте рухоме середнє:
![]()
де:
![]() - прогноз на майбутній період;
- прогноз на майбутній період;
n – інтервал (кількість періодів) усереднення;
![]() - фактичне
значення у першому попередньому
періоді;
- фактичне
значення у першому попередньому
періоді;
![]() - фактичні
значення попередніх 2, 3 і n
періодів.
- фактичні
значення попередніх 2, 3 і n
періодів.
2. Виважене середнє рухоме: Сутність полягає в тому, що елементам надається будь-яка вага при умові, що загальна вага не перевищуватиме одиниці. Зауважимо, що у простому ковзаючому середньому кожному елементу привласнюється однакова за значенням вага:
![]()
де:: W1 - значення ваги, що привласнено попередньому періоду (t-1);
W![]() 2-значення
ваги, що привласнене періоду (t-2)
Wn
- значення ваги, що надане періоду (t-n);
2-значення
ваги, що привласнене періоду (t-2)
Wn
- значення ваги, що надане періоду (t-n);
n – загальна кількість періодів. Загальне значення ваги - .
Приклад 1.3
Якщо маємо таку помісячну динаміку попиту, то прогноз на п’ятий місяць може скластися таким чином:
Місяц 1 |
Місяць 2 |
Місяць 3 |
Місяць 4 |
Місяць 5 |
100 |
89 |
110 |
97 |
? |
F5 =(0,4·97)+(0,3·110)+(0,2·89)+(0,1·100) = 98,4. Зазначимо, що cуттю методу є можливість впливати на прогноз, змінюючи результати минулих періодів. При цьому найближче попереднє є важливим індикатором майбутнього – тому цей період має найвищій бал.
За недоліки методу можна вважати:
1. Дані за минулі періоди (роки) і поточні за значеннями впливу прийняті як однакові, що не відповідає дійсності.
2. Показники, що вийшли за межі середніх значень не враховуються.
Прогноз попиту на базі рухомого середнього
Підхід
розглядає значення попиту як арифметичне
усереднення його попередніх значень
[15]:
![]() ;
або
;
або
![]() ,
де:
,
де:
![]() -
значення попиту в період t.
-
значення попиту в період t.
Приклад 1.4
Хай маємо ряд значень попиту:
Місяць |
І |
ІІ |
ІІІ |
IV |
V |
VI |
Прогноз |
VII |
VIII |
Попит, од. |
5 |
6 |
4 |
7 |
4 |
5 |
|
5 |
5,25 |
Для n = 4 розрахуємо рухоме середнє, вважаючи, що t = 6; t = 5; t = 4.
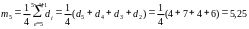
![]() ,
або
,
або
![]()
Таким чином,
вважаючи, що прогноз на 7-й місяць
дорівнюватиме 5(d7=5),
визначимо прогнозне
значення на
8-й:
![]()
Якщо обирати різноманітні значення питомої ваги, то рухоме середнє можна визначити як: m6 = 0,8d6 + 0,1d5 + 0,05d4 + 0,05d3 = 0,8×5 + 0,1×4 + 0,05×4 + 0,05×4 = 4 + 0,4 + 0,35 + 0,2 = 4,95.
Прогнозування попиту з використанням коефіцієнту еластичності фактору
Іноді стає необхідним визначити, на скільки відсотків зміниться попит якщо значення факторів, що впливають зміниться на 1%. З цією метою вводиться коефіцієнт еластичності фактору. При цьому метод передбачає, що коефіцієнт еластичності фактору у продовж періоду, на який складається прогноз не змінюється .
Аналітичний
вираз коефіцієнту еластичності фактору
буде:
![]() ,
де:
,
де:
![]() -
похідна функції моделі попиту = f(x).
Так, якщо ця функція лінійна - у=
ах + b,
то
=
а
і
-
похідна функції моделі попиту = f(x).
Так, якщо ця функція лінійна - у=
ах + b,
то
=
а
і
![]() .
При означенні, що у
і ∆у
– відповідно попит і зміна попиту; х
і ∆х
– відповідно значення фактору і зміна
фактору, будемо мати значення зміни
попиту:
.
При означенні, що у
і ∆у
– відповідно попит і зміна попиту; х
і ∆х
– відповідно значення фактору і зміна
фактору, будемо мати значення зміни
попиту:
![]() ;
;![]() .
В такому разі прогнозне значення попиту
-
.
В такому разі прогнозне значення попиту
-
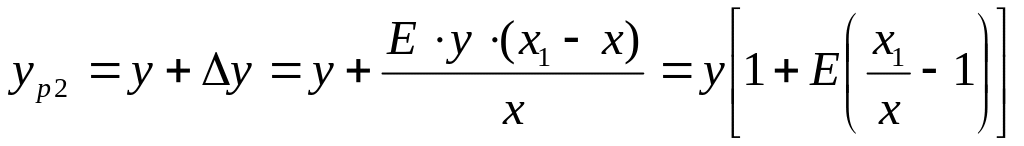 , де: х1
- нове
значення
фактору
впливу.
, де: х1
- нове
значення
фактору
впливу.
В залежнлсті від значень коефіцієнта еластичності попиту і пов’язаних з ним доходів виділяють 4 групи товарів:
1.Малоцінні
-
![]()
2.Товари
із малою еластичністю попиту -
![]() ;
;
3.Товари
із середньою еластичністю попиту -
![]() ;
;
4.Товари
із високою еластичністю попиту -
![]() .
.
Примітка
1:
Для основних продуктів (харчування)
![]() ;
для
одягу, взуття, тканини
;
для
одягу, взуття, тканини
![]() .
У міру зростання доходу - Z,
попит
зміщується від першої і другої групи
до третьої і четвертої.
.
У міру зростання доходу - Z,
попит
зміщується від першої і другої групи
до третьої і четвертої.
Примітка 2: Торнквіст Л., викорисовуючи криві Енгеля (рис. 1.3), запропонував функції попиту за класифікацією вжитку для трьох груп товарів:
1). Для
товарів першої необхідності:
![]() ,
Z
> 0;
,
Z
> 0;
2). Для
товарів другої групи необхідності (не
обов’язкового вжитку):
![]() ,
де: Z
> b2
- дохід досягне b2
;
,
де: Z
> b2
- дохід досягне b2
;
3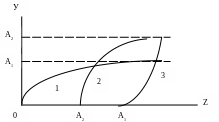 ).
Для предметів розкоші:
).
Для предметів розкоші:
![]() ,
де: Z
> b3
і функція не має межі.
,
де: Z
> b3
і функція не має межі.
Рисунок. 1.3. Криві залежності попиту від доходу.
Насичення попиту. Поняття віддзеркалює характер скорочення або припинення попиту. Відрізняють насиченість платоспроможного попиту і насиченість потреби (попит не зростає навіть при збільшенні доходу і зниженні цін).
Пиклади реалізації аналітичних методів прогнозування
Приклад 1.5
Треба зробити прогноз ефективності операційної діяльності організації на ринку збуту. Для проведення прогнозних розрахунків необхідно мати дані щодо конкретних значень параметрів. На першому етапі організується інформація на основі застосування статистичних методів, або експертного оцінювання. Вважаємо, що середній коефіцієнт зростання доходів складає 1,15 (15% зростання за рік). Коефіцієнт зростання кількості сімей з підвищеним прожитковим рівнем змінюється на 0,8% (1,008). В такому разі, якщо t- інтервал часу, Аt і Аt-1 – річний обсяг попиту, - коефіцієнт який враховує вплив факторів, будемо мати Аt = Аt-1×,; = 1,15 × 1,008 1,16.
Припустимо, що попит на товар у базовий період склав А0 = 5000 од. при базовій ціні 3000 грн. При фіксованій ціні попит визначиться таким чином: Аt = 1,16. Аt-1. Тобто А1 = 5800; А2 = 6287; А3 = 7804.
Що станеться з функцією попиту в умовах зміни цін? Спираючись на статистичні дані про вплив зростання цін на рівень попиту, приймемо коефіцієнт еластичності b = 0,3. Це означатиме, що з підвищенням ціни на 10% очікується зниження річного обсягу попиту на 3%. Але це слушно, доки ціна не перевищить деякий поріг. Скористаємось формулою Аt(Р) =
Аt-1
.
rt-b
,
де: А![]() (Р)×
Аt-1
–
обсяг попиту відповідно в інтервалі
часу t
і
в попередньому інтервалі ;
(Р)×
Аt-1
–
обсяг попиту відповідно в інтервалі
часу t
і
в попередньому інтервалі ;
rt – індекс цін, що дорівнює відношенню ціни Рt до базової Рt-1;
b – коефіцієнт еластичності (прийняли, що b = 0,3).
а) В умовах незмінних цін.
В місті за даними статистичного обліку населення, середній коефіцієнт зростання доходів складає 1,15 (15% приросту за рік). Коефіцієнт зростання числа родин з підвищеним рівнем доходів змінюється повільніше – 1,008 (0,8% приросту в рік). В такому разі коефіцієнт, що враховує вплив чинника: a = 1.15×1.008 =1.16.
Обстеження ринку показало, що попит у базовий період становить в середньому – S0 = 5000 грн при базовій ціні 3000 грн.
На який
об’єм
попита можна сподіватись у наступні
три роки при фіксованій ціні? Використаємо
залежність - St
=1.16×St-1.
Отримаємо: S1
=1,16×5000 = 5800;
![]() ;
;
![]() .
.
b) В умовах змінення ціни
Коефіцієнт
еластичності
0,3 (з підвищенням цін на 10% очікується
зниження річного попиту на 3%). Хай частка
фірми на ринку складає 20%, але є тенденція
щорічного зменшення цієї частки на 2%.
Тоді частка ринку
![]() ,
де:
dt
- частка на інтервалі t;
,
де:
dt
- частка на інтервалі t;
![]() - частка
в базовий період
=
0,2;
- частка
в базовий період
=
0,2;
![]() -
коефіцієнт змінення.
-
коефіцієнт змінення.
![]() .
В
такому разі ринковий попит:
.
В
такому разі ринковий попит:
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
Тому
.
Тому
![]() ;
;
![]()
![]() , де:
І
– індекс цін:
, де:
І
– індекс цін:
![]() ;
;
![]() -
об'єм попиту в інтервалі t;
-
об'єм попиту в інтервалі t;
![]() -
об'єм попиту в попередньому інтервалі.
-
об'єм попиту в попередньому інтервалі.
Зрозуміло, що організація може змінювати вхідні параметри в залежності від ситуації, що складається, і нових даних які надходять. Крім того, якщо застосувати відповідний інструментарій, можна розраховувати різноманітні варіанти і обирати з них отой, який найбільш адекватно віддзеркалює ринкову реальність.
Приклад 1.5а
Ускладнимо задачу і врахуємо залежність попиту на товари, або послуги від декілька факторів. Для цього використаємо функцію попиту від ціни, рівня прибутку населення, сезонності, конкуренції. Менеджеру потрібно розрахувати величину попиту на товар j у натуральному і вартісному виразі у перший, після базового, період часу (t = 1) при таких вхідних параметрах:
- величина попиту
на товар j у базовий
період.
![]() од.
од.
- ціна одиниці
товару j у базовий
період Р![]() грн.;
грн.;
- очікувана ціна
товару j у наступному
місяці Р![]() грн.
грн.
- коефіцієнт еластичності ціни - = 0,35;
- коефіцієнт еластичності добутку - b = 0,3;
- середній добуток родини у наступному періоді очікується: Д(1) = 1600 грн.;
- коефіцієнт інфляції: К = 1,05;
- частка ринку у наступний період буде зростати приблизно на 20% : dj = 1,2;
- ринок звужується завдяки пересиченості товаром: Кrj = 0,95.
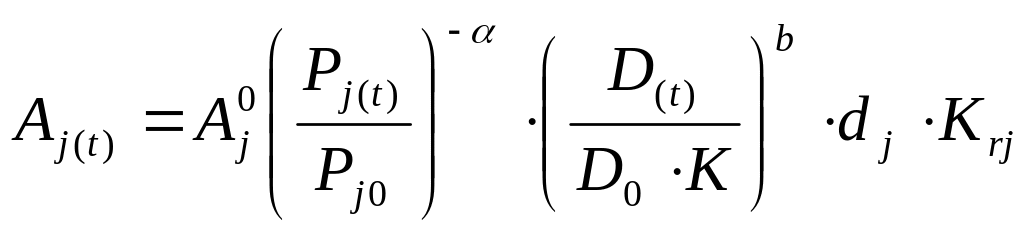 .
У
числовому виразі: .
.
У
числовому виразі: .
![]() од.
од.
Здобуток буде
дорівнювати: V![]() =
1001104=110,4
тис.грн. Таким чином, величина попиту
в прогнозуємий термін оцінюється у
1104
од. товару j,
а здобуток , що очікується -
у 110,4
тис.грн.
=
1001104=110,4
тис.грн. Таким чином, величина попиту
в прогнозуємий термін оцінюється у
1104
од. товару j,
а здобуток , що очікується -
у 110,4
тис.грн.
Приклад 1.5б
Припустимо,
що при ціні 50 грн. (х
= 50) попит був 300 од. виробів (у
= 300), а при ціні 60 грн. (x1=
60) попит склав 280 виробів. В такому разі
∆у
= 280 –300 =
-
20;
![]() х
= 60 - 50 = 10.
х
= 60 - 50 = 10.
![]() .
Тобто , якщо відоме значення коефіцієнту
еластичності за ціною, можна визначити,
яким буде попит у разі зниження ціни,
наприклад, до 40 грн. за одиницю:
.
Тобто , якщо відоме значення коефіцієнту
еластичності за ціною, можна визначити,
яким буде попит у разі зниження ціни,
наприклад, до 40 грн. за одиницю:
![]() од.
од.
Зауважимо, що у практичному застосуванні методу (курсове проектування, наприклад) у якості факторів впливу можна розглядати будь-які показники (витрати на рекламу, обсяг продажу імпортованих товарів та ін.).
Ймовірнісний підхід
У ситуаціях невизначеності і недостатності аналітичних даних заслуговує на увагу прогнозування попиту на підставі евристичних процедур. Одна із таких процедур отримала назву методу усереднення.
Припустимо, що
застосування різних методів прогнозу
надає множину значень в напрямку
збільшення – А1,
А2,
..., Аn.
Хай величина попиту А0r
є величиною випадковою, що розподіляється
за
- розподілом і математичне очікування
якого описується як:
![]() ,
і дисперсія
,
і дисперсія
![]() , де:
, де:
![]() - мінімальна і максимальна величина
попиту, що прогнозується ;
- мінімальна і максимальна величина
попиту, що прогнозується ;
![]() - найбільш ймовірна величина попиту.
- найбільш ймовірна величина попиту.
У
нашому випадку вважаємо:
![]() ;
;
![]() .
Якщо мати на увазі, що величина попиту
є випадковою, що розподілена за нормальним
законом, то
.
Якщо мати на увазі, що величина попиту
є випадковою, що розподілена за нормальним
законом, то
![]() ;
;
![]() ;
;
![]() .
В такому разі ймовірність того, що
величина попиту А
буде меншою за очікувану А0r
визначатиметься як:
.
В такому разі ймовірність того, що
величина попиту А
буде меншою за очікувану А0r
визначатиметься як:
![]() ,
де:
Ф(и) – функція
Лапласа:
,
де:
Ф(и) – функція
Лапласа:![]() ;
;
![]() .
З таблиці
Лапласа (додаток.ІІ)
можна визначити значення
.
З таблиці
Лапласа (додаток.ІІ)
можна визначити значення
![]() якщо задавати потрібний рівень
ймовірності.
якщо задавати потрібний рівень
ймовірності.
Приклад 1.6
Прогнози
попиту на товари дорівнюють 97, 98, 100,
101, 106 одиниць. В цьому випадку середнє
значення величини попиту
![]() = 101, а дисперсія
= 3,162. Значення попиту підпорядковані
нормальному розподілу. Менеджер бажає
визначити значення -
= 101, а дисперсія
= 3,162. Значення попиту підпорядковані
нормальному розподілу. Менеджер бажає
визначити значення -
![]() ,
яке очікується і при якому ймовірність
того, що фактичне значення А
не перевищить
,
яке очікується і при якому ймовірність
того, що фактичне значення А
не перевищить
![]() дорівнюватиме 0,9, тобто - P
(А< А0y
) = 0,9. Звідси
маємо Ф(u)
+ 0,5 = 0,9, або Ф(u)
= 0,4. Із зворотної таблиці нормального
інтеграла знайдемо u
= 1,282. В
такому разі А
дорівнюватиме 0,9, тобто - P
(А< А0y
) = 0,9. Звідси
маємо Ф(u)
+ 0,5 = 0,9, або Ф(u)
= 0,4. Із зворотної таблиці нормального
інтеграла знайдемо u
= 1,282. В
такому разі А![]() = u
+
= (1,282
×3,162)+101=105,05.
= u
+
= (1,282
×3,162)+101=105,05.