

207
ным анализом однофакторного комплекса:
Содержание ячеек: |
|
B2 – значение числа m; B3 – значение числа n; B5 – F5 – индекс j; |
A6 – A9 – |
индекс i; B6 – F9 – значения результативного признака xij; G6 – G9 – средние арифметические выборок xi*; G10 – общая средняя всех совокупностей x ; H6 – H9 – значения квадратов xi* x 2 ; B11 – F14 – значения квадратов xij xi* 2 ; G11 – G14 – суммы
квадратов 5 xij xi* 2 ; B16 – B19 – суммы Q1, Q2, Q; D16 – D19 – оценки дисперсий;
j 1
F16 – F19 – степени свободы; B19 – значение уровня значимости ; B20 – расчетное значение показателя F; D20 – теоретическое (табличное) значение показателя F ; B21 – результат проверки гипотезы по F – критерию.
6.7.3 Двухфакторный комплекс
Если исследуется действие двух факторов, например, оценить показатели качества материала, находящегося на хранении в различных условиях (фактор А) после транспортирования различными видами транспорта (фактор В). Для простоты рассмотрим случай, когда для каждого хранилища и каждого вида транспорта имеется одно наблюдение результативного признака. Тогда матрица наблюдений может быть записана в виде таблицы 6.25.
Таблица 6.25 - Матрица наблюдений двухфакторного комплекса
i\ j |
В1 |
В2 |
… |
Вj |
… |
Вv |
xi* |
А1 |
x11 |
x12 |
… |
x1j |
… |
x1v |
x1* |
А2 |
x21 |
x22 |
… |
x2j |
… |
x2v |
x2* |
… |
… |
… |
… |
… |
… |
… |
… |
Аi |
xi1 |
xi2 |
… |
xij |
… |
xiv |
xi* |
… |
… |
… |
… |
… |
… |
… |
… |
Аr |
xr1 |
xr2 |
… |
xrj |
… |
xrv |
xr* |
x* j |
x*1 |
x*2 |
… |
x* j |
… |
x*v |
x |
Если имеется r хранилищ, то в матрице наблюдений им соответствует r строк, которые называются уровнями фактора А. Если имеется v видов транспорта, то им соответствует v столбцов, которые называются уровнями фактора В.
Пересечение i-го и j-го уровней образует ij-ю ячейку, в которую записываются наблюдения, полученные при одновременном исследовании факторов А и В на i-м и j-м уровнях соответственно.
По каждому строке и столбцу вычисляются средние значения, а также общее среднее:

208
|
|
1 |
v |
|
1 |
r |
|
1 |
r |
|
1 |
m |
|
xi* |
|
xij ; х j |
|
xij ; |
х |
xij |
|
xij . (6.142) |
|||||
v |
r |
r |
m |
||||||||||
|
|
j 1 |
|
j 1 |
|
i 1 j 1 |
|
i 1 |
|||||
|
|
|
|
|
|
|
|
|
Основное тождество дисперсионного анализа в данном случае имеет вид30
r v |
|
r v |
xi* x* j x xi* x x* j x 2 |
|
Q xij x 2 |
xij |
|||
i 1 j 1 |
|
i 1 j 1 |
|
(6.143) |
r |
|
v |
r v |
|
|
xij xi* x* j x 2 Q1 Q2 Q3 |
|||
v xi* x 2 |
r xi* x 2 |
|
||
i 1 |
|
j 1 |
i 1 j 1` |
|
|
|
|
||
Q1 |
|
Q |
|
Q |
|
|
2 |
|
3 |
Слагаемое Q1 представляет собой сумму квадратов разностей между средними по строкам и общим средним и характеризует изменение результативного признака по фактору А. Слагаемое Q2 представляет собой сумму квадратов разностей между средними по столбцам и общим средним и характеризует изменение результативного признака по фактору В. Слагаемое Q3 называется остаточной суммой квадратов и характеризует влияние неучтенных факторов. Сумма Q называется общей или полной суммой квадратов отклонений отдельных наблюдений от общей средней.
Оценка дисперсий определяются по формулам:оценка полной (общей) дисперсии
|
|
|
|
|
|
|
|
r |
v |
|
|
|
|
|
|
|
|
|
s 2 |
1 |
|
|
|
xij x 2 |
|
|
Q |
; |
|
(6.144) |
|||||
|
|
rv 1 |
|
|
|
|
|||||||||||
|
|
|
|
i 1 |
j 1 |
|
rv 1 |
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
оценка дисперсии по фактору А |
|
|
|
|
|
|
|||||||||||
|
|
|
1 |
|
|
|
r |
|
Q1 |
|
|
|
|
|
|
||
|
s12 |
|
|
|
v xi* x 2 |
|
; |
|
|
|
(6.145) |
||||||
|
|
|
|
|
r |
1 |
|
|
|||||||||
|
|
r 1 |
i 1 |
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
оценка дисперсии по фактору В |
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
v |
|
Q2 |
|
|
|
|
|
|
|
|
s22 |
1 |
|
|
r |
x* j x 2 |
|
; |
|
|
|
(6.146) |
|||||
|
|
|
|
|
v |
1 |
|
|
|||||||||
|
|
|
v 1 |
j 1 |
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
оценка остаточной дисперсии |
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
r |
|
v |
|
|
|
|
|
|
|
Q3 |
|
|
|
s32 |
1 |
|
xij |
xi* x* j x 2 |
|
|
. (6.147) |
||||||||||
r 1 n 1 |
|
r 1 v 1 |
|||||||||||||||
|
|
i 1 |
j 1 |
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
В двухфакторном анализе для выяснения значимости влияния факторов А и В на результативный признак сравни-
30 При преобразовании тождества (6.143) к выражению в скобках прибавили и отняли xi* , x* j и x .

209
вают дисперсии по факторам с остаточной дисперсией, т.е.
оценивают отношения s2 |
s2 |
и s2 |
s2 . |
|
|
||||||
|
|
|
|
1 |
3 |
2 |
3 |
|
|
|
|
Расчетный показатель по факторам А и В определяется |
|||||||||||
по формулам: |
|
|
|
|
|
|
r 1 v 1 |
|
|
||
FA |
|
s 2 |
|
|
Q |
; |
(6.148) |
||||
|
1 |
|
|
1 |
|
|
|
||||
|
s 2 |
|
|
Q r 1 |
|||||||
|
|
|
|
|
|
|
|||||
|
3 |
|
|
|
|
3 |
|
|
|
|
|
FB |
s 2 |
|
Q |
r 1 v 1 |
|
|
|||||
2 |
|
2 |
|
|
|
. |
(6.149) |
||||
s 2 |
|
|
Q v 1 |
||||||||
|
|
|
|
|
|
||||||
|
3 |
|
|
|
|
3 |
|
|
|
|
|
Полученные значения FA и FA сравнивают с теоретическими (табличными) значениями F при заданном уровне значимости .
Возможные исходы сравнения:
при FA < F и FB < F - влияние факторов А и В на результативный признак незначительно;
при FA > F и FB > F - влияние факторов А и В на результативный признак значительно;
при FA < F и FB > F - влияние факторов А на результативный признак незначительно, фактора В на результативный признак значительно;
при FA > F и FB < F - влияние факторов А на результативный признак значительно, факторов В на результативный признак незначительно.
Двухфакторный дисперсионный анализ удобно представлять в виде таблицы (таблица 6.26).
Таблица 6.26 - Таблица двухфакторного дисперсионного анализа
Компоненты |
|
|
|
|
|
Число |
Оценка дис- |
|||||||
Сумма квадратов |
|
степеней |
персии (сред- |
|||||||||||
дисперсии |
|
|||||||||||||
|
|
|
|
|
свободы k |
ний квадрат) |
||||||||
|
|
|
|
|
|
|||||||||
Между |
|
|
r |
|
|
|
|
|
|
Q1 |
|
|||
средними по |
Q1 |
v xi* |
x 2 |
|
r -1 |
s12 |
|
|
||||||
|
|
r 1 |
||||||||||||
строкам |
|
|
i 1 |
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|||
Между |
|
|
v |
|
|
|
|
|
|
Q2 |
|
|||
средними по |
Q2 |
r x* j |
x 2 |
|
v – 1 |
s22 |
|
|
||||||
|
|
v 1 |
||||||||||||
столбцам |
|
|
j 1 |
|
|
|
|
|
|
|||||
|
r |
v |
|
|
|
|
|
|
|
|
|
|
|
|
Остаточная |
Q3 xij xi* x* j |
x 2 |
(r-1)(v-1) |
s32 |
|
|
Q3 |
|
||||||
r 1 v 1 |
||||||||||||||
|
i 1 |
j 1 |
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
r |
v |
|
|
|
|
|
|
|
|
|
|
|
Полная |
Q xij |
x 2 |
|
rv – 1 |
s 2 |
|
|
Q |
|
|||||
(общая) |
|
rv 1 |
||||||||||||
|
i 1 |
j 1 |
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||
Дальнейшим развитием двухфакторного дисперсионного анализа является анализ с равным и неравным количествами наблюдений в каждой ячейке, а также - многофакторный
210
дисперсионный анализ. Естественно в этих моделях дисперсионного анализа существенно усложняются вычисления, но их сущность остается прежней.
211
6.8 Особенности применения корреляционнорегрессионого анализа
Знание статистической зависимости между случайными величинами, характеризующими явление (процесс, событие), имеет большое практическое значение в эксплуатации вооружения КВ: с ее помощью можно прогнозировать значение зависимой случайной величины в предположении, что независимая величина примет определенное значение.
Известно, что дисперсионный анализ позволяет установить влияние тех или иных факторов на рассматриваемый результативный признак, но он не дает возможности определить ни степени этого влияния (тесноту связи), ни формы этого влияния. При решении этих вопросов на помощь исследователю приходит корреляционно-регрессионный анализ, позволяющий измерить тесноту связи, ее направление и форму.
Если в дисперсионном анализе факторные признаки описываются качественно, а результативный признак – количественно, то в корреляционно-регрессионном анализе и факторные и результативный признаки описываются только количественно, т.е. они должны быть измерены.
6.8.1 Задачи и предпосылки корреляционнорегрессионного анализа
В процессе статистического исследования объективно существующих связей между явлениями вскрываются при- чинно-следственные отношения между ними. Явление (процесс, событие) называется причиной другого явления (процесса, события), если выполняются два условия: 1) первое явление предшествует второму по времени; 2) первое явление является необходимым условием, предпосылкой или основой возникновения, изменения или развития второго, иными словами, первое порождает второе. Второе явление является следствием первого. Следовательно, причинно-следственные отношения – это такая связь явлений (процессов, событий), когда изменение одного из них – причины – ведет к изменению другого - следствия.
Особое значение при исследовании причинноследственных связей имеет выявление временной последовательности: причина всегда предшествует следствию, однако
212
не всякое предшествующее событие является причиной, а последующее – следствием.
Между группами причин и следствий возможны многозначные связи, когда за одной причиной будет следовать не одно, а несколько следствий, или одно следствие будет иметь несколько причин. Чтобы установить однозначную причинную связь между явлениями или предсказать возможные следствия конкретной причины, необходима абстракция от всех прочих явлений в исследуемой временной или пространственной области.
Из всего многообразия связей между признаками выделяют функциональную и стохастическую зависимости (связи).
В технике и естествознании, как правило, речь идет о
функциональной зависимости между переменными (величи-
нами) x и y, когда каждому возможному значению x поставлено в однозначное соответствие определенное значение y. Это могут быть, например: в физике - зависимость между давлением р и температурой t газа (закон Шарля); в астрономии – зависимость силы притяжения F от масс взаимодействующих тел m1 и m2, а также - расстояния между телами R (закон тяготения); в гидродинамике– зависимость подъемной силы P от скорости потока v и угла атаки и др.
В реальном мире все явления природы происходят в условиях действия многочисленных факторов, влияние каждого из которых ничтожно, а число их велико. В этих случаях связь теряет свою строгую функциональность и изучаемая система (физическая, техническая, экономическая, социальная и т.п.) переходит не в определенное состояние, а в - одно из возможных для нее состояний. В этом случае речь идет о так называемой стохастической связи, сущность которой состоит в том, что одна случайная величина реагирует на изменение другой изменением своего закона распределения. В общем случае между двумя случайными величинами имеется стохастическая зависимость тогда, когда существуют некоторые случайные факторы, которые влияют на обе случайные величины, и некоторые факторы, действующие только на первую или только на вторую случайную величину. Следовательно,
если X f Z1 ,..., Zm , X1 ,..., X k и Y g Z1 ,..., Zm ,Y1 ,...,Yj , где
Z1,…, Zm – общие случайные факторы, то случайные величины X и Y стохастически зависимы.

213
В практических исследованиях часто рассматривается частный случай стохастической зависимости, когда условное математическое ожидание одной случайной величины является функцией значения, принимаемого другой случайной вели-
чиной, т.е. M Y | x f x . В этом случае зависимость меж-
ду одной случайной величиной и условным средним значением другой случайной величины называется статистической
или корреляционной зависимостью.
Корреляция31 – это статистическая зависимость между случайными величинами, не имеющими строгого функционального характера, при которой изменение одной из случайных величин приводит к изменению математического ожидания другой.
В отличие от функциональной зависимости корреляция возникает тогда, когда зависимость одного из признаков от другого осложняется наличием случайных факторов.
Чтобы изучить статистическую зависимость, необходимо знать условное математическое ожидание случайной переменной. Для его оценки необходимо знать аналитический вид двумерного распределения (X, Y). Однако, суждение об аналитическом виде двумерного распределения, сделанное по отдельной ограниченной по объему выборке, может привести к существенным ошибкам. Поэтому идут на упрощение и переходят от условного математического ожидания случайной величины к условному среднему значению, т.е. принимают M Y | X x y x , где M Y | X x - математическое ожида-
ние случайной величины Y при условии, что случайная величина X приняла значение x.
Корреляционная зависимость между случайными величинами X и Y характеризуется корреляционным моментом
(ковариацией) и коэффициентом корреляции, которые опреде-
ляются формулами соответственно: |
|
|
|
|||||
xy |
cov X,Y M X x Y y |
; |
(6.150) |
|||||
|
|
cov X ,Y |
|
xy |
, |
|
(6.151) |
|
|
x y |
|
x y |
|
|
|
||
|
|
|
|
|
|
|||
где М[] – символ нахождения математического ожидания;x, y – среднеквадратические отклонения случайных величин X и Y.
31 Корреляция [лат. correlatio - соотношение]

|
|
214 |
|
В случае непрерывных X и Y для математических ожи- |
|
даний имеем: |
|
|
|
|
|
x |
M Y / X x yf ( y / x)dy , y |
M X / Y y xf (x / y)dx , (6.152) |
|
|
|
где f(y/x) и f(x/y) – условные плотности.
Для случайного вектора (X, Y) выборка объема n дает n
пар значений признака (x1, y1), (x2, y2), …,(xi, yi),…, (xn, yn). Тогда оценки числовых и корреляционных характеристик слу-
чайных величин X и Y:
оценка математических ожиданий x и y
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
n |
|
|
|
|
|
|
1 |
|
n |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x |
xi ; |
y |
|
yi |
; |
|
|
|
(6.153) |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n i 1 |
|
|
|
|
|
n i 1 |
|
|
|
|
|
|
|
||||||
|
|
|
оценка дисперсий |
2 |
и |
2 |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x |
|
|
|
|
y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
n |
|
|
|
|
|||
|
|
|
|
|
sx2 |
|
|
|
xi |
x 2 |
|
; sy2 |
|
|
|
yi |
y |
2 . |
(6.154) |
||||||||||||||||||
|
|
|
|
|
|
n |
|
|
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
|
|
1 |
|
|
n |
1 |
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
i 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
i 1 |
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
оценка |
|
среднеквадратических отклонений |
x |
и y |
||||||||||||||||||||||||||||||
|
(эмпирический стандарт) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
n |
|
|
|
|
|
|
|
|
|
1 |
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
sx |
|
sx2 |
|
|
xi |
x 2 |
; sy |
|
|
|
|
s y2 |
|
|
|
|
yi |
y 2 (6.155) |
|||||||||||||||||||
n |
1 |
|
|
|
|
|
n 1 |
||||||||||||||||||||||||||||||
|
|
|
|
|
i |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i 1 |
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
эмпирическая ковариация |
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
mxy |
|
|
|
|
|
xi |
x yi |
y ; |
|
|
|
(6.156) |
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n 1 |
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i 1 |
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
эмпирический коэффициент корреляции |
|
|
|
|
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
mxy |
|
|
|
|
xi x yi |
y |
; |
|
|
(6.157) |
||||||||||||
|
|
|
|
|
|
|
|
|
|
r |
|
|
|
i 1 |
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
sx s y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
xi x 2 yi y 2 |
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
||
i 1
Корреляционная зависимость между признаками классифицируется по степени тесноты связи, направлению и виду (аналитическому выражению) связи.
Теснота связи характеризует разброс зависимой случайной величины (результативного признака) относительно ее условного математического ожидания и оценивается коэффициентом корреляции при изменении независимой случайной величины (факторного признака). По степени тесноты связи различают: связь практически отсутствует; слабая; уме-
215
ренная и сильная. Количественные оценки тесноты связи приведены в таблице 6.27.
По форме связи различают прямолинейные (или просто линейные) и нелинейные. Форма связи выражается уравнением регрессии.
Таблица 6.27 - Количественные оценки тесноты связи
Коэффициент корреляции r |
Характер связи |
r 0,3 |
Практически отсутствует |
r = 0,3 - 0,5 |
Слабая |
r = 0,5 - 0,7 |
Умеренная |
r = 0,7 - 1,0 |
Сильная |
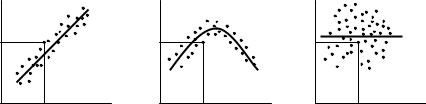
Графически взаимосвязь двух признаков изображается с помощью корреляционного поля (рисунок 6.43). В системе координат на оси абсцисс x откладываются значения факторного признака X, например xi, а на оси ординат – результативного Y, например yi. Каждая пара значений (xi, yi) обозначается на плоскости точкой. Точки группируются вокруг определенной линии, выражающей форму связи (линии регрессии). Если эта линия регрессии представлена прямой (рисунок 6.43, а), то имеет место линейная корреляция, если не является (рисунок 6.43, б), то нелинейная. Если линия (рисунок 6.43, в), параллельна оси абсцисс, то корреляционная связь отсутствует.
y |
|
y |
|
y |
|
y |
|
|
|
y |
|
yi |
|
yi |
y |
yi |
|
xi |
x |
xi |
x |
xi |
x |
а) линейная корре- |
б) нелинейная кор- |
в) отсутствие |
|
||
ляция |
|
реляция |
|
корреляции |
|
|
Рисунок 6.43 - Корреляционные поля |
|
|||
Чем сильнее связь между признаками, тем теснее группируются точки вокруг линии, выражающей форму связи.
В прикладных исследованиях используются следующие виды корреляционной зависимости:
парная корреляция – связь между двумя признаками (результативным и факторным или двумя факторными);
216
частная корреляция – зависимость между результативным и одним факторным признаками при фиксированном значении других факторных признаков;
множественная корреляция – зависимость между ре-
зультативным и двумя и более факторными признаками. Корреляционный анализ заключается в количественном
определении тесноты связи между двумя признаками (при парной связи) и между результативным и множеством факторных признаков (при многофакторной связи). Теснота связи оценивается: при парной корреляции – коэффициентом пар-
ной корреляции; при частной – частными коэффициентами корреляции; при множественной – множественными коэффициентами корреляции (или их квадратами – коэффициентами детерминации).
Для нелинейной связи теснота оценивается корреляционным отношением.
Основной предпосылкой применения корреляционного анализа является необходимость подчинения совокупности значений всех факторных X1, X2,…, Xk и результативного Y признаков k – мерному нормальному закону распределения или близость к нему. Если объем исследуемой совокупности достаточно большой (n > 50), то закон распределения проверяется по критериям Пирсона, Ястремского, Боярского, Колмогорова и др. Если объем совокупности невелик (n < 50), то закон распределения исходной совокупности определяется в результате визуального анализа поля корреляции. Если расположение точек на поле корреляции группируется вокруг прямой линии, то можно предположить, что совокупность исходных данных подчиняется нормальному закону распределения.
Регрессионный анализ заключается в определении аналитического выражения связи, в котором изменение зависимой величины или результативного признака обусловлено влиянием одной или нескольких независимых величин или факторных признаков, а множество всех прочих факторов, также оказывающих влияние на зависимую величину, принимается постоянным.
Для линейно коррелированных случайные величин X и Y
линии регрессии являются прямыми: |
|
|
регрессия Y относительно X |
|
|
y y y / x x x |
; |
(6.158) |

217 |
|
|
регрессия X относительно Y |
|
|
x x x / y y y |
, |
(6.159) |
где x, y – математические ожидания случайных величин X и Y;x/y, y/x – теоретические коэффициенты регрессии.
Коэффициенты регрессии вычисляются по формулам:
y / x |
|
y |
и x / y |
|
|
x |
, |
(6.160) |
|
x |
y |
||||||||
|
|
|
|
|
|
||||
где x, y–среднеквадратические отклонения случайных величин X и Y;- коэффициент корреляции.
Линии регрессии имеют следующий смысл: наилучшее предсказание Y при условии, что X = x0 , есть y x0 . Соответ-
ствующим образом можно интерпретировать и x.
Оценки регрессионных характеристик выборки объема n случайных величин X и Y:
эмпирические коэффициенты регрессии
by / x |
r |
s y |
|
mxy |
и bx / y |
r |
s |
x |
|
|
mxy |
; |
(6.161) |
|||
|
|
|
2 |
|
|
|
||||||||||
s |
x |
s |
s |
y |
s |
2 |
||||||||||
|
|
|
|
|
x |
|
|
|
|
|
y |
|
|
|||
эмпирические прямые регрессии |
|
|
|
y y . |
|
|||||||||||
y y by / x |
x x и x x bx / y |
(6.162) |
||||||||||||||
Оценки регрессионных и других числовых характеристик случайных величин X и Y получают в результате статистической обработки экспериментальных данных с использованием метода наименьших квадратов. При использовании метода пер-
вое уравнение регрессии (6.162) представляют в форме |
|
y a0 a1 x , |
(6.163) |
где a0 y by x x ; a1 by x - искомые коэффициенты уравне-
ния регрессии.
Регрессия может быть однофакторной (парной) и многофакторной (множественной).
По форме зависимости различают:
1)линейную регрессию (см. ф. (6.163));
2)нелинейную регрессию, которая выражается уравнениями вида:
гиперболы |
y a0 |
|
a1 |
(6.164) |
|
x |
|||||
|
|
||||
|
|
|
|
параболы |
y a |
0 |
a x a |
2 |
x2 |
; |
(6.165) |
|
|
1 |
|
|
|
и другие функции.

218
По направлению связи различают:
3)прямую (положительную) регрессию (рисунок 6.44,
а), возникающую при условии, если с увеличением или уменьшение факторного признака значения результативного также увеличиваются или уменьшаются;
4)обратную (отрицательную) регрессию (рисунок
6.44, б), возникающую при условии, если с увеличением или уменьшение факторного признака значения результативного соответственно уменьшаются или увеличиваются.
y |
y |
|
x |
|
x |
а) прямая (положительная) |
б) обратная (отрицательная) |
||
|
регрессия |
|
регрессия |
Рисунок 6.44 - Классификация регрессии по направлению связи
Основной предпосылкой регрессионного анализа является то, что только результативный признак имеет нормальный закон распределения, а факторные признаки X1, X2,…, Xk могут иметь произвольный закон распределения.
Одной из проблем построения уравнения регрессии является ее размерность, т.е. определение числа факторных признаков, включаемых в статистическую модель связи.
Сокращение размерности за счет исключения второстепенных, несущественных факторов позволяет быстрее получить статистическую модель связи. В то же время построение модели малой размерности может привести к тому, что она будет недостаточно полно описывать исследуемое явление (процесс, событие).
Теория статистики рекомендует следующее правило «оптимального числа факторов»: число факторов, включенных в модель связи должно быть в 5 – 6 раз меньше числа наблюдений.
Корреляционно-регрессионный анализ как общее поня-
тие включает в себя измерение тесноты, направления связи и установление аналитического выражения (формы) связи.