

Exploring missing-values patterns |
419 |
values patterns. Ultimately, you want to understand why the data are missing. The answer will have implications for how you proceed with further analyses.
18.3.1Tabulating missing values
You’ve already seen a rudimentary approach to identifying missing values. You can use the complete.cases() function from section 18.2 to list cases that are complete or, conversely, list cases that have one or more missing values. As the size of a dataset grows, though, it becomes a less attractive approach. In this case, you can turn to other R functions.
The md.pattern() function in the mice package produces a tabulation of the missing data patterns in a matrix or data frame. Applying this function to the sleep dataset, you get the following:
>library(mice)
>data(sleep, package="VIM")
>md.pattern(sleep)
|
BodyWgt BrainWgt Pred Exp Danger Sleep Span Gest Dream NonD |
|
|||||||||
42 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
2 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
3 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
9 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
2 |
2 |
1 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
2 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
1 |
1 |
2 |
2 |
1 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
0 |
0 |
3 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
1 |
0 |
0 |
3 |
|
0 |
0 |
0 |
0 |
0 |
4 |
4 |
4 |
12 |
14 38 |
|
The 1s and 0s in the body of the table indicate the missing-values patterns, with a 0 indicating a missing value for a given column variable and a 1 indicating a nonmissing value. The first row describes the pattern of “no missing values” (all elements are 1). The second row describes the pattern “no missing values except for Span.” The first column indicates the number of cases in each missing data pattern, and the last column indicates the number of variables with missing values present in each pattern. Here you can see that there are 42 cases without missing data and 2 cases that are missing Span alone. Nine cases are missing both NonD and Dream values. The dataset has a total of (42 × 0) + (2 × 1) + … + (1 × 3) = 38 missing values. The last row gives the total number of missing values on each variable.
18.3.2Exploring missing data visually
Although the tabular output from the md.pattern() function is compact, I often find it easier to discern patterns visually. Luckily, the VIM package provides numerous functions for visualizing missing-values patterns in datasets. In this section, we’ll review several, including aggr(), matrixplot(), and scattMiss().
The aggr() function plots the number of missing values for each variable alone and for each combination of variables. For example, the code
library("VIM")
aggr(sleep, prop=FALSE, numbers=TRUE)

420 |
|
|
|
|
CHAPTER 18 Advanced methods for missing data |
|
|
14 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
12 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
MissingsofNumber |
68 |
|
|
|
|
|
|
|
|
|
Combinations |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
9 |
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
42 |
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
BodyWgt |
BrainWgt |
NonD |
Dream |
Sleep |
Span |
Gest |
Pred |
Exp |
Danger |
BodyWgt |
BrainWgt |
NonD |
Dream |
Sleep |
Span |
Gest |
Pred |
Exp |
Danger |
Figure 18.2 aggr()-produced plot of missing-values patterns for the sleep dataset
produces the graph in figure 18.2. (The VIM package opens a GUI interface. You can close it; you’ll be using code to accomplish the tasks in this chapter.)
You can see that the variable NonD has the largest number of missing values (14), and that two mammals are missing NonD, Dream, and Sleep scores. Forty-two mammals have no missing data.
The statement aggr(sleep, prop=TRUE, numbers=TRUE) produces the same plot, but proportions are displayed instead of counts. The option numbers=FALSE (the default) suppresses the numeric labels.
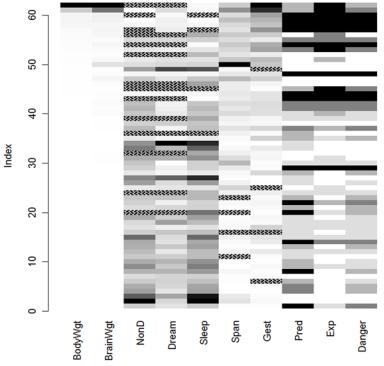
The matrixplot() function produces a plot displaying the data for each case. A graph created using matrixplot(sleep) is displayed in figure 18.3. Here, the numeric data are rescaled to the interval [0, 1] and represented by grayscale colors, with lighter colors representing lower values and darker colors representing larger values. By default, missing values are represented in red. Note that in figure 18.3, red has been replaced with crosshatching by hand, so that the missing values are viewable in grayscale. It will look different when you create the graph yourself.
The graph is interactive: clicking a column re-sorts the matrix by that variable. The rows in figure 18.3 are sorted in descending order by BodyWgt. A matrix plot allows
Exploring missing-values patterns |
421 |
Figure 18.3 Matrix plot of actual and missing values by case (row) for the sleep dataset. The matrix is sorted by BodyWgt.
you to see if the fact that values are missing on one or more variables is related to the actual values of other variables. Here, you can see that there are no missing values on sleep variables (Dream, NonD, Sleep) for low values of body or brain weight (BodyWgt, BrainWgt).
The marginplot() function produces a scatter plot between two variables with information about missing values shown in the plot’s margins. Consider the relationship between the amount of dream sleep and the length of a mammal’s gestation. The statement
marginplot(sleep[c("Gest","Dream")], pch=c(20), col=c("darkgray", "red", "blue"))
produces the graph in figure 18.4. The pch and col parameters are optional and provide control over the plotting symbols and colors used.
The body of the graph displays the scatter plot between Gest and Dream (based on complete cases for the two variables). In the left margin, box plots display the distribution of Dream for mammals with (dark gray) and without (red) Gest values. (Note that in grayscale, red is the darker shade.) Four red dots represent the values of Dream for mammals missing Gest scores. In the bottom margin, the roles of Gest and Dream are