352 |
CHAPTER 15 Time series |
The month plot (top figure) displays the subseries for each month (all January values connected, all February values connected, and so on), along with the average of each subseries. From this graph, it appears that the trend is increasing for each month in a roughly uniform way. Additionally, the greatest number of passengers occurs in July and August. The season plot (lower figure) displays the subseries by year. Again you see a similar pattern, with increases in passengers each year, and the same seasonal pattern.
Note that although you’ve described the time series, you haven’t predicted any future values. In the next section, we’ll consider the use of exponential models for forecasting beyond the available data.
15.3 Exponential forecasting models
Exponential models are some of the most popular approaches to forecasting the future values of a time series. They’re simpler than many other types of models, but they can yield good short-term predictions in a wide range of applications. They differ from each other in the components of the time series that are modeled. A simple exponential model (also called a single exponential model) fits a time series that has a constant level and an irregular component at time i but has neither a trend nor a seasonal component. A double exponential model (also called a Holt exponential smoothing) fits a time series with both a level and a trend. Finally, a triple exponential model (also called a Holt-Winters exponential smoothing) fits a time series with level, trend, and seasonal components.
Exponential models can be fit with either the HoltWinters() function in the base installation or the ets() function that comes with the forecast package. The ets() function has more options and is generally more powerful. We’ll focus on the ets() function in this section.
The format of the ets() function is
ets(ts, model="ZZZ")
where ts is a time series and the model is specified by three letters. The first letter denotes the error type, the second letter denotes the trend type, and the third letter denotes the seasonal type. Allowable letters are A for additive, M for multiplicative, N for none, and Z for automatically selected. Examples of common models are given in table 15.3.
Table 15.3 Functions for fitting simple, double, and triple exponential forecasting models
Type |
Parameters fit |
Functions |
|
|
|
simple |
level |
ets(ts, model="ANN") |
|
|
ses(ts) |
double |
level, slope |
ets(ts, model="AAN") |
|
|
holt(ts) |
triple |
level, slope, seasonal |
ets(ts, model="AAA") |
|
|
hw(ts) |
|
|
|

Exponential forecasting models |
353 |
The ses(), holt(), and hw() functions are convenience wrappers to the ets() function with prespecified defaults.
First we’ll look at the most basic exponential model: simple exponential smoothing. Be sure to install the forecast package (install.packages("forecast")) before proceeding.
15.3.1Simple exponential smoothing
Simple exponential smoothing uses a weighted average of existing time-series values to make a short-term prediction of future values. The weights are chosen so that observations have an exponentially decreasing impact on the average as you go back in time.
The simple exponential smoothing model assumes that an observation in the time series can be described by
Yt = level + irregulart
The prediction at time Yt+1 (called the 1-step ahead forecast) is written as
Yt+1 = c0Yt + c1Yt−1 + c2Yt−2 + c2Yt−2 + ...
where ci = α(1−α)i, i = 0, 1, 2, ... and 0 ≤α≤1. The ci weights sum to one, and the 1-step ahead forecast can be seen to be a weighted average of the current value and all past values of the time series. The alpha (α) parameter controls the rate of decay for the weights. The closer alpha is to 1, the more weight is given to recent observations. The closer alpha is to 0, the more weight is given to past observations. The actual value of alpha is usually chosen by computer in order to optimize a fit criterion. A common fit criterion is the sum of squared errors between the actual and predicted values. An example will help clarify these ideas.
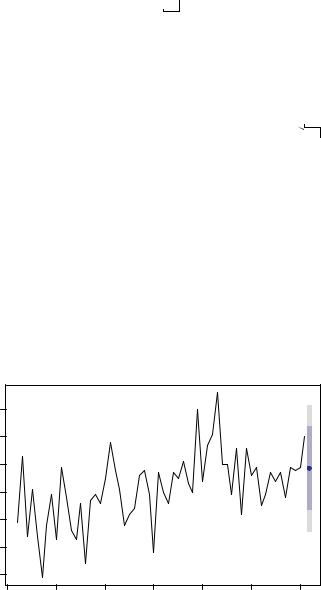
The nhtemp time series contains the mean annual temperature in degrees Fahrenheit in New Haven, Connecticut, from 1912 to 1971. A plot of the time series can be seen as the line in figure 15.8.
There is no obvious trend, and the yearly data lack a seasonal component, so the simple exponential model is a reasonable place to start. The code for making a 1-step ahead forecast using the ses() function is given next.
Listing 15.4 Simple exponential smoothing
> library(forecast)
> |
fit |
<- ets(nhtemp, model="ANN") |
|
|
|
||||
> |
fit |
|
b Fits the model |
|
ETS(A,N,N)
Call:
ets(y = nhtemp, model = "ANN")
Smoothing parameters: alpha = 0.182
Initial states: l = 50.2759
354 |
CHAPTER 15 Time series |
sigma: 1.126
AIC AICc BIC
263.9 264.1 268.1
c 1-step ahead forecast
> forecast(fit, 1)
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95 1972 51.87 50.43 53.31 49.66 54.08
> plot(forecast(fit, 1), xlab="Year", ylab=expression(paste("Temperature (", degree*F,")",)), main="New Haven Annual Mean Temperature")
> accuracy(fit)
ME |
RMSE |
MAE |
MPE |
MAPE |
MASE |
d Prints accuracy measures |
Training set 0.146 |
1.126 |
0.8951 |
0.2419 |
1.749 |
0.9228 |
|
The ets(mode="ANN") statement fits the simple exponential model to the nhtemp time series b. The A indicates that the errors are additive, and the NN indicates that there is no trend and no seasonal component. The relatively low value of alpha (0.18) indicates that distant as well as recent observations are being considered in the forecast. This value is automatically chosen to maximize the fit of the model to the given dataset.
The forecast() function is used to predict the time series k steps into the future. The format is forecast(fit, k). The 1-step ahead forecast for this series is 51.9°F with a 95% confidence interval (49.7°F to 54.1°F) c. The time series, the forecasted value, and the 80% and 95% confidence intervals are plotted in figure 15.8 d.
New Haven Annual Mean Temperature
|
54 |
|
|
|
|
|
|
|
53 |
|
|
|
|
|
|
Temperature (°F) |
50 51 52 |
|
|
|
|
|
|
|
49 |
|
|
|
|
|
|
|
48 |
|
|
|
|
|
|
|
1910 |
1920 |
1930 |
1940 |
1950 |
1960 |
1970 |
|
|
|
|
Year |
|
|
|
Figure 15.8 Average yearly temperatures in New Haven, Connecticut; and a 1-step ahead prediction from a simple exponential forecast using the ets() function

Exponential forecasting models |
355 |
The forecast package also provides an accuracy() function that displays the most popular predictive accuracy measures for time-series forecasts d. A description of each is given in table 15.4. The et represent the error or irregular component of each observation (Yt− Yi ).
Table 15.4 Predictive accuracy measures
Measure |
Abbreviation |
Definition |
|
|
|
Mean error |
ME |
mean( et ) |
Root mean squared error |
RMSE |
sqrt( mean( e2t ) ) |
Mean absolute error |
MAE |
mean( | et | ) |
Mean percentage error |
MPE |
mean( 100 * et / Yt ) |
Mean absolute percentage error |
MAPE |
mean( | 100 * et / Yt | ) |
Mean absolute scaled error |
MASE |
mean( | qt | ) where |
|
|
qt = et / ( 1/(T-1) * sum( | yt – yt-1| ) ), T is the number |
|
|
of observations, and the sum goes from t=2 to t=T |
|
|
|
The mean error and mean percentage error may not be that useful, because positive and negative errors can cancel out. The RMSE gives the square root of the mean square error, which in this case is 1.13°F. The mean absolute percentage error reports the error as a percentage of the time-series values. It’s unit-less and can be used to compare prediction accuracy across time series. But it assumes a measurement scale with a true zero point (for example, number of passengers per day). Because the Fahrenheit scale has no true zero, you can’t use it here. The mean absolute scaled error is the most recent accuracy measure and is used to compare the forecast accuracy across time series on different scales. There is no one best measure of predictive accuracy. The RMSE is certainly the best known and often cited.
Simple exponential smoothing assumes the absence of trend or seasonal components. The next section considers exponential models that can accommodate both.
15.3.2Holt and Holt-Winters exponential smoothing
The Holt exponential smoothing approach can fit a time series that has an overall level and a trend (slope). The model for an observation at time t is
Yt = level + slope*t + irregulart
An alpha smoothing parameter controls the exponential decay for the level, and a beta smoothing parameter controls the exponential decay for the slope. Again, each parameter ranges from 0 to 1, with larger values giving more weight to recent observations.
The Holt-Winters exponential smoothing approach can be used to fit a time series that has an overall level, a trend, and a seasonal component. Here, the model is
Yt = level + slope*t + st + irregulart

356 |
CHAPTER 15 Time series |
where st represents the seasonal influence at time t. In addition to alpha and beta parameters, a gamma smoothing parameter controls the exponential decay of the seasonal component. Like the others, it ranges from 0 to 1, and larger values give more weight to recent observations in calculating the seasonal effect.
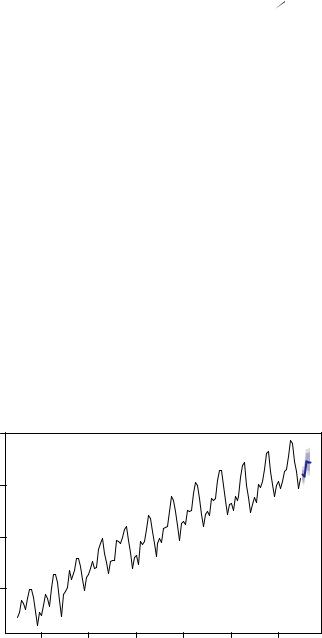
In section 15.2, you decomposed a time series describing the monthly totals (in log thousands) of international airline passengers into additive trend, seasonal, and irregular components. Let’s use an exponential model to predict future travel. Again, you’ll use log values so that an additive model fits the data. The code in the following listing applies the Holt-Winters exponential smoothing approach to predicting the next five values of the AirPassengers time series.
Listing 15.5 Exponential smoothing with level, slope, and seasonal components
>library(forecast)
>fit <- ets(log(AirPassengers), model="AAA")
>fit
ETS(A,A,A)
Call:
ets(y = log(AirPassengers), model = "AAA")
Smoothing |
parameters: |
|
|
|
|
|
|||
alpha |
= |
0.8528 |
b Smoothing parameters |
|
beta |
= |
4e-04 |
|
|
gamma |
= |
0.0121 |
|
|
Initial |
states: |
|
|
|
l = 4.8362 b = 0.0097
s=-0.1137 -0.2251 -0.0756 0.0623 0.2079 0.2222 0.1235 -0.009 0 0.0203 -0.1203 -0.0925
sigma: 0.0367
AIC AICc BIC -204.1 -199.8 -156.5
>accuracy(fit)
|
|
ME |
RMSE |
MAE |
MPE |
MAPE |
MASE |
||
Training |
set -0.0003695 |
0.03672 0.02835 -0.007882 0.5206 0.07532 |
|||||||
> pred <- forecast(fit, |
5) |
|
|
|
|
|
|
||
> pred |
|
|
|
|
|
|
|
||
Point Forecast |
Lo 80 |
Hi 80 |
Lo 95 |
Hi 95 |
c Future forecasts |
||||
|
|
|
|
|
|||||
Jan |
1961 |
6.101 |
6.054 |
6.148 |
6.029 |
6.173 |
|
|
|
Feb |
1961 |
6.084 |
6.022 |
6.146 |
5.989 |
6.179 |
|
|
|
Mar |
1961 |
6.233 |
6.159 |
6.307 |
6.120 |
6.346 |
|
|
|
Apr |
1961 |
6.222 |
6.138 |
6.306 |
6.093 |
6.350 |
|
|
|
May |
1961 |
6.225 |
6.131 |
6.318 |
6.082 |
6.367 |
|
|
|
> plot(pred, main="Forecast for Air Travel", ylab="Log(AirPassengers)", xlab="Time")