

3.6.3. Правила, необходимые для систем автоматического формирования знаний
Каждая ЭС, автоматически формируя знания из фактов, использует свои специфические правила индуктивного обобщения, записанные на соответствующем формальном языке. Тем не менее можно выделить некоторые типы правил, общие для таких систем. Различие будет заключаться в условиях достаточного основания для .применимости правил.
Правило опускания, несущественных условий.При индукции через простое перечисление существенными являются те условия, которым удовлетворяет некоторое множество наблюдаемых объектов и которые затем распространяются, в силу индуктивного предположения, на любые объекты соответствующего класса.
В индуктивных методах Д. С. Милля существенные признаки выделяются установлением максимального сходства и различия наблюдаемых явлений, причем максимальное множество общих признаков считается обнаруженной причиной принадлежности объекта к классу (в методе различия удаление множества существенных признаков сразу нарушает принадлежность объекта к соответствующему классу).
Правила опускания несущественных условий наиболее употребительны в системах машинного обучения.
Правило замены констант в описании объектов на переменные.Примером правил такого типа могут служить процедура антиунификации, правила расширения области определения переменных и области действия кванторов.
Правило замыкания интервала для числовых данных.Пусть задан числовой интервал [а,b] и условие(х), содержащее единственный числовой параметр х. Пусть далее(а)и <(b) -истины. Тогда будем считать, что(х) истинно для любых значений х, таких, что х[а, b].
Правило обобщения «вверх по дереву» классификации для структурированных фактов.Пусть(х) -условие со структурным параметром х. Если(x1),(х2),(х3) -истинны, то будем считать истинным и(х).
Правила «конструктивной» индукции.Под «конструктивной» индукцией понимается процедура порождения новых параметров, характеризующих наблюдаемые объекты, из исходных параметров. Фактически это правило состоит в расширении пространства признаков на основании изучения соответствующей выборки объектов. Среди первых попыток применения «конструктивной» индукции можно выделить такие системы, какAM,EURISKO,INDUCE.
3.7. Дедуктивный вывод на семантических сетях
Как мы говорили, в семантической сети вершины представляют собой понятийные объекты, а дуги – семантические отношения.
Семантические отношения классифицируются на:
а) структурные;
б) логические;
в) процедурные.
Пример: Между понятиями СТУДЕНТ КУРСА и ДИСЦИПЛИНА имеется структурная связь.
Между понятиями УСПЕВАЮЩИЙ и СТУДЕНТ имеется логическая связь: всякий индивидуум, принадлежащий понятию УСПЕВАЮЩИЙ, принадлежит и понятию СТУДЕНТ.
Более сложная логическая связь наблюдается между понятиями УСПЕВАЮЩИЙ, ОЦЕНКА, БАЛЛ и ДИСЦИПЛИНА: индивидуум является успевающим тогда и только тогда, когда его оценка по любой дисциплине не меньше 3 баллов.
Между понятиями СРЕДНЯЯ УСПЕВАЕМОСТЬ, ГРУППА и ДИСЦИПЛИНА имеется процедурная связь: средняя успеваемость студентов по данной дисциплине в группе вычисляется как среднее арифметическое оценок всех студентов из группы, полученных ими по данному предмету.
В системах, основанных на семантических сетях, используются структурные связи, а логические и процедурные связи применяются меньше. Слабое использование логических связей сильно ограничивает дедуктивные способности систем, поэтому в дальнейшем основное внимание будет уделено логическим связям.
Рассмотрим примеры высказываний и их соответствующие семантические сети.. Пусть дано выражение: «куб №2 находится всегда в том же месте, где куб №1». В форме дизъюнкта это выражение имеет вид: В(куб1,х)В(куб2,х).
Здесь В – предикат «находится в месте», а х представляет собой любой индивидуум (связан квантором общности).
Утверждение «куб №1 находится в месте а» будем записывать как
ИВ(куб1,а) или в сокращенной форме
В(куб1,а) и считать консеквентом.
Выражение «куб №1 не находится в месте а» будет иметь вид:
В(куб1,а) Л или в сокращенной записи
В(куб1,а) и оно считается антецедентом.
Если в выражениях имеются кванторы , то переменные, связанные этими кванторами, заменяются скулемовскими функциями, а оставшиеся кванторы общности удаляются, считая, что все переменные, ими связанные, являются универсально квантифицированными. Для каждой совокупности дизъюнктов можно построить эквивалентную ей семантическую сеть. Семантические сети должны быть организованы таким образом, чтобы извлечение, вывод и анализ информации происходил по возможности быстрее и эффективнее. С этой целью над семантическими сетями введем операцию типа раскраски семантических сетей. В этом случае семантические сети представляются в виде раскрашенных ориентированных графов. Представление в раскрашенном виде семантических сетей уменьшает перебор при поиске информации, а также помогает во время вывода новых утверждений, что повышает эффективность работы системы. Примем следующие правила раскраски:
а) цветом Ц1 (непрерывная линия) будем раскрашивать антецеденты;
б) цветом Ц2 (пунктирная линия) – консеквенты.
Поясним сказанное примером. Пусть имеем следующий набор высказываний:
Если куб №1 находится на месте а, то куб №2 тоже находится в том же месте.
Если куб №1 находится на месте а, то куб №3 находится в месте b.
Куб №1 находится в месте а.
В дизъюнктивной форме:
В(куб1,а)В(куб2,а) – P1, P2, P3 – пропозиц. символы
В(куб1,а)В(куб3,b) – P4, P5, P6 – пропозиц. символы
В(куб1,а) – P7 – пропозиц. символ
Соответствующая раскрашенная семантическая сеть представлена на рис.1. В сети буквой Р1обозначена пропозициональная вершина, соответствующая первому высказыванию в целом, пропозициональные вершиныP2 и P3 обозначают соответственно антецедентВ(куб1,а)и консеквентВ(куб2,а)то и другое в целом. Далее расписываются антецедент и консеквент. Антецедент состоит из термов «куб1», «а» и предикатаВ – « находится в месте», а консеквент – из термов «куб2», «а» и того же предикатаВ. Аналогично расписываются остальные высказывания.
Д опустим,
необходимо найти в сети утверждениеВ(куб1,а).
Сначала находим все пропозициональные
символы, связанные с вершинами «В»,
«куб1» и «а». Это – P2,
P5,
P7,
т.к. P2
и P5
являются
антецедентами, то они исключаются, а
вершине P7
соответствует
третье утверждение. Аналогично находится
любое другое утверждение.
опустим,
необходимо найти в сети утверждениеВ(куб1,а).
Сначала находим все пропозициональные
символы, связанные с вершинами «В»,
«куб1» и «а». Это – P2,
P5,
P7,
т.к. P2
и P5
являются
антецедентами, то они исключаются, а
вершине P7
соответствует
третье утверждение. Аналогично находится
любое другое утверждение.
Такой подход использует локальное возбуждение того или иного участка сети, что значительно уменьшает время поиска нужного утверждения. Таким образом, преимущество данного подхода заключается в следующем:
д
Рис. 1
ается эффективная индексация информации с помощью раскрашенных графов, что позволяет обрабатывать сети большой размерности;эффективно удаляетсяиз сети информация, не относящаяся к данному вопросу.
В дальнейшем для простоты будем изображать семантическую сеть, состоящую из дизъюнктивных вершин, т.е. вершин, которым соответствуют исходные дизъюнкты, предикатных вершин и дуг, помеченных двумя цветами. Тогда, после упрощений приведенная выше семантическая сеть будет иметь вид:
г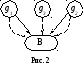 деg1,
g2,
g3
– исходные
дизъюнкты, В
– предикат.
деg1,
g2,
g3
– исходные
дизъюнкты, В
– предикат.
Такие упрощенные сети называются L-сетями, которые задаются четверкой:
L=<G,P,F1,F2> (1)
P – множество предикатных вершин
G – множество дизъюнктных вершин
F1, F2 – отображение G в Р, представляемое множеством дуг, помеченных соответственно цветами Ц1 и Ц2.
L-сети введены нами только для удобства иллюстрации процедур дедуктивного вывода. Семантические сети, являясь формализмом представления знаний в СИИ, обладают, таким образом, следующими особенностями:
в семантической сети представлены такие виды объектов как понятия, события, ситуации, а также специализированные методы выводы. При этом следует учесть, что увеличение номенклатуры объектов снижает однородность сети и приводит к необходимости увеличения количества методов вывода;
многомерность семантических сетей позволяет представить в них многочисленные семантические отношения, связывающие отдельные понятия, понятия и события в предложениях, а также предложения в текстах. Кроме того, в семантической может быть отражена семантическая иерархия специализированных методов вывода, определяющая их взаимоподчиненность;
формализация, как структурное представление семантических знаний, позволяет наложить на эти знания некоторую суперсемантику, отражающую относительную «силу» семантических отношений, что способствует повышению эффективности вывода в семантических сетях;
на каждой стадии решения задачи можно четко полное знание системы (полная семантическая сеть) и текущее знание – возбужденный участок семантической сети, в котором производятся некоторые операции (процесс «понимания», вывода и т.д.).
Необходимо учесть, что семантические представления часто проигрывают в представлении чисто структурных отношений, легко реализуемых в исчислении предикатов или процедурном представлении. Поэтому ряд современных исследований в области представления знаний идет по пути вложения в семантическое представление некоторых фрагментов процедурных или декларативных представлений с целью объединения их преимуществ в новом, комбинированном представлении. В настоящее время разработаны различные виды дедуктивных выводов на семантических сетях как резолютивные, так и нерезолютивные. Рассмотрим резолютивный метод вывода, известный как алгоритм семантической унификации.
Алгоритм семантической унификации двух дизъюнктов такой же, как тот, который мы рассмотрели с вами в прошлой лекции. Этот алгоритм работает при поиске резольвенты двух дизъюнктов.
Описание алгоритма:
если в сети есть вершина свободная от мультидуг, то на следующий шаг, иначе на шаг 8;
выделяем предикатную вершину Р, которая свободна от мультидуг;
вычисляем A={F1(P)} – множество вершин с дугами цвета Ц1, входящих в вершину Р;
вычисляем В={F2(P)} – множество вершин с дугами цвета Ц2, входящих в вершину Р;
F=AB
резольвируем дизъюнкты из множества F по предикату Р. Если получили , то остановка;
в семантическую сеть добавляются все дизъюнкты, сгенерированные в шаге 6, и из семантической сети удаляются все дизъюнкты из множества F, затем переход на шаг 1;
применяем оператор расщепления, пока не получим вершину, свободную от мультидуг и переходим на шаг 2.
Данный алгоритм основан на преобразовании семантических сетей. Теперь рассмотрим алгоритм, в котором в процессе вывода семантическая сеть не изменяется.
Основная идея алгоритма состоит в следующем: для данной предикатной вершины Р выбирается любая контрарная пара литер, которая затем резольвируется. Если вершина содержит другие контрарные пары, то они рассматриваются, как альтернативные, и их выбор происходит только после неудачи с унификацией текущей контрарной пары.
Если в вершину входят дуги только одного цвета (так называемые «чистые» дизъюнкты), то они не влияют на процесс вывода пустой сети и удаляются из рассмотрения. Процесс продолжается до тех пор, пока не будет выведена пустая сеть. Приведем более детальную интерпретацию метода.
Обозначим через CLIST – рабочий список, а ALIST – список альтернатив.
CLIST = 0; ALIST = 0;
A = {F1(g) F2(g)};
множество А модифицируется таким образом, чтобы каждый элемент имел вид (1);
CLIST = A
берется первый элемент из CLIST, имеющий вид (P,g,I), где Р – предикатный символ, g – имя дизъюнкта, а I=1, если дуга (g,P) цвета Ц1 и I=2, если дуга (g,P) цвета Ц2. Из CLIST исключается первый элемент.
Если I=1, то G={F2–1(P)}\g; Если I=2, то G={F1–1(P)}\g, где F1–1 и F2–1 – отображения, обратные F1 и F2.
для всех g’G повторяются шаги 8–15 до тех пор, пока не будет исчерпан список G.
B={F1(g’) F2(g’)}
модифицируется В в соответствии с (1);
берется первый элемент (P’,g’,I’) из списка В и он исключается из этого списка, причем имена Р и Р’ совпадают, а I’=1, если I=2 и I’=2, если I=1. Если таких элементов нет для g’G, то переход на шаг 17.
находим НОУ для Р и Р’
B=B CLIST
B=B
если В=, то процедура завершилась успешно, в противном случае переход на шаг 15.
первым элементом ALIST становится подсписок В.
выбирается первый элемент из ALIST и он удаляется из СLIST, переход на шаг 5.
если ALIST=, то процедура завершилась неудачно, в противном случае в СLIST заносится первый элемент ALIST, и этот элемент удаляется из ALIST.
переход к шагу 5.
Пример:

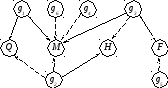 1.
CLIST
= ,
ALIST =
1.
CLIST
= ,
ALIST =
2. A = {F1 (g1) F2 (g1)} = {M, Q}
3. A = {(M(y, a), g1 , 1), (Q(x, y), g1 , 1)}
4. CLIST = A
5–15. G = {g4 , g6}
b = {F1 (g4) F2 (g4)} = {M}
B = { (M (b,a), g4 , 2)}
= {b / y}
В дальнейшем для краткости будем записывать только изменения CLIST и ALIST.
16. CLIST = {(Q(x, b), g1 , 1)}
= {x / u, b / w}
CLIST = {(M(x,v), g2 , 1), (H(v, b), g2 , 1)}
= (b / x, a / v}
CLIST = {(H(a, b), g2 , 1)}
= {a / x, b / z}
ALIST = {{(H(c, b), g2 , 1)}}
CLIST = {(M(b, y), g3 , 1), (F(a, y), g3, 1)}
= {a / y}
CLIST = {(F(a, a), g3 , 1)}.
Тупик и переход к пункту 17.
17. CLIST = {(H(с, b), g2 , 1)} – первый элемент ALIST
ALIST = – исключаем первый элемент из ALIST
= {c / x, b / z}
CLIST = {(M(b, y), g3 , 1), (F(c, y), g3, 1)}
= {a / y}
CLIST = {(F(c, a), g3, 1)}
=
Процедура завершилась успешно. Этот алгоритм позволяет обрабатывать сети большой размерности и эффективно находить решение.