

2.3.5. Булевы классификации
Другим видом классификационной схемы является ситуация, когда таксоны образуют структуру булевой алгебры. В этом случае на выделенной системе классов Kiзадаются теоретико-множественные операции объединения (), пересечения () и разности ( / ).Тогда исходная система классов превращается в булеву алгебру
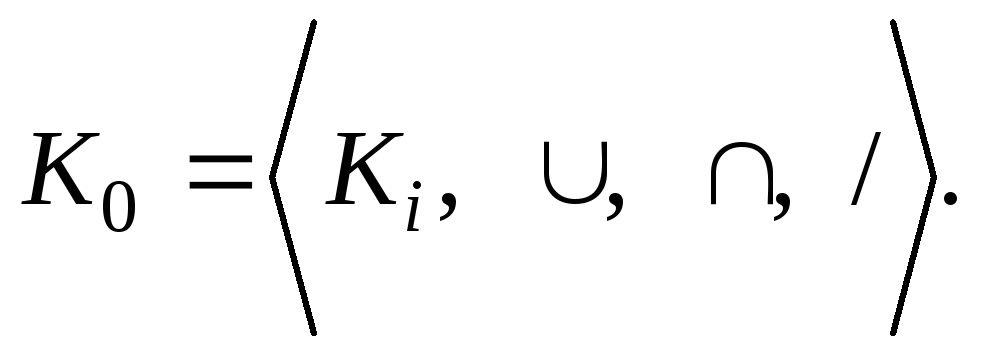
Данный тип классификационной схемы возникает, например, в случае использования дескрипторов для классификации текстов документов. В качестве примера рассмотрим множество терминов, состоящее из четырех дескрипторов: d1,d2,d3,d4. Тогда структура таксонов может состоять (рис. 4)из одного таксона Т0, включающего все наличные тексты; четырех таксонов первого уровня Т11, Т21, Т31, Т41, включающих тексты, содержащие по одному дескрипторуd1, d2,d3или d4;шести таксонов второго уровняT12, Т22, Т32, Т42,T52,Т62, включающих тексты, содержащие по одной из пар дескрипторов (d1,d2), (d1,d3), (d1, d4),(d2,d3), (d2, d4),(d3, d4);четырех таксонов третьего уровня T13,Т23, Т33, Т43, включающих тексты, содержащие тройки дескрипторов (d1,d2,d3), (d1,d2, d4),(d1,d3,d4), (d2,d3,d4), и одного таксона четвертого уровня, включающего тексты, содержащие все четыре дескриптора (d1,d2,d3,d4).

Рис. 4. Булева классификационная структура таксонов документов
Архетипами соответствующих классов документов будут выступать множества значений дескрипторов:
arhK11 = {d1}, arhK21 = {d2}, arhK31 = {d3}, аrhK41 = {d4};
arhK12 = {d1, d2}, arhK22 = {d1, d3}, arhK32 = {d1, d4},
arhK42 = {d2, d3}, arhK52 = {d2, d4}, arhK62 = {d3, d4};
arhK13 = {d1, d2, d3}, arhK23 = {d1, d2, d4}, arhK33 = {d1, d3, d4}, arhK43 = {d2, d3, d4};
arhK14 = {d1, d2, d3, d4}.
Если изучать данную классификационную структуру с точки зрения внутреннего строения ее архетипов, т.е. исходя из наличия в тексте совокупности тех или иных дескрипторов, то получим антиизоморфную картину (рис. 5).
Сопоставление таксономической структуры текстов и их внутреннего строения на основе входящих в них дескрипторов показывает, что объединению таксонов текстов соответствует пересечение множеств дескрипторов, входящих в соответствующие архетипы, а пересечению таксонов текстов –объединение множеств дескрипторов архетипов.
Структура таксонов по включению антиизоморфна структуре всех подмножеств множества дескрипторов {d1, d2,d3, d4},т.е. булевой решетке. Действительно, включение таксона ТiTjозначает, что таксон Тi определяется какими-то дополнительными дескрипторами, т.е. если таксону Тiсопоставить архетипarhКi, а таксону Tj -архетипarhKj, то будет выполняться соотношение arhКiarhKj.
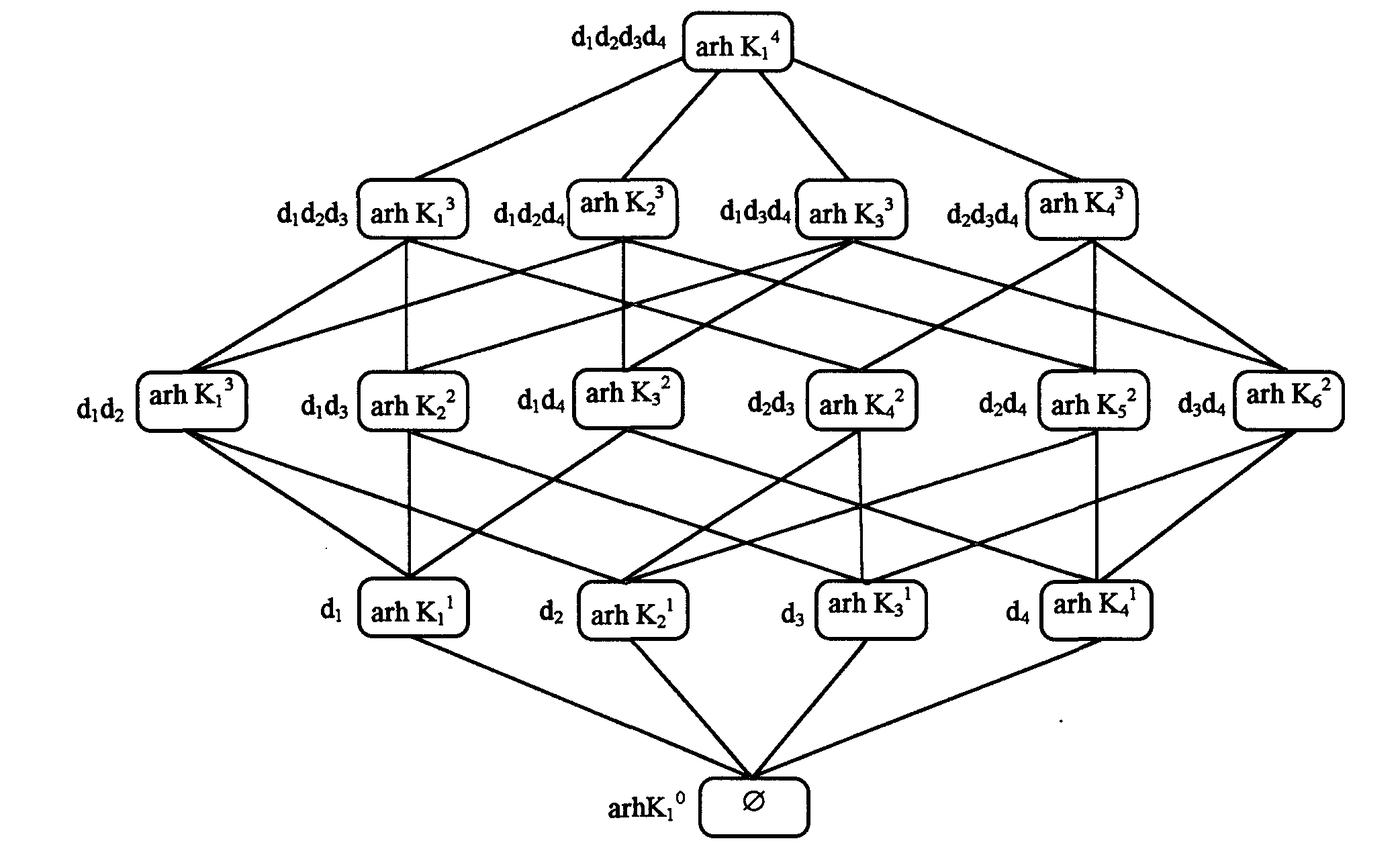
Рис. 5.Антиизоморфная структура архетипов поисковых образов документов
2.3.6. Комбинативные классификации
Комбинативные (фасетные) классификации возникают как результат классификации понятий по совокупности имен и значений их признаков.
Фасеты такой классификации определяются булевыми операциями над именами признаков и образуют булеву алгебру. Очевидно, что классификацию текстов на основании содержащихся в них дескрипторов с этой точки зрения можно рассматривать как однофасетную, так как мы имеем только один признак ДЕСКРИПТОР для всех терминов, используемых при классификации текстов. Но в комбинативных классификациях, как правило, полагают, что классификационные признаки сущностей не являются множественными.
Для выделения таксонов каждый фасет в свою очередь подвергается дополнительному делению на основе использования значений признаков. Так, если имеются признаки А, В, С, то в комбинативной классификации можно выделить три фасета первого уровня –FA,FB,FC; три фасета второго уровня –FAB,FAC,FBCи один фасет третьего уровняFABC.Таксоны первого уровня Т1A, T2A,…,TnA,T1B,...,ТmB, Т1C,...образуются путем деления каждой из фасетFA,FB,FCна основе значений признаков. Таксоны второго уровня могут быть получены путем попарных пересечений таксонов первого уровня и т.д. Количество таксонов на первом уровне определяется суммарной мощностью доменов значений признаков
![]()
Общее число уровней в комбинативной классификации равно количеству признаков.
Как видно из рис. 6,структура таксонов комбинативной классификации по отношению включения не является иерархической. Если рассматривать структуру связеймеждуотдельными фасетами, то получим булеву алгебру.
F
Рис. 6.Фасетная классификационная система
Архетипы классов комбинативной классификации представляют собой подмножество множества пар {(Аi, аji)} имен и значений признаков. Для рассмотренного выше примера архетипами классов второго уровня будут множества:
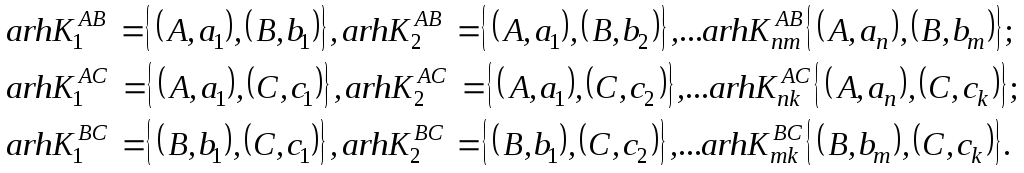
В качестве примера рассмотрим комбинативную классификацию множества сущностей {e1, e2, е3, e4, e5, e6, e7, e8},содержащих признаки с именами А, В, С,Dи значениямиdomА ={a1, а2, а3},domВ ={b1, b2},domС = {c1,c2,c3} иdomD= {d1,d2,d3,d4}.
Пусть значения признаков по сущностям распределены следующим образом:
e1 = (a1, b1, c1, d1), е2 = (a1, b1, c2, d1),
е3 = (a1, b2, c1, d3), е4 = (a1, b3, c2, d3),
e5 = (а2, b2, c1, d4), е6 = (а2, b3, c1, d4),
е7 = (а2, b3, c2, d4), e8 = (а2, b3, c1, d2).
Тогда классификационная решетка рассматриваемой предметной области может быть представлена в виде рис. 7.На первом уровне решетки находятся таксоны, которые определяются одиночными значениями признаков, на втором -они определяются парными комбинациями признаков, на третьем -тройками значений признаков.
Таксон Т0содержит сущности, принадлежащие всей ПО, так как на него не накладывается никаких ограничений, а таксонTABCDпуст вследствие того, что в ПО отсутствуют сущности, обладающие всеми допустимыми значениями признаков одновременно. Отметим также, что в классификационной решетке отсутствуют классы сущностей первого уровня со значениями свойств b1и b2,так как о множествах объектов {e1, e2}и {е3,e5} можно сделать более точное утвержцение, чем то, что эти классы сущностей обладают свойствами b1 и b2.Действительно, таксонT1содержит сущности, обладающие как признаком b1,так и признаком a1,а таксонT1 –сущности, имеющие признаки b2и C1.Множества {e1, e2}и {е3, е5}, выделенные на основании только одного признака b1или b2,являются не классами, а предклассами. При свершении некоторых событий предклассы могут переходить в класс и, наоборот, классы могут превращаться в предклассы.
Отметим, что третий уровень классификационной решетки фактически содержит информацию, совпадающую с признаками ПО, за исключением таксона Т6, в который попали сущностиe6иe8, не различимые на основании классификационных признаков с именами А, В и С, но имеющие различные характеристические признаки: сущностьe6имеет свойствоd4, а сущностьe8 –признак d2.
В работе показано, что для рассматриваемого множества таксонов классификационной решетки могут быть выделены таксоны -образующие, позволяющие путем выполнения над ними теоретико-множественной операции пересечения получить все остальные таксоны решетки.
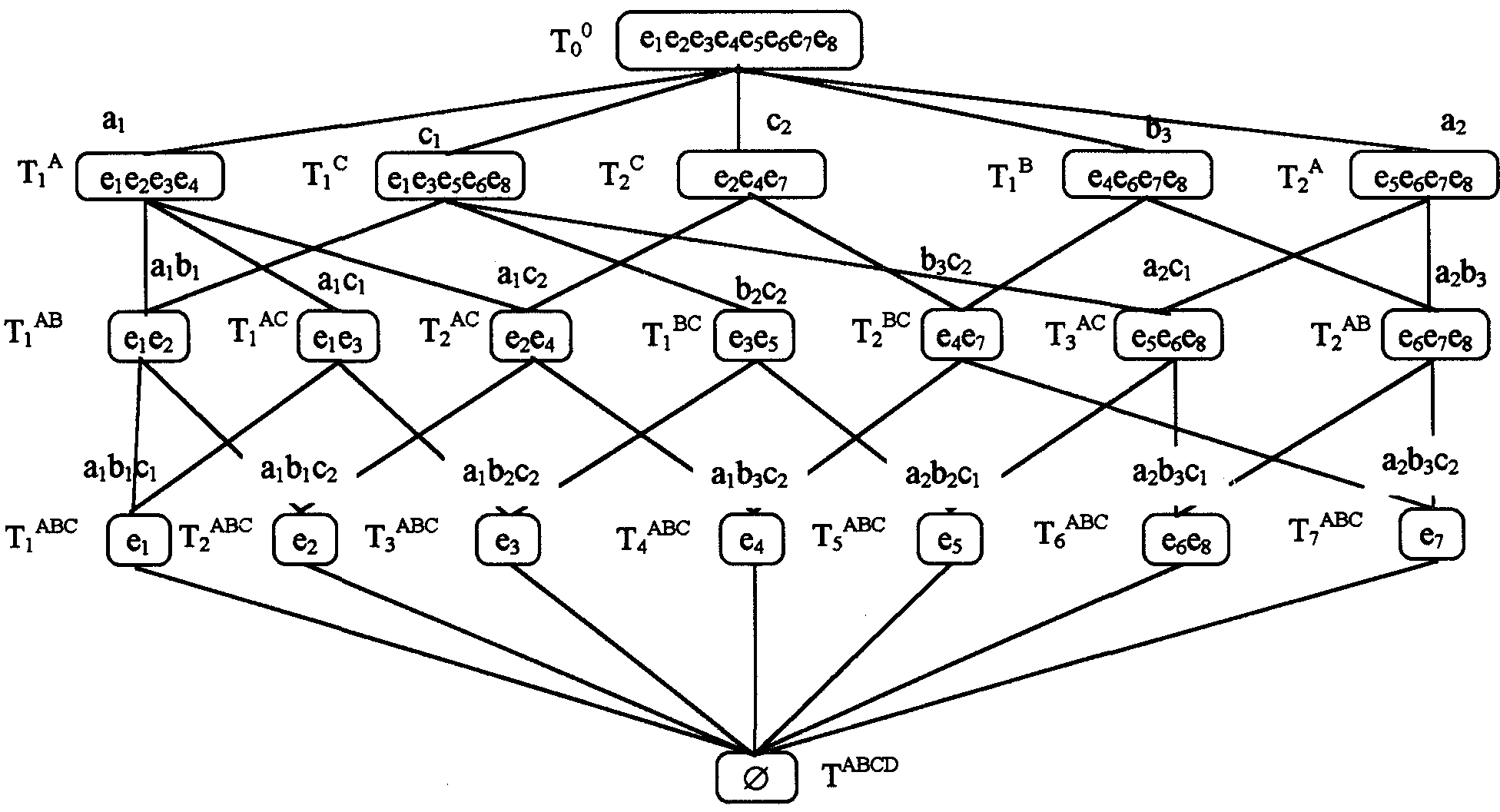
Рис. 7.Пример классификационной решетки гипотетической ПО
Из рис. 7видно, что в качестве классов-образующих для классификационной решетки необходимо взять таксоныT1A,T1C,Т2C,T1B,Т2A,T1AB,T1BC.
Очевиден и общий алгоритм выделения классов-образующих. Для этого достаточно к классам первого уровня решетки присоединить те классы более низких уровней, которые получены из предклассов первого уровня, чтобы получить искомый класс.
Комбинативные классификации имеют ряд преимуществ перед иерархическими классификациями, обеспечивая многоаспектное классифицирование информации, возможность произвольного комбинирования классификационных признаков, большую глубину понятий и возможность гибкого включения новых признаков.