

5.6.2. Метод цепочек
Наиболее простой и естественный способ разрешения коллизий состоит в том, что все элементы с одинаковыми хеш-адресами объединяются в связный список (хеш-цепочку). Тогда хеш-таблица представляет собой массив из N указателей на хеш-цепочки. Такая структура показана на рис. 521.
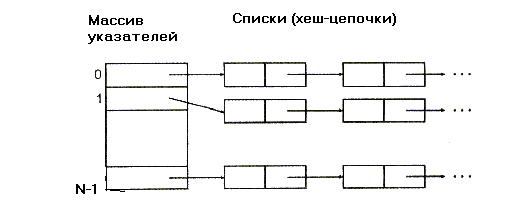
Рис.5.21. Хеш –таблица при использовании метода цепочек
В этом случае в наихудшем случае время поиска пропорционально размеру хеш-цепочки (списка), поскольку нужную хеш-цепочку можно найти с константной сложностью, а для того, чтобы найти элемент в цепочке, придется двигаться по ней последовательно. Операции вставки и удаления элементов выполняются за константное время как в обычном связном списке, обычно их совмещают с операцией поиска, чтобы лишний раз не вычислять хеш-функцию.
Если исходное множество данных состоит из K элементов, а размер массива указателей N, то средняя длина списков будет K/N элементов. Если можно оценить среднее значение K, то можно выбрать N так, чтобы в каждом списке было всего несколько элементов. Тогда время выполнения всех операций будет малой постоянной величиной. Если размер исходного множества непредсказуем или динамично изменяется, данный метод применять не рекомендуется.
Реализация хеш-таблицы с использованием метода цепочек довольно проста. Сами цепочки обычно реализуются в виде однонаправленных связных списков, для хранения указателей на цепочки используется обычный массив. Следуя принятым в данной главе соглашениям, можно записать следующие определения структур данных:
typedef int T_key; //тип ключа, может быть любым
typedef char T_data;//тип связанных данных, любой
struct item //структура элемента данных – ключ и связанные данные
{ T_key key; //ключ
T_data data; //связанные данные
};
struct h_item //структура элемента хеш-цепочки
{ item data; // элемент данных
h_item *next; //ссылка на следующий элемент
}
h_item *h_table[размер массива указателей] //массив указателей на хеш-цепочки
Пример реализации хеш-таблицы для решения конкретной задачи будет приведен ниже.
5.6.3. Хеширование с открытой адресацией
Если в памяти имеется непрерывная область достаточных размеров, то в этом случае можно вообще отказаться от ссылок при реализации хеш-таблицы. Такой способ реализация хеш-таблицы называется хешированием с открытой адресацией [9, 14]. В [3] такая хеш-таблица называется закрытой, очевидно, имеется в виду, что она закрыта для расширения. Этот метод накладывает еще более жесткие ограничения на размер входных данных, чем метод цепочек, но для случая статических входных данных он вполне годится.
Коллизии в этом случае разрешаются следующим образом. В случае, если вычисленный по ключу хеш-адрес оказывается занятым, каким-либо способом находится другая незанятая позиция, куда и помещается новый элемент. Если все позиции заняты, то элемент вставить нельзя (место кончилось). Этот процесс поиска подходящей позиции называется исследованием хеш-таблицы [14], а количество позиций, просмотренных до того, как найдена подходящая позиция, называют количеством проб.
Наиболее простым способом разрешения коллизий является линейное зондирование. При линейном зондировании hi(x)=(h(x)+i) mod N. Предположим, N=8, ключи a,b,c,d имеют хеш-значения h(a)=3, h(b)=0, h(c)=4, h(d)=3. Например, если мы хотим вставить элемент d, а сегмент 3 уже занят, то мы проверим 4-й сегмент, если и он занят, то 5-й, 6-й, 7-й, 0-й, 1-й, 2-й.
Пусть сначала вся хеш-таблица пуста. Поместим в неё последовательно элементы a, b, c, d. Элемент a попадёт в 3-й сегмент, b – в 0-й, c – в 4-й. При вставке элемента d оказывается, что 3-й элемент уже занят. Проверяем 4-й элемент, но он тоже занят. Пятый элемент свободен – туда и помещаем d.
0 |
B |
1 |
пусто |
2 |
пусто |
3 |
A |
4 |
C |
5 |
D |
6 |
пусто |
7 |
пусто |
Посмотрим, как выполняется поиск элемента x. Будем сначала считать, что элементы из хеш-таблицы никогда не удаляются. Тогда при поиске элемента x необходимо просмотреть всю последовательность, начиная с вычисленного хеш-адреса, пока не будет найден x, не встретится пустая позиция, или не будут просмотрены все позиции последовательности. Легко объяснить, почему при достижении пустого элемента поиск можно прекратить – ведь при вставке элемент вставляется в первый пустой сегмент, следовательно, далее элемент находиться не может.
Но если элементы из хеш-таблицы всё-таки удаляются, то при достижении пустого элемента мы уже не можем прекратить поиск, так как возможно, что искомый элемент находится в одной из следующих позиций последовательности. Для повышения скорости поиска иногда используется следующий приём – при удалении элемента его позиция помечается специальным образом, так чтобы ее можно было отличить от изначально пустой позиции. При выполнении вставки такие позиции рассматриваются как свободные.
Вернёмся к вышеприведённому примеру. Пусть нам нужно проверить, содержится ли в множестве элемент e, где h(e)=4. Проверяем сегменты 4,5 и 6. Сегмент 6 пустой, следовательно, элемента e в множестве нет.
Предположим теперь, что мы удалили элемент c и проверяем, содержится ли в множестве элемент d:
0 |
B |
1 |
пусто |
2 |
пусто |
3 |
A |
4 |
удален |
5 |
D |
6 |
пусто |
7 |
пусто |
Мы проверяем элемент 3, затем переходим к элементу 4. Он помечен как удаленный, поэтому не останавливаемся в нём и переходим к элементу 5, где и находим D.
Рассмотренное нами линейное зондирование – далеко не самый лучший способ разрешения коллизий. Как только несколько последовательных элементов будут заполнены (образуя группу), любой новый элемент при попытке вставки в эти позиции будет вставлен в конец группы, увеличивая её длину. Отсюда следует, что при таком расположении элементов увеличивается время выполнения операций поиска, вставки, удаления элемента.
Имеются методы организации хеширования с открытой адресацией, обеспечивающие в среднем меньшее количество проб, с ними можно познакомиться, например, в [10, 14].