

4. Сортировка и родственные задачи
4.1. Общие сведения
4.1.1. Постановка задачи
После изучения фундаментальных структур данных пора переходить к решению прикладных задач, имеющих практическое значение. Рассмотрим такие тесно связанные между собой задачи, как сортировка и поиск данных, которые занимают большую часть компьютерного времени в современных информационных системах. Хотя задача сортировки носит вспомогательный характер по отношению к другим задачам обработки данных, именно с нее удобно начать изучение материала, поскольку алгоритмы сортировки часто являются основой для других алгоритмов. Да они и сами по себе интересны.
Пусть имеется некоторая последовательность элементов произвольного типа (массив или связный список). Сортировкой называется расположение элементов этой последовательности согласно определённому линейному отношению порядка. Наиболее привычным является отношение "", в этом случае говорят о сортировке по возрастанию (более строго — по неубыванию). Отношения сравнения определены для большинства стандартных типов. При определении своего собственного типа пользователь может определить для него и операции сравнения и, таким образом, получает возможность отсортировать данные этого типа.
Сортировка имеет очень много применений, перечислим лишь некоторые из них:
для выполнения быстрого поиска элементов в отсортированной последовательности;
для группировки элементов по некоторому признаку (например, если отсортировать список товаров по стране изготовления, то можно быстро подсчитать количество товаров, которые поставляет каждая из стран, их среднюю цену и т.д.)
для эффективного поиска общих элементов двух или более последовательностей и др.
Прежде чем переходить к характеристикам сортировки, сделаем одно замечание. Обычно предполагается, что элементы сортируемой последовательности представляют собой записи, а упорядочение осуществляется по значениям одного из полей. Это поле называется ключом (key), а остальные поля называются связанными данными (satellite data). Такой подход к сортировке является обычным в базах данных, где данные естественно представлены в виде записей (например, данные о студентах или преподавателях).
Однако предметом данной главы является анализ алгоритмов сортировки, который фактически не зависит от типа сортируемых данных, поэтому с целью упрощения и повышения наглядности программного кода будем считать, что сортируется массив целых чисел. На практике это довольно распространенный случай. Кроме того, можно представить, что целые числа — ключи записей, а при желании любую из приводимых функций легко переработать так, чтобы она сортировала массив записей по значениям одного из полей. В следующей главе, посвященной поиску, мы будем четко отделять ключ и связанные с ним данные.
Описанные ниже алгоритмы с небольшими исправлениями применимы и для связных списков.
4.1.2. Характеристики и классификация алгоритмов сортировки
Сортировка называется устойчивой, если после её выполнения записи с одинаковыми ключами располагаются друг относительно друга в том же порядке, что и до сортировки.
Например, рассмотрим следующую последовательность записей:
<6,'E'>, <2,'B'>, <1,'A'>, <3,'C'>, <1,'D'>.
Пусть ключами будут первые элементы записей. Устойчивый алгоритм сортировки на выходе даст нам последовательность
<1,'A'>, <1,'D'>, <2,'B'>, <3,'C'>, <6,'E'>,
в которой относительный порядок записей <1,'A'> и <1,'D'> остался без изменения. Для неустойчивого алгоритма сортировки также допустим и другой результат:
<1,'D'>, <1,'A'>, <2,'B'>, <3,'C'>, <6,'E'>,
где эти элементы поменялись местами.
Если требуется отсортировать последовательность по составному ключу (т.е. состоящему из нескольких полей), то можно для этого, используя устойчивый алгоритм, последовательно выполнить сортировку по составляющим ключа, взятым в обратном порядке.
Например, чтобы отсортировать последовательность записей вида <имя, фамилия> по фамилии, а записи с одинаковыми фамилиями - ещё и по имени, можно сначала выполнить устойчивую сортировку по имени, а затем - по фамилии:
Исходная последовательность |
Последовательность после сортировки по имени |
Последовательность после сортировки по фамилии |
Васильев Сергей Петров Иван Васильев Иван |
Петров Иван Васильев Иван Васильев Сергей |
Васильев Иван Васильев Сергей Петров Иван |
Важной характеристикой алгоритма сортировки является объём дополнительной памяти, которую он использует при своей работе. Для сортировок, которые использует не более чем константное количество дополнительной памяти, иногда используют термин “in-place”.
Некоторые авторы рассматривают такую характеристику алгоритмов сортировки, как естественность поведения, показывающую, зависит ли существенно число операций алгоритма от степени неупорядоченности исходной последовательности. Считается, что алгоритм ведёт себя более естественно, если почти отсортированную последовательность он "досортировывает" быстрее, чем произвольную.
Выделяют внутреннюю и внешнюю сортировки. При внутренней сортировке все сортируемые данные помещаются в оперативную память компьютера. Внешняя сортировка используется, когда объём данных слишком большой и они не помещается целиком в оперативную память (время сортировки в этом случае существенно зависит от числа операций обмена с внешней памятью, и алгоритмы строятся с учетом этого). В данной главе внешняя сортировка не рассматривается
Имеется очень много различных алгоритмов сортировки, они используют различные идеи. Приведем примерную классификацию методов сортировки (рис. 4.1).
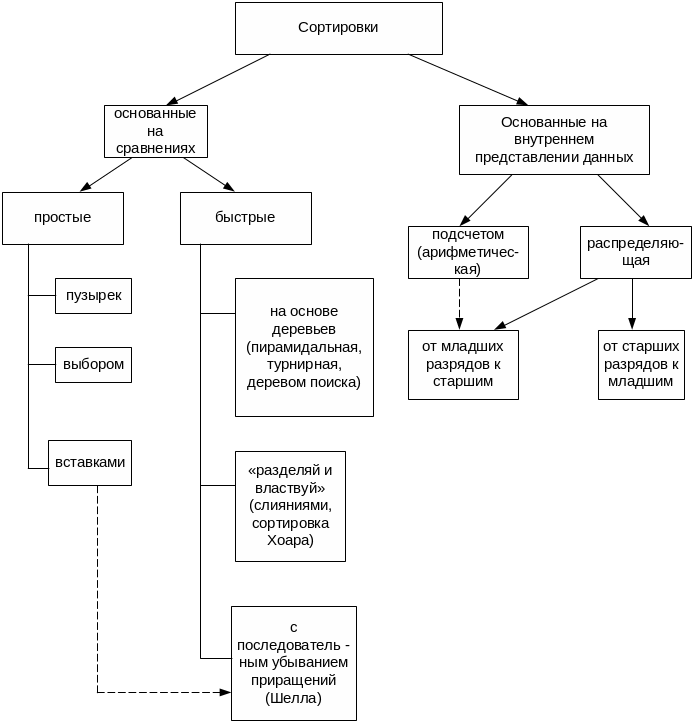
Рис.4.1. Классификация методов сортировки
В данной главе рассмотрим наиболее распространенные способы, охватив практически все направления данной классификации. Начнем с самых простых методов.