

Вставка
Наиболее простым для реализации случаем вставки в бинарное дерево поиска является вставка каждого нового элемента в качестве листа дерева. В [13, 10] рассматривается алгоритм вставки нового элемента в корень, который также не гарантирует сбалансированности дерева, но приводит к тому, что последние добавленные элементы располагаются вблизи корня, следовательно, будут найдены быстрее (в некоторых задачах это важно). Вставка в корень будет рассмотрена немного позже, в данном разделе рассмотрим алгоритм вставки нового элемента в качестве листа.
Алгоритм вставки листа мало отличается от алгоритма поиска, поскольку сама вставка в уже найденную позицию сводится всего лишь к формированию нового элемента и присвоению значения соответствующей ссылке родителя. Поиск позиции для вставки представляет собой передвижение по пути поиска до обнаружения пустой ссылки.
Например, для того, чтобы вставить в дерево на рис.5.1,а новый узел с ключом 50, сначала перемещаемся по пути поиска. При этом обнаружим пустую ссылку на левого сына у узла с ключом 55. Именно в эту позицию и будет вставлен новый элемент (рис.5.2,а).
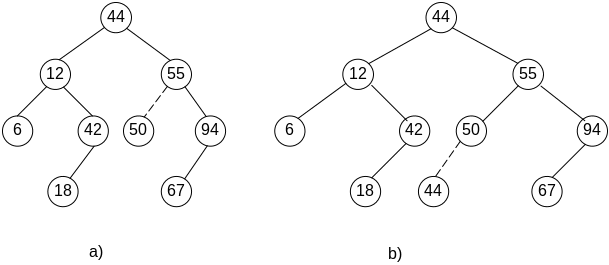
Рис.5.2. Добавление узлов в бинарное дерево поиска
Несколько слов о повторяющихся значениях ключей. Для приложений бинарных деревьев поиска это достаточно редкая ситуация, но принципиально она допустима. Попробуем добавить к дереву на рис.5.2,а еще один элемент с ключом 44. Но такой ключ уже есть у корня. Не обращая внимания на это совпадение, движемся дальше по правой ветви, следуя определению бинарного дерева поиска. Новое значение добавится в качестве левого сына только что добавленного листа со значением 50, оказавшись довольно далеко от корня. Можно сказать и точнее— повторяющееся значение будет крайним левым сыном в правом поддереве своего дубликата. Это наблюдение нам еще пригодится при реализации удаления.
Конечно, алгоритм поиска, который работает до первого совпадения, новый лист вообще никогда не найдет, поэтому для повторяющихся ключей этот алгоритм должен быть доработан.
А главный вывод, который можно сделать по алгоритму вставки — его временная сложность имеет тот же порядок, что и поиск. Временная сложность вставки, как и поиска, линейно зависит от высоты дерева.
Удаление
Удаление узлов выполняется несколько сложнее, чем поиск и вставка, поскольку новый узел можно всегда вставлять в качестве листа, но удалять приходится не только листья, но и внутренние узлы. Рассмотрим 3 основных ситуации.
1. Удаляется лист. Это самый простой случай, т. к. достаточно лишь обнулить соответствующую ссылку у родителя и, конечно, освободить память (это действие обязательно во всех случаях).
2. Удаляется внутренний узел, но имеющий только одно поддерево (левое или правое). Этот случай также особых проблем не представляет, т. к. единственное поддерево удаляемого узла подсоединяется к его родителю, и дерево не теряет своей упорядоченности.
3. Последний случай является самым сложным. У удаляемого внутреннего узла есть оба сына, например, из дерева на рис.5.3,а нужно удалить корень.
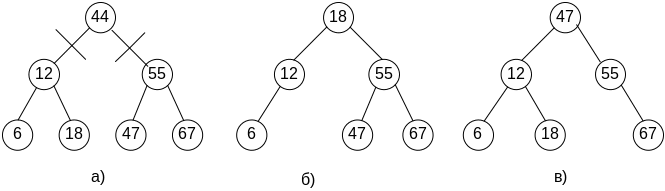
Рис.5.3. Удаления корня из бинарного дерева поиска (два варианта)
Ни один из сыновей удаляемого корня не сможет занять его место, не нарушив упорядоченности дерева. Но все же есть два варианта решения этой задачи, изображенные на рис.5.3,б и 5.3,в. В первом случае это самый последний правый сын из левого поддерева, во втором, наоборот, самый последний левый сын, но из правого поддерева. Оба решения вполне логичны, на самом деле, это два самых близких значения к ключу корня (одно немного меньше, другое немного больше, а при наличии повторяющихся значений вторым способом будет найден дубликат). При реализации для определенности можно следовать любому из двух вариантов.
Несмотря на разветвленную логику алгоритма удаления, количество перемещений по дереву по-прежнему не превышает его высоту. Это значит, что мы опять имеем линейную зависимость от высоты дерева.
Итак, последний вывод — бинарное дерево поиска с хорошей степенью плотности позволяет полностью избежать медленных операций с линейной сложностью от количества узлов дерева, при этом все операции имеют линейную сложность от высоты.
Теперь можно перейти к реализации функций для работы с бинарным деревом поиска.