

3.7.4. Обходы леса
Следуя каноническому соответствию между бинарными деревьями и лесами, можно на основе известных обходов бинарного дерева получить три соответствующие порядка прохождения леса (дерева). Вспомним, что любой упорядоченный лес можно представить в виде трех частей:
корень первого дерева
лес поддеревьев первого дерева
оставшиеся деревья.
На основе этого представления сформулируем правила обхода.
Прямой порядок:
а) посетить корень первого дерева;
б) пройти поддеревья первого дерева (в прямом порядке);
в) пройти оставшиеся деревья (в прямом порядке).
Центрированный порядок:
а) пройти поддеревья первого дерева (в обратном порядке);
б) посетить корень первого дерева;
в) пройти оставшиеся деревья (в обратном порядке).
Обратный (концевой) порядок:
а) пройти поддеревья первого дерева (в концевом порядке);
б) пройти оставшиеся деревья (в концевом порядке);
б) посетить корень первого дерева.
При необходимости применить какой-либо из этих обходов к лесу (дереву) можно сначала построить бинарное дерево, представляющее этот лес, а затем применить соответствующий обход бинарного дерева. Следует заметить, что такой способ не подойдет для обхода в ширину, поскольку в этом случае порядок следования узлов для исходного дерева и эквивалентного бинарного будет отличаться.
В следующем разделе мы покажем, что на уровне реализации возможно внести некоторое усовершенствование в структуру полученного бинарного дерева, которое позволит выполнять нерекурсивные функции обхода без использования вспомогательного стека.
3.7.5. Прошитые деревья
Проанализировав различные способы обхода деревьев, можно сделать вывод, что любой способ требует дополнительных расходов памяти либо во внутреннем стеке программы, либо в виде внешнего стека или очереди. При этом в структуре самого дерева имеется много пустых ссылок (в бинарном дереве их примерно столько же, сколько и непустых). Все это приводит к неэкономичному использованию памяти.
Хорошим способом сократить расходы памяти при обходе являются так называемые прошитые деревья (используем термин из [8]). Идея их очень проста — вместо пустых ссылок хранить обратные ссылки на узлы-предки, тогда в процессе обхода всю (или почти всю) необходимую информацию для перемещения между узлами можно будет получать из самих узлов. Правда при этом в каждом узле придется иметь дополнительное поле-признак, который позволит отличить указателей на сыновей от указателей на родителей. В принципе для такого признака достаточно иметь всего лишь один бит, и иногда такой бит даже находится в структуре самого дерева. Например, если известно, что в узлах хранятся только положительные значения, можно задействовать для этих целей знаковый разряд.
Алгоритмы обхода при применении прошитых бинарных деревьев несколько усложняются, поскольку необходимо предусмотреть проверку признаку, при этом время обхода незначительно увеличивается. Однако в тех случаях, когда важнее экономия памяти, прошитые деревья могут оказаться очень полезными.
Имеются различные способы реализации прошитых деревьев. Наиболее понятным и простым в реализации представляется следующий случай.
Пусть задано упорядоченное дерево произвольного вида (не обязательно бинарное). Если построить эквивалентное ему бинарное дерево, используя представление «левый сын-правый брат», то в полученном дереве у самого правого (младшего) брата гарантированно будет пустой правая ссылка (у него нет правых братьев). Эту ссылку можно использовать как ссылку на отца (обратную ссылку).
Данная идея поясняется с помощью рис.3.11. На рис.3.11,а изображено упорядоченное дерево произвольного вида. Путем изменения связей это дерево преобразуется к бинарному (рис.3.11, б). В полученном бинарном дереве узлы a,d,g и h не имеют правых сыновей, поэтому они могут использоваться для хранения обратных ссылок (они показаны пунктиром). Мы умышленно не стали разворачивать рисунок так, чтобы бинарное дерево приобрело привычный вид, чтобы хорошо была заметна аналогия с циклическими линейными списками, которые используют ту же самую идею, что и прошитые деревья.
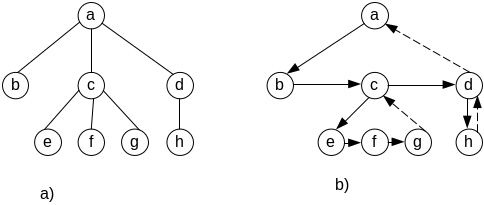
Рис.3.12. Прошитое дерево
Проанализируем порядок выполнения прямого обхода (КЛП). Для данного дерева последовательность посещения узлов будет иметь вид
a b c e f g d h
На рис.3.12,б хорошо видно, что хранимых в дереве обратных ссылок вполне достаточно, чтобы выполнить прямой обход, не используя никакой дополнительной памяти. Структура для представления узлов дерева может иметь, например, такой вид
template <class T>
struct node
{ T data; //данные, которые содержатся в узле
node *son, *brother;// указатели на левого сына и правого брата
bool youngest; // признак самого младшего брата
}
Алгоритм прямого обхода прост [11] и понятен из рис. 3.12, б.
Если у узла имеется сын, то переходим к сыну.
Если нет сына, но имеется брат, то переходим к брату.
Если нет ни сына, ни брата, то находим брата у ближайшего предка, у которого он есть.
Если таких предков нет, то обход закончен.