

2.2.3. Примеры программ с использованием стеков
Стеки широко используются при разработке трансляторов, например, при анализе и вычислении арифметических выражений. Эта задача является предметом отдельного курса, но в качестве введения в проблему приведем компактные примеры анализа и преобразования скобочного выражения.
Пример 1.
Приведенная программа проверяет правильность расстановки скобок в заданной строке текста, длина которой в принципе не ограничена. При этом просматриваются все символы скобок: круглых, квадратных и фигурных. Учитывается, что различные скобки могут быть вложены одна в другую. Список из открывающихся скобок строится по принципу стека. Это значит, что та скобка, которая была помещена в стек последней, будет извлечена из него первой, и легко проверить, соответствует ли закрывающая скобка своей открывающей. Все остальные символы программа игнорирует.
Для проверки соответствия скобок используются две вспомогательные строки с открывающимися и закрывающимися скобками. Стандартная функция strchr() возвращает указатель на найденный символ, поэтому, чтобы найти номер данного символа, приходится вычитать из этого указателя указатель на начало строки. Все остальное просто.
Листинг 2.8 Проверка правильности расстановки всех видов скобок в строке
#include <iostream.h>
#include "stack.h"
#include "stack.cpp"
void main()
{ char s[80];
cout<<"Введите строку, содержащую скобки "; cin.getline(s,80);
stack<char> st;
char *kind1="([{", *kind2=")]}";
for (int i=0; i<strlen(s); i++)
{ if(strchr(kind1,s[i])) st.push(s[i]);
if(strchr(kind2,s[i]))
if((st.isnull())||(strchr(kind1,st.pop())-kind1!=strchr(kind2,s[i])-kind2))
{ cout<<"Ошибка!";cin.get(); return;
}
}
if (!st.isnull()) cout<<"Ошибка!";
else cout<<"Ошибок нет";
st.makenull(); cin.get();
}
Пример 2.
Усложним задачу. Пусть имеется скобочное выражение, в котором присутствуют только круглые скобки. Требуется скобки самого глубокого уровня вложенности оставить без изменения, скобки следующего уровня заменить на квадратные, а все остальные скобки заменить на фигурные.
Листинг 2.9 Преобразование скобок
#include <iostream.h>
#include "stack.h"
#include "stack.cpp"
int main()
{ char s[80]; stack<char> st;
cout<<"Введите строку, содержащую только круглые скобки "; cin.getline(s,80);
int l; //Уровень вложеннности скобок в данный момент
for (int i=0; i<strlen(s); i++)
{ if (s[i]=='(') {st.push(i); l=1;}
if (s[i]==')')
if (st.isnull()) {cout<<"Ошибка!!!"; cin.get(); return 1;}
else {
int p=st.pop();
if (l==2) {s[p]='['; s[i]=']';}
if (l>2) {s[p]='{'; s[i]='}';}
l++;
}
}
if (!st.isnull()) cout<<"Ошибка!!!";
else cout<<"Получили:\n"<<s;
st.makenull(); cin.get();
}
2.3. Реализация очередей
2.3.2. Непрерывная реализация очереди с помощью массива
Реализация очереди при помощи массива немного сложнее, чем реализация стека. Вспомним, что вставка и удаление элементов выполняются с разных концов. Легко сделать вставку в конец массива (хвост очереди), если еще есть свободные ячейки памяти, но сложнее выполнить удаление первого элемента массива (это голова очереди). Поэтому способ реализации, при котором голова очереди совпадает с первым элементом массива, используют только в тех задачах, где элементы добавляются в очередь постепенно, а опустошение очереди происходит сразу целиком. В этом случае достаточно иметь только один дополнительный указатель — на хвост.
В том случае, когда необходимо эффективно реализовать и вставку, и удаление элементов, обычно используют два дополнительных. указателя — на начало очереди (голову) и конец очереди (хвост). Назовем указатели head и tail.В качестве таких указателей могут выступать как индексы элементов массива, так и непосредственно указатели на элементы, это зависит, в основном, от языка программирования. Тогда вставка и удаление элементов очереди реализуется с помощью изменения значений этих указателей (рис.2.3).

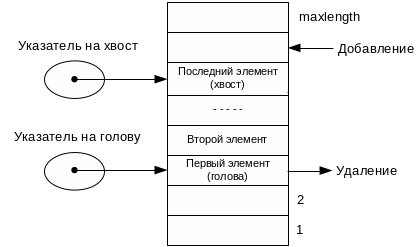
Рис.2.3. Представление очереди при помощи массива и двух указателей (в начальный момент и спустя некоторое время)
При вставках и удалениях элементов очередь как бы передвигается по массиву, постепенно приближаясь к его границе При этом в начале массива появляется свободное пространство за счет освободившихся при удалении элементов. Как только хвост очереди достигнет верхней границы массива, следующие элементы будут добавляться уже в свободные ячейки в начале массива (рис.2.4). Такую реализацию очереди называют кольцевой или циклической.
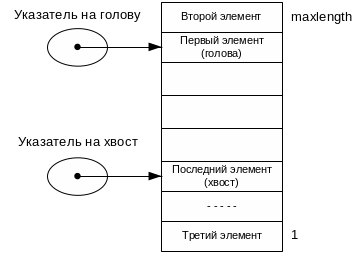
Рис.2.4. Еще одно состояние очереди
Продолжаем заполнять очередь, изображенную на рис. 2.4. В какой-то момент все элементы массива могут оказаться заполнены, в этом случае хвост будет находиться непосредственно перед головой. Теперь будем извлекать элементы один за другим. Двигаясь по масиву, голова наконец дойдет до хвоста (остался один последний элемент). Когда и он будет извлечен, голова опять окажется перед хвостом, точно так же как и в случае полностью заполненной очереди.
Отсюда вывод: по значениям этих двух указателей нельзя определить, пуста очередь или полностью заполнена.
Можно предложить различные способы решения данной проблемы, например:
ввести дополнительную логическую переменную, которая показывает, пуста ли очередь, или переменную, в которой хранится количество элементов очереди;
хранить количество элементов очереди вместо указателя на хвост очереди (индекса хвоста), но тогда его придется вычислять при каждой вставке. Такой способ реализации предлагается в [8].
В любом случае нельзя допускать переполнения очереди, так же как и нельзя извлекать элементы, если очередь пуста, поэтому при реализации операций вставки и удаления необходимо предусмотреть обработку соответствующих аварийных ситуаций.
При реализации очереди на С++ обычно используются непосредствено указатели на голову и на хвост. При этом признаком пустой очереди можно считать нулевое значение этих указателей, не вводя дополнительной переменной. По этим признакам можно отследить аварийную ситуацию при попытке извлечь элемент из пустой очереди. Ситуация, связанная с переполнением очереди, также легко отслеживается, поскольку известно максимальное число элементов очереди maxlength.
Листинг 2.3 содержит циклическую реализацию очереди с помощью массива.
Листинг 2.3. Реализация структуры queue с помощью массива
#include <stdlib.h>
#include <iostream.h>
typedef int type_of_data; // тип элементов (может быть любым)
const maxlength=100;
struct queue
{ type_of_data q[maxlength]; // массив данных очереди
type_of_data *head,*tail; // указатели на голову и хвост
queue() { head=tail=NULL; } // конструктор
// прототипы функций для работы с очередью
void enqueue(type_of_data x); //добавление элемента в хвост очереди
type_of_data dequeue();// извлечение элемента из головы очереди
bool isnull() { return head==NULL; } //проверка на пустоту
void makenull(){ head=tail=NULL; }// очистка очереди (создание пустой очереди)
};
// реализация функций для работы с очередью
void queue::enqueue (type_of_data x) //вставка
{ if (isnull())
{ tail=q; head=q; } // в языке С++ имя массива - указатель на его первый элемент
else
{ tail++; if (tail>q+maxlength-1) tail-=maxlength; // добавили элемент в хвост
if (head==tail) { cerr << "Очередь переполнена\n"; exit(2); }
}
*tail=x;
}
type_of_data queue::dequeue () //извлечение
{ if (isnull()) { cerr << "Очередь пуста\n"; exit(1); }
int x=*head;
if (head==tail) { head=NULL; tail=NULL; }
else { head++; if (head>q+maxlength-1) head-=maxlength; }
return x;
}