

Задача Иосифа (удаление из кольцевого списка)
В качестве второго примера рассмотрим классическую задачу, иллюстрирующую действия с кольцевым списком. Пусть имеется группа людей, которые встали в круг. Затем много раз произносится считалочка из K слов, отсчитывая людей по кругу, при этом каждый K-тый игрок выходит из круга. Все это продолжается до тех пор, пока в круге не останется только один человек.
Программа создает кольцевой список из n элементов, а затем удаляет из него n-1 элементов, которые по номеру являются k-ми относительно первого элемента (если число k (количество слов в считалке) превышает количество элементов, то список обходится несколько раз). На каждом шаге (после удаления очередного элемента) отображается содержимое списка, которое представляет собой индексы оставшихся в нем людей.
Листинг 2.6. Удаление из кольцевого списка (считалочка)
#include <iostream.h>
struct item
{ int index;
item *next;
};
struct list_lk // структура дл кольцевого списка
{ item *last; // указатель на последнего участника
list_lk() { last=NULL; }
void ins(int i); // вставка элемента после элемента *last
void del(int k); // удаление k-го по счету элемента
void print(); // выводим людей, оставшихся в списке
bool isnull() { return last==NULL; }
};
// реализация функций
void list_lk::ins(int i) // i - индекс (номер) участника
{ item *temp=new item;
temp->index=i;
if (!isnull()) // если список непустой
{ temp->next=last->next;
last->next=temp; last=temp;
}
else
{ temp->next=temp; last=temp; //первый и последний человек
}
}
void list_lk::del(int k)
{ if (isnull()) { cerr<<"Список пуст!"; exit(1); }
item *x=last->next, *temp=last; // 1-е слово считалки
for (int i=0; i<k-1; i++) // остальные k-1 слов считалки
{ temp=x; x=x->next;
}
temp->next=x->next; // удаляем элемент *х (ему предшествует *temp)
if (x==last) last=temp;
delete x;
}
void list_lk::print()
{ if (isnull()) { cerr<<"Список пуст!"; exit(1); }
item *temp=last->next;
do // обходим список пока снова не вернемся в его начало
{ cout<<temp->index<<" ";
temp=temp->next;
}
while (temp!=last->next);
cout<<endl;
}
int main()
{ int n,k,i; list_lk l;
cout<<"Введите число участников ";
cin>>n; cin.get();
cout<<"Введите число слов в считалке ";
cin>>k; cin.get();
for (i=0; i<n; i++) // добавляем в список n человек
l.ins(i+1);
for (i=0; i<n-1; i++) { // удаляем по считалке n-1 человек
l.del(k);
cout<<"Count "<<i+1<<": "; // выводим людей, оставшихся //в списке
l.print();
}
return 0;
}
2.6. Рекурсивная обработка линейных списков
2.6.1. Модель списка при рекурсивном подходе
Рассмотренный ранее подход к организации линейных списков ориентирован на итеративную (циклическую) обработку, при которой на каждом шаге выделяется текущий элемент списка и все действия выполняются относительно этого элемента.
Рассмотрим теперь другой подход к организации и обработке списков, основанный на систематическом применении рекурсии и не предполагающий явного выделения текущего элемента [2]. На рис.2.16 изображен линейный список, разделенный на две неравные части: "голову" (первый элемент списка) и "хвост" (все остальное).
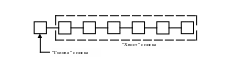
Рис.2.16. Модель линейного списка при рекурсивном подходе к его обработке
Используя такой подход, дадим рекурсивное определение линейного списка. Линейный список —это или пустой список (не содержащий ни одного элемента) или представляет собой упорядоченную пару "голова – хвост", в которой голова есть элемент базового типа α, а хвост, в свою очередь, есть линейный список ( возможно пустой ).
Одной из распространенных форм представления определенных таким образом списков является так называемая скобочная запись, применяемая, например, в языке функционального программирования Lisp. При этом для представления упорядоченной пары "голова – хвост" используется точка как разделитель, поэтому ее часто называют точечной парой. Пустой список обозначается символом Nil.
Например, скобочная запись списка из элементов a, b, c, d типа α имеет вид ( a . ( b . ( c . ( d . Nil ) ) ) ) или в сокращенной записи ( a b c d ). Переход к сокращенной записи производится с помощью отбрасывания конструкции . Nil и удаления точки с парой скобок везде, где они встречаются. Пробелы в сокращенной записи используются для обеспечения однозначности прочтения конструкции, количество их выбирается произвольно.
Такая модель линейного списка предполагает принципиально новый набор базовых операций, отличный от набора базовых операций для модели списка с выделенным текущим элементом.
Выделим базовые операции для рекурсивной обработки списков:
функция формирования пустого списка — назовем ее Nil;
предикат IsNull (список пуст),
функция Head возвращает значение первого элемента (головы списка);
функция Tail возвращает хвост непустогос списка, т.е. список, получаемый из исходного списка после удаления из него головного элемента.
функция Cons (Construct) строит новый список из переданных ей в качестве аргументов головы и хвоста.
Здесь функция IsNull является индикатором, Head и Tail — селекторы, Cons — конструктор.
Данный набор функций является базовым в языках функционального программирования. Например, в языке Lisp функция Head имеет имя CAR, а функция Tail называется CDR (обозначение Cons такое же как и в языке Lisp). Дело в том, что автор языка LISP Джон Маккарти (США) реализовал первую LISP-систему на машине IBM 605 и использовал регистры c названиями CAR и CDR для хранения головы и хвоста списка.
Обратим внимание, что функции Head и Tail могут быть определены только для непустых списков, хотя функция Tail может возвратить и пустой список («хвост»). Функция Cons, в свою очередь, формирует только непустой список. Заметим, что список, разбитый с помощью функций Head и Tail на голову и хвост, можно восстановить с помощью функции Cons.
Определенная проблема возникает с пустым списком, который нельзя использовать как параметр функций Head и Tail, но можно использовать в качестве «хвоста» в функции Cons, которая в этом случае сформирует список из одного единственного элемента. Поэтому в любой реализации придется аккуратно отслеживать ситуацию, когда список является пустым, и уметь формировать пустой список.
Запишем формальную функциональную спецификацию списка. Обозначим список элементов типа α как List(α ), непустой список — Non_null_list( α ), пустой список обозначим Null_list (α).
0. Nil : Null_list(α);
1. IsNull : List( α ) Boolean;
2. Head : Non_null_list( α ) α;
3. Tail : Non_null_list( α ) List( α );
4. Cons : α List( α ) Non_null_list( α );
Выстроим систему аксиом для данных базовых операций. Пусть x имеет тип α, y — список элементов типа α List(α ), z — непустой список Non_null_list( α ).
A1. IsNull( Nil ) = true;
A2. IsNull( Cons( x , y ) ) = false;
A3. Head( Cons( x , y ) ) = x;
A4. Tail( Cons( x , y ) ) = y;
A5. Cons( Head( z ) , Tail( z ) ) = z.
Пустой список рассматривается здесь как значение типа List( α ), возвращаемое функцией без параметров Nil.
Все остальные операции над линейными списками выполняются при помощи соответствующей суперпозиции рекурсивных вызовов данных базовых функций.
Так, доступ к произвольному элементу списка осуществляется с помощью функций Head и Tail.
Например, если список y = (a b c d),
то Head(y) = a, Head(Tail(y)) = b,
а
Head(Tail(Tail(Tail(y)))) = d.
Понятно, что такой способ доступа к элементам сильно отличается от рассмотренного ранее передвижения по списку при помощи перемещения указателя текущего элемента. Например, при рекурсивном подходе невозможно явно выделить однонаправленные и двунаправленные списки, однако можно организовать передвижение по списку в любом направлении, используя разную последовательность рекурсивных вызовов.
Сформировать любой непустой список можно только одним способом — используя функцию Cons. Например, сформируем список из одного и трех элементов:
( a ) = ( a . Nil ) = Cons( a , Nil );
( a b c ) = ( a. ( b. ( c . Nil ) ) ) = Cons( a , Cons ( b , Cons ( c , Nil ) ) ).
Отметим, что построение каждой точечной пары в скобочной записи списка требует однократного применения конструктора Cons. При этом можно очень легко добавлять элементы в «голову» списка однократным вызовом Cons, а добавление в другие позиции требует «разборки» списка при помощи селекторов и последующей сборки при помощи конструктора. При определенном навыке использования рекурсивных вызовов функций можно легко «разбирать» и «собирать» списки, добавляя, удаляя и переставляя элементы