

4.3.3. Быстрая сортировка Хоара
Быстрая сортировка, как и сортировка слиянием, также является реализацией принципа “разделяй и властвуй”. Элементы сортируемого массива переставляются так, чтобы массив условно разделился на две части – левую и правую, причём никакой элемент из левой части не должен превосходить никакого элемента из правой.
5 |
3 |
8 |
5 |
7 |
1 |
4 |
6 |
2 |


2 |
3 |
4 |
1 |
7 |
5 |
8 |
6 |
5 |
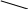
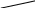
Рис. 4.10. Основная идея алгоритма быстрой сортировки
После этого процедура сортировки вызывается рекурсивно для левой и правой части, в результате чего массив будет отсортирован.
Для получения такого разбиения можно действовать следующим образом. Пусть дан массив a[p..r]. Элемент x=a[p] выбирается в качестве граничного (опорного). Нам нужно добиться, чтобы для некоторого q выполнялось следующие условия:
элементы a[p..q] не больше x
элементы a[q+1..r] не меньше x
pq<r
Строгое неравенство в последнем условии говорит о том, что после разбиения обе получившиеся части должны быть не пустыми, иначе алгоритм зациклится.
Разбиение производится следующим образом. Двигаясь от конца массива к началу, найдём элемент x. Затем, двигаясь от начала к концу, найдём элемент x. Поменяем эти элементы местами. Будем продолжать действовать таким образом, пока не встретимся где-то внутри массива. Пример выполнения разбиения:
Массив и положения индексов |
Комментарии |
4 7 4 2 3 5 I j |
Идём навстречу друг другу: сначала - справа нелево, останавливаемся при a[j]x, затем – слева направо, останавливаемся при a[i]x |
4 7 4 2 3 5 I j |
Меняем местами a[i] и a[j] |
3 7 4 2 4 5 I j |
Снова движемся навстречу друг другу |
3 7 4 2 4 5 i j |
Меняем местами a[i] и a[j] |
3 2 4 7 4 5 ij |
Снова движемся навстречу друг другу |
3 2 4 7 4 5 i j |
Поскольку ij, разбиение завершено |
После разбиения массива рекурсивно выполнятся сортировка получившихся частей a[p..q] и a[q+1..r].
Приведём пример реализации алгоритма. Здесь a – исходный массив, l и r – диапазон в нём, который нужно отсортировать.
void qsort(int a[], int l, int r)
{ if (l>=r) return;
int i=l-1, j=r+1, x = a[l];
for(;;)
{ do {j--;} while (a[j]>x);
do {i++;} while (a[i]<x);
if (i<j)
{ int tmp = a[i]; a[i] = a[j]; a[j] = tmp;
}
else
{ qsort(a,l,j);
qsort(a,j+1,r);
return;
}
}
}
Анализ алгоритма быстрой сортировки
Наихудший случай получается, когда при каждом разбиении получаются наиболее неравные части – один элемент и оставшиеся. При выполнении рекурсивных вызовов получается последовательность разбиений из n, n-1, n-2 и т.д. элементов. Поскольку одно разбиение выполняется за линейное время, то вся сортировка выполняется за Θ(n2).
Среднее время работы алгоритма составляет O(nlogn). Поскольку точный анализ несколько трудоёмок, мы его не приводим, найти его можно, например, в [9]. Однако, данную оценку можно пояснить следующими нестрогими соображениями. Предположим, при каждом разбиении исходная последовательность длины n делится на две части длиной (1/K)n и, соответственно, ((1-K)/K)n, где K – некоторая константа. В результате получается следующее рекуррентное соотношение:
T(n) = T( (1/K)n ) + T( ((1-K)/K)n ) + O(n)
Решением данного соотношения будет T(n)=O(nlogn) (см. [9]). При этом данная оценка справедлива, какой бы маленькой не была константа K, то есть как бы сильно не отличались размеры частей разбиений.
Следует сказать, что худший или близкий к нему случай для алгоритма быстрой сортировки очень маловероятен, и на практике данный алгоритм является, пожалуй, самым быстрым алгоритмом сортировки, основанным на сравнениях элементов. При этом он не требует дополнительной памяти за исключением значений, помещаемых в стек при рекурсивных вызовах.
На самом деле худший случай маловероятен, если мы сортируем действительно случайные последовательности. Реальные же данные зачастую такими не являются – они могут быть уже отсортированы, идти в арифметической или геометрической прогрессии и т.п. Наконец, можно даже предположить, что некий злоумышленник (например, автор олимпиадной задачи по программированию) может специально расположить входные данные так, чтобы произошел как раз худший случай и сортировка «вылетела» с переполнением стека или работала за квадратичное время.
Чтобы обезопаситься от этого, используется рандомизированный вариант данного алгоритма: например, перемешиваются случайным образом все элементы в массиве перед выполнением сортировки либо опорный элемент выбирается не каждый раз одинаково, а случайным образом.