

Частота события находится по следующей формуле:
 . (4.10)
. (4.10)
В качестве точечной оценки для неизвестной вероятности p разумно принимать частоту p*. При этом возникает вопрос о построении доверительного интервала для вероятности p.
Для вероятности p доверительный интервал I = (p1, p2), где – вероятность того, что истинная вероятность попадет в указанный интервал.
Выбор формулы для подсчета доверительного интервала зависит от n. Если число опытов не превосходит 100, то p1 и p2 находятся по следующим формулам:
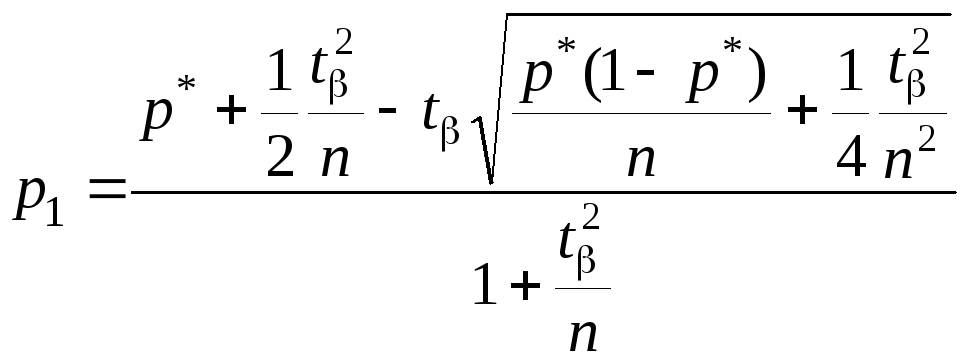 ; (4.11)
; (4.11)
 , (4.12)
, (4.12)
где t – коэффициент Стьюдента, взятый из таблицы для заданного .
Для больших n (порядка сотен) можно пользоваться следующими формулами:
![]() , (4.13)
, (4.13)
![]() . (4.14)
. (4.14)
Приведем значения коэффициентов Стьюдента в зависимости от заданной вероятности (табл. 4.3).
Таблица 4.3
|
|
t |
|
t |
|
t |
|
t |
|
0,80 |
1,282 |
0,86 |
1,475 |
0,91 |
1,694 |
0,97 |
2,169 |
|
0,81 |
1,310 |
0,87 |
1,513 |
0,92 |
1,750 |
0,98 |
2,325 |
|
0,82 |
1,340 |
0,88 |
1,554 |
0,93 |
1,810 |
0,99 |
2,576 |
|
0,83 |
1,371 |
0,89 |
1,597 |
0,94 |
1,880 |
0,9973 |
3,000 |
|
0,84 |
1,404 |
0,90 |
1,643 |
0,95 |
1,960 |
0,999 |
3,290 |
|
0,85 |
1,439 |
|
|
0,96 |
2,053 |
|
|
Из всего вышеприведенного следует общий алгоритм обучения экспертной системы:
1. В качестве исходных данных к проекту задаемся вероятностью правильного ответа экспертной системы и доверительной вероятностью.
2. Определяем набор гипотез и параметров экспертной системы. Если это возможно, строим модель диагностируемой системы.
3. Проводим очередное испытание экспертной системы: предъявляем текущий набор параметров и получаем выбранную экспертной системой гипотезу.
4. В соответствии с методом обучения экспертная система проводит модификацию правил.
5. Увеличивая количество испытаний n на единицу, с учетом общей частоты правильных ответов находим p1 и p2. Если p1 выше заданной вероятности правильного ответа, считаем, что процесс обучения закончен, если нет, переходим к п. 3. Однако возможно возникновение такой ситуации, когда новые примеры перестали влиять на точность классификации. Это значит, что принятый на этапе 2 набор параметров не является удачным. Следует его расширить, а возможно, и ввести в систему новые датчики, т.е. вернуться к п. 2.
Для улучшения набора параметров логично воспользоваться информацией, накопленной экспертной системой в процессе обучения. Фактически экспертная система формирует таблицу функций неисправностей (табл. 4.4).
Таблица 4.4
|
Параметр |
Н1 |
Н2 |
… |
НN |
|
1 |
р11 |
р12 |
|
р1N |
|
2 |
р21 |
р22 |
|
р2N |
|
… |
|
|
|
|
|
М |
рМ1 |
рМ2 |
|
рМN |
В этой таблице рij обозначает значение параметра i при наличии гипотезы Нj. Анализ этой таблицы позволит выявить гипотезы, которые экспертная система не в состоянии различить. Для таких гипотез значения столбцов таблицы функций неисправностей будут совпадать. Следовательно, разумно дополнить экспертную систему новыми параметрами, которые помогут снять это совпадение.
Предположим, что процесс обучения экспертной системы завершился успешно и вероятность правильного ответа превышает заданную. Однако мы уже видели, что вероятность правильного ответа все равно никогда не достигнет единицы. Следовательно, в большинстве случаев будет разумно выдавать не одну подозреваемую неисправность, для которой вероятность возникновения наиболее велика, а несколько подозреваемых неисправностей с наибольшими вероятностями.
Таким образом, мы приходим к нечеткому множеству неисправностей N, характеристическая функция А(х) для которых будет представлять собой вероятность того, что на данный момент времени в системе имеется именно данная неисправность, т.е. в нечеткое множество будут входить принятые гипотезы со своими коэффициентами принадлежности к множеству всех возможных гипотез:
![]() .
.
В соответствии с математическим аппаратом значения рi должны находиться на интервале (0;1). Покажем, как преобразовать значения гипотез в вероятности для обоих методов построения правил экспертной системой:
1. Для экспертной системы, ориентированной на максимальную вероятность, имеем набор значений yk. В случае если среди полученных значений имеются отрицательные, складываем полученные значения с yk min. Затем делим эти коэффициенты на их общую сумму.
2. Для экспертной системы, принимающей решения на основании выбора по наименьшему расстоянию, методика определения коэффициентов характеристической функции будет иная, поскольку, чем меньше подсчитанное значение гипотезы, тем более она вероятна. В соответствии с алгоритмом здесь отрицательные значения yk не могут быть получены.
Далее делим значения для гипотез на сумму значений гипотез:
![]() . (4.15)
. (4.15)
После этого преобразуем полученные значения по формуле
![]() . (4.16)
. (4.16)
Таким образом, нечеткое множество подозреваемых неисправностей может быть сформировано для обоих вариантов построения экспертной системы.
Поскольку имеется два способа построения решающих правил для экспертной системы, невозможно заранее предсказать, какой из них окажется лучшим. Однако если есть возможность довольно точно заранее оценить средние значения параметров, то можно ожидать, что система, обучаемая по средним значениям, станет работоспособной быстрее.
В общем случае целесообразно построить оба варианта системы, а после обучения выбрать ту, которая лучше себя ведет.
Рассмотрим оба принципа обучения на конкретном примере экспертной системы технического диагностирования (ЭСТД) такого сложного объекта, как АСУ ТП «интеллектуального здания», в состав которой входят персональные компьютеры, интеллектуальные датчики, исполнительные устройства автоматики, регуляторы и т.д. Подобная ЭСТД сможет принимать решения об исправности или неисправности тех или иных узлов АСУ ТП.