

3.1.2. Способы выявления структурной неоднородности
Выбор способа выделения структурной неоднородности зависит от характера исходных данных, от цели моделирования, от уровня алгоритмизации и программного обеспечения требуемых расчетов.
На начальном этапе соответствующих исследований выдвигается статистическая гипотеза о структурной неоднородности (в пространстве и во времени) на основе комплексного анализа структуры исходной совокупности показателей с последующей формальной проверкой гипотезы. В случае ее подтверждения необходимо выявить характер изменения степени однородности, причем, либо в области априорно заданной из содержательных представлений о моделируемом процессе, либо – в заранее неизвестной, которую необходимо определить на основе анализа выборочных значений.
Необходимо учитывать следующие предпосылки возможности формулировки вышеуказанной гипотезы:
наличие качественных признаков, непосредственно или косвенно воздействующих на данный показатель;
наличие количественных показателей с особым характером распределения (например, многовершинным, а также, значения которых располагаются только на определенных интервалах числовой оси);
нелинейность парных эмпирических линий регрессии, наличие разрывов и скачков на них;
незначимость индекса корреляции (формула (1.14)).
Используют различные способы выделения выборки из генеральной совокупности, т.е. виды группировок, которые могут быть в зависимости от назначения структурными, типологическими и аналитическими, а в зависимости от количества группировочных признаков – комбинационными, многомерными и одномерными [3,7]. Если преобладают качественные признаки, их количество незначительно и заранее известно, что они неравнозначны, то при достаточном объеме выборки используются многомерные типологические группировки. При наличии большого количества примерно равнозначных признаков (преимущественно количественных) используются комбинационные аналитические группировки. Возможно сочетание различных видов группировок.
3.2. Методы последовательного разбиения
Данная группа методов представляет собой модификацию комбинационных группировок. Процедуры их реализации являются многошаговыми.
Методы последовательного разбиения основаны на анализе коэффициентов вариации качественных признаков, которые характеризуют способность признака различать отдельные элементы выборки, и определяются по формуле
 (3.1)
(3.1)
где
![]() – число градаций классификационного
признака;
– число градаций классификационного
признака;
![]() число признаков,
имеющих i-тую
градацию (
число признаков,
имеющих i-тую
градацию (![]() );
);
– число объектов совокупности
![]() .
.
При оценке полученных значений необходимо учитывать свойства коэффициента вариации:
его величина изменяется в зависимости от характера распределения объектов по классам, т.е. по градациям признака;
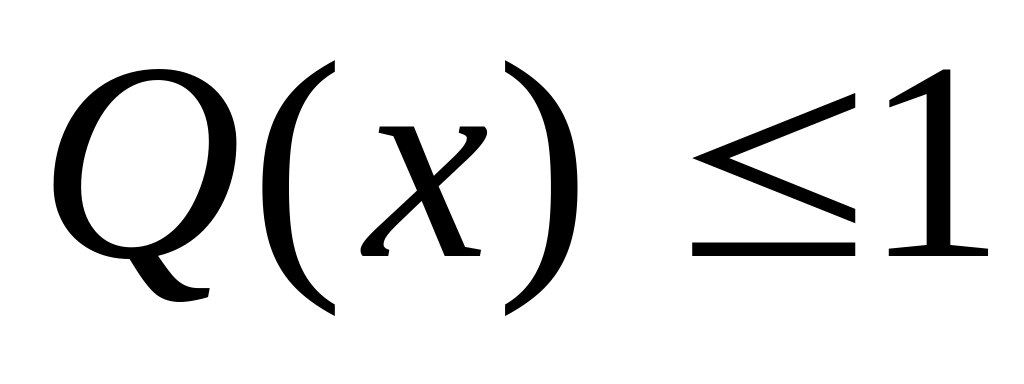 ;
; при равенстве
частот классов и
при равенстве
частот классов и
 – при одной градации признака;
– при одной градации признака;если
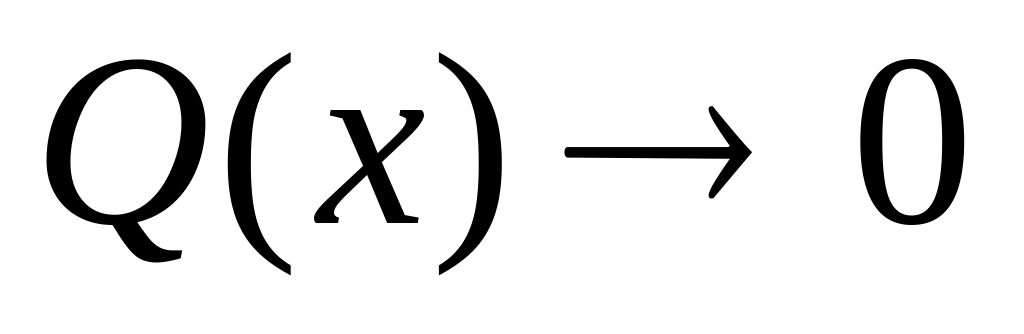 ,
то по данному признаку объекты
распределяются по классам крайне
неравномерно, т.е. большинство объектов
имеют одну градацию, и лишь небольшое
число объектов – другую градацию. В
этом случае может быть принято несколько
решений. Если нет запрета на исключение
рассматриваемого признака и его связь
с моделируемым показателем слабая, то
признаки с незначительной величиной
,
то по данному признаку объекты
распределяются по классам крайне
неравномерно, т.е. большинство объектов
имеют одну градацию, и лишь небольшое
число объектов – другую градацию. В
этом случае может быть принято несколько
решений. Если нет запрета на исключение
рассматриваемого признака и его связь
с моделируемым показателем слабая, то
признаки с незначительной величиной
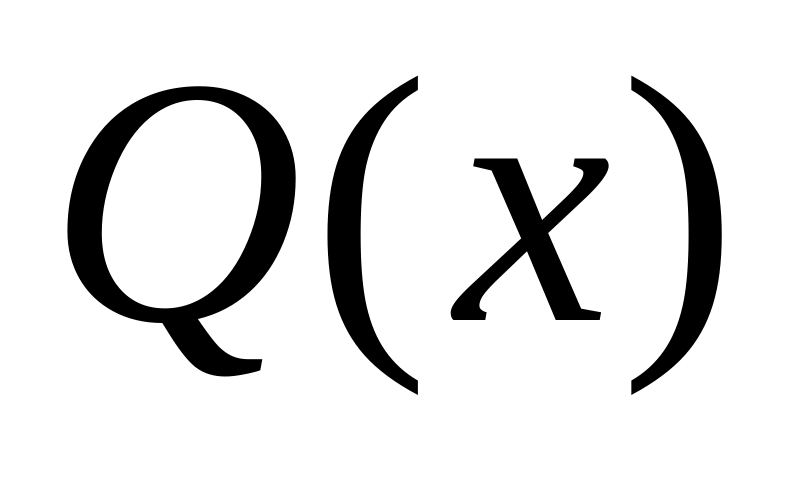 не
рассматриваются. Альтернативное решение
– исключить
несколько объектов, обладающих
оригинальным значением признака.
не
рассматриваются. Альтернативное решение
– исключить
несколько объектов, обладающих
оригинальным значением признака.
При
![]() соответствующим
признакам уделяется особое внимание
при анализе структуры выборки и оценке
степени ее однородности.
соответствующим
признакам уделяется особое внимание
при анализе структуры выборки и оценке
степени ее однородности.
Расчет коэффициента рекомендуется осуществлять в следующей последовательности.
1. Расчет по каждому i-тому признаку.
2. Разбиение всей совокупности по максимальному значению . Если признаков оказалось несколько, то выбор осуществляется по содержательному смыслу, т.е. в зависимости от значимости признака с точки зрения исследователя.
Выделение групп первого шага разделений. Они рассматриваются далее как самостоятельная совокупность, в их пределах осуществляются указанные процедуры до тех пор, пока либо не будет достигнута желаемая степень однородности, либо число элементов в группах не станет меньше установленного.