

4.2. Математичні моделі декодуванняCirc-кодів
У вiдомих на нинiшнiй день [129, 133 - 138] алгоритмах декодування CIRC-кодiв корекцiя помилок здiйснюється або з допомогою одного з декодерiв С1 чи С2 і не бiльше однiєї чи двох помилок. Нижче ми розглянемо можливостi корекцiї максимально можливого числа помилок у кожному з декодерiв С1 та С2, тобто на етапi С1-декодування виявляються та коректуються не бiльше ніж дві помилки, а на етапi С2-декодування коректуються не бiльше як чотири помилки (у подальшому – стратегiя С24). Для вирiшення цiєї задачi достатньо промоделювати на рiвнi програмних алгоритмiв три етапи декодування CIRC-коду: декодування С1, деперемежування ДП2 вiдповiдно до алгоритму, описаного в [134, 136], та декодування С2.
Блок вхiдних даних (рис. 4.1) W = <W1, ..., W12, Q1, .., Q4, W13, ..., W24, P1, ..., P4> складається з 24 iнформацiйних символiв W1, ..., W24 та 8 перевiрних: Q1, ..., Q4, P1, ..., P4, тобто число перевірних символів r значно менше від загальної довжини кодового повідомлення r << n. Перевiрнi символи Q та P вiдкидаються пiсля обчислення синдромiв помилок, вiдповiдно, на етапах С1 та С2 декодування. Нагадаємо, що для полiномного (n, r)-коду синдром – це вектор довжиною n – r, що дорiвнює добутку прийнятої послiдовностi на перевiрну матрицю Н [133 - 138].
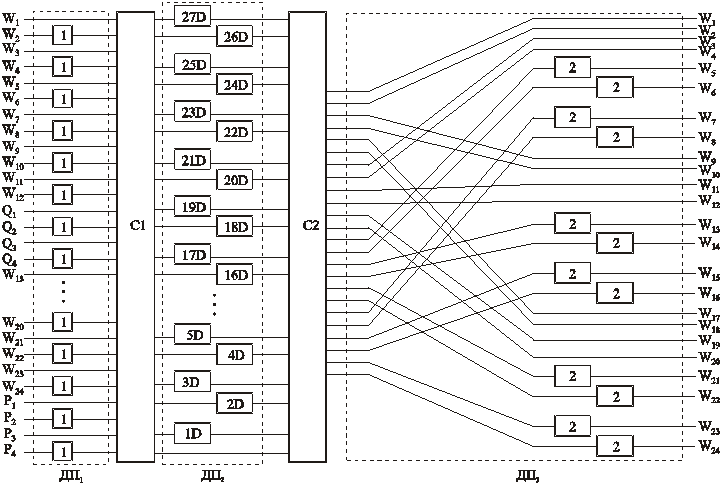
Рис. 4.1. Блок-схема двоетапного алгоритму дії CIRC-декодера
Отже, синдроми помилок S = <S0, ..., S3> обчислюються зi спiввiдношення:
ST = H WT. (4.8)
За вiдсутностi помилок синдроми, що обчисленi згiдно зі спiввiдношенням (4.8), дорівнюватимуть нулю:
S0 = S1 = S2 = S3 = 0.
Припустимо, що iснує хоч би одна помилка в деякому символi Wi, тодi значення помилки можна записати як
![]() ,
,
причому i-й символ (i = 1, ..., n) може бути як перевiрний, так i iнформацiйний. У цьому разі синдроми визначаються так:
 (4.9)
(4.9)
Звiдси розташування помилкового символу встановлюється як
![]() , (4.10)
, (4.10)
а його виправлення забезпечується додаванням значення помилки до значення синдрому:
![]() (4.11)
(4.11)
Якщо помилковi два символи, то
 (4.12)
(4.12)
чи в загальному випадку
![]() ,
(4.13)
,
(4.13)
де К
=
![]() .
.
Вирази для локаторiв помилок мають такий вигляд [52, 137]:
![]() (4.14)
(4.14)
а для значення помилки
 (4.15)
(4.15)
де t
визначається iз рiвняння D2/E
=
![]() шляхом прямого перебору в iнтервалi
шляхом прямого перебору в iнтервалi![]() ,
причому
,
причому
D
= A2/A1,
E
= A3/A1,
A1
= S0S2
+
![]() ,A2
= S1S2
+ S0S3,
A3
= S1S3
+
,A2
= S1S2
+ S0S3,
A3
= S1S3
+
![]() .
(4.16)
.
(4.16)
Визначивши значення чотирьох синдромiв, можна записати систему чотирьох лiнiйних рiвнянь та знайти чотири невiдомі, тобто мiсцезнаходження i значення двох помилок, що пiдлягають корекцiї, чи скоректувати не бiльше ніж чотири помилки.
На основi спiввiдношення (4.8) можна вiдшукати значення помилок для трьох чи чотирьох помилкових символiв.
Визначимо такi значення для трьох помилкових символiв iз рiвняння
![]() (4.17)
(4.17)
тодi помилки в загальному виглядi визначаться як:
![]() ;
;
![]() ;
;
![]() . (4.18)
. (4.18)
Вiдповiдно, для чотирьох помилок
![]() (4.19)
(4.19)
звiдки
![]()
![]()
![]()
![]() (4.20)
(4.20)
Вирази (4.20) становлять основу узагальненого алгоритму корекцiї вiд однiєї до чотирьох помилок, що легко довести пiдставленням виразiв (4.9), (4.12) чи (4.17) у формули (4.20).
Для опису процедур алгоритму знаходження та виправлення помилок [52], що максимально використовує коректуючi можливостi CIRC-коду, розглянемо блок даних iз 28 iнформацiйних та чотирьох перевiрних символiв (див. рис. 4.1). Обчислимо синдроми згiдно з (4.8) i, якщо вони дорiвнюють нулю, – помилок у блоцi даних немає i данi надходять на вихiд декодера, алгоритм переходить до аналiзу наступного блока даних.
Якщо ж синдроми
не дорiвнюють нулевi, то згiдно з (4.16)
обчислюємо додатковi синдроми А1,
А2,
А3.
Рiвнiсть додаткових синдромiв нулевi (А1
= А2
= А3
= 0) свiдчить, що в блоцi даних наявна одна
помилка, мiсцезнаходження якої визначається
виразом (4.10), а її значення – першим із
виразiв (4.9). Якщо ж А1
А2
А3
= 0, то виникає припущення, що iснують двi
помилки. Це припущення пiдтверджується,
якщо мiсцезнаходження двох помилок,
обчислених згiдно з формулами (4.14), не
випадають поза межi інтервалу блока
даних
![]() .
У протилежному разі приймається рiшення,
що помилок бiльше нiж двi. Але якщо помилок
усе-таки двi, то їх значення обчислюються
за формулою (4.15). Гiпотеза про те, що
помилок бiльше нiж двi, виникає також
коли частина додаткових синдромiв
дорiвнює нулевi.
.
У протилежному разі приймається рiшення,
що помилок бiльше нiж двi. Але якщо помилок
усе-таки двi, то їх значення обчислюються
за формулою (4.15). Гiпотеза про те, що
помилок бiльше нiж двi, виникає також
коли частина додаткових синдромiв
дорiвнює нулевi.
Процедура декодування С1 продовжується доти, доки не будуть накопиченi 109 блокiв по 28 символiв (вiдкинуто надлишковi Р-символи). Крiм масиву в 109 блокiв байтних iнформацiйних символiв, паралельно формується однобiтний масив iз 109 прапорцiв (блокова iндексацiя прапорцiв). Значення прапорцiв дорiвнюють нулевi, якщо в блоках вiдсутнi помилки чи вони скоректованi декодером С1, та дорiвнюють одиницi, якщо прийняти гiпотезу про те, що iснують бiльше нiж двi помилки в нагромадженому масивi. Формування масиву зi 109 блокiв пов’язане з алгоритмом другого етапу деперемежування ДП2. Використовуючи масив зi 109 блокiв, будуємо новий блок W = <W1, ..., W28> (див. рис. 4.1) шляхом затримки та перенумерування символiв вiдповiдно до алгоритму деперемежування та структурної схеми [52, 134].
Побудований з допомогою ДП2 блок піддається процедурi декодування С2, яка аналогiчно до С1 починається з обчислення згiдно з формулою (4.8) синдромiв S0, ..., S3 та перевірки їх на рiвнiсть нулевi. Якщо синдроми S0 = S1 = S2 = S3 = 0, то помилок немає i тодi номери блокiв даних перейменовуються в такому порядку: 21, 32, ..., 109108, а 109-м блоком стає новий блок даних, що надходить із декодера С1. Синхронно перейменовується i масив прапорцiв. У подальшому, для кожної сукупностi зi 109 блокiв, повторюються етапи ДП2 та С2 до завершення процесу надходження даних на кодер/декодер.
Якщо ж умова рiвностi нулевi синдромiв Si не виконується, здiйснюється визначення мiсцезнаходження помилки, яка вiдшукується пiсля спiльного деперемежування ДП2 масиву даних та прапорцiв помилок, причому варто зазначити, що даний алгоритм може викликати хибну тривогу, тобто визнати помилковим правильний символ. Крiм цього, установивши припустимий рiвень ймовiрностi помилки на виходi декодера (для мовних каналiв зв’язку ця величина порядку 10-12), можна оптимiзувати стратегiї декодування.