

Висновки до третього розділу
У розділі поставлено задачі удосконалення методів і математичних моделей оцінки параметрів каналів із k-значним кодуванням, зокрема ентропійних параметрів k-значних каналів без завад; властивостей симетричних каналів із k-значним кодуванням; ймовiрностей помилки пiд час декодування k-значних систематичних кодiв; необхідної вносимої надлишковості статичних просторових k-значних структур як теоретичних основ побудови k-значних статичних просторових структур і підвищення надійності проектованих структур за допомогою методів завадостійкого кодування.
Досліджено параметри k-значних каналів без завад у результаті чого отримано тривимірну суттєво нелінійну залежність перепускної здатності від значності та тривалості інформаційного кодового сигналу, що надає широкі можливості оптимального вибору параметрів на етапах проектування та експлуатації.
Досліджено властивості симетричних каналів із завадами та k-значним кодуванням у результаті чого отримано тривимірні суттєво нелінійні залежності верхньої межі перепускної здатності та можливих послідовностей від значності та добутку інтенсивності відмов на час роботи, що надає широкі можливості оптимального вибору параметрів на етапах проектування та експлуатації k-значних структур.
Досліджено ймовiрностi помилки пiд час декодування k-значних систематичних кодiв, що дозволяє розкрити суттєву відмінність апаратурних каналів із k-значним кодуванням порівняно з традиційними двозначними каналами, демонструє вагомість принципу симбіозу в разі застосування надлишкових кодів і його надзвичайно високу ефективність під час практичної реалізації кодів із дуже великою довжиною блока даних та високою коректуючою здатністю. Ймовірність помилки, як універсальний параметр, є сполучною ланкою, оскільки об’єднує в єдине ціле ентропійні моделі апаратурних каналів із надійністю їх роботи та фізичними параметрами цих структур.
Розроблено методику та досліджено статистичні ентропійні математичні моделі необхідної вносимої надлишковості для ряду законів розподілу завад у каналі, що дозволяє забезпечити в k-значних структурах необхiдний рiвень навантажної здатностi, надiйностi, точностi та завадостiйкостi в процесi експлуатацiї.
Основні результати розділу опубліковані в працях [52, 132, 144, 147, 159 - 162].
Розділ 4 моделі, алгоритми та структурИk-значного кодування систематичними кодами
4.1. Математичні моделі кодування кодами Ріда – Соломона з крос-перемежуванням (circ-кодами)
У реальних системах телекомунікацій та засобах запису-відтворення цифрових даних у новітніх обчислювальних системах (інформаційний канал космічного зв’язку, магнітна стрічка, компакт-диск чи жорсткий диск і дискета, а також напівпровідникові запам’ятовуючі пристрої) помилки в бiльшостi випадкiв є залежними (корельованими) і згрупованi в пачки. Для боротьби з ними використовуються не систематичнi, а k-значнi каскадні груповi коди з перемежуванням символiв скiнченного поля ґалуа в процесi кодування, зокрема коди Рiда – Соломона з крос-перемежуванням (CIRC-коди) [52, 132-138, 164–168].
Для прикладу, розглянемо код Ріда – Соломона (РС), що є частковим випадком кодів Боуза – Чоудхурі – Хоквінгема (БЧХ), задаються породжуючим поліномом P(x) = x8 + x4 + x3 + x2 + 1 із коефіцієнтами поля ґалуа GF(28) і мають серед своїх коренів елементи 0, 1, 2, 3, де 0 = 00000010 – примітивний елемент поля GF(28).
Код РС над полем GF(28) і мають має порядок k = 28 – 1. Звідки вкорочений код РС k < 28 – 1 отримуємо, якщо перших 8 бітів інформаційних символів прийняти рівними нулю. Отже, для коду РС (32, 28) над полем GF(28) r0 = 32, n0 = 28, де n0 – число інформаційних символів у блоці довжини r0. Мінімальна кодова віддаль дорівнює d = r0 – n0 + 1 = 32 – 28 + 1 = 5 і тому може виправляти до двох помилок або чотирьох стирань чи довільну комбінацію з r помилок та t стирань таких, що t + 2r d – 1.
Зовнішній код РС
(28, 24) над полем GF(28)
аналогічний до зовнішнього коду РС (32,
28), лише має довжину n1
= 28 символів. Отже, усі оцінки, що виводяться
для декодера С1,
будуть справедливі й для С2. Таким чином,
коректуючий код породжується з допомогою
зображення через циклічну групу, 2m
різних елементів якої: 0,
![]() ,
,![]() ,
,![]() ,
...,
,
...,![]() – утворюють розширене полеґалуа
GF(28),
а кожний елемент поля може бути зображений
як лінійна комбінація 1,
= [x],
– утворюють розширене полеґалуа
GF(28),
а кожний елемент поля може бути зображений
як лінійна комбінація 1,
= [x],
![]() = [x2],
...,
= [x2],
...,
![]() = [
= [![]() ],
тобто ці елементи можуть бути зображені
поліномом
],
тобто ці елементи можуть бути зображені
поліномом
![]() .
.
Для породжуючого многочлена F(x) = x8 + x4 + x3 + x2 + 1 [132–138] поле GF(28) може бути записане, як
a7x7 + a6x6 + a5x5 + a4x4 + a3x3 + a2x2 + a1x1 + a0,
де ai – і-й біт довільного символу з поля GF (2) із елементами 0 та 1.
Із многочлена F(x) отримуємо матрицю Т із m стрічок та m стовпців:

Можна використати зображення через циклічну групу, яке встановлює, що залишок розширеного поля GF(2m) (за винятком нульового елемента) утворює мультиплікативну групу порядку 2m – 1. Якщо елементи поля GF(2m) виражені з допомогою циклічної групи та m бітів утворюють одне слово (символ), а n слів (символів) утворюють блок, то r паритетних (контрольних) символів отримуємо з допомогою перевірної матриці H такого вигляду:
 .
.
Для випадку, коли використовуються чотири контрольних символи, паритетна (перевірна) матриця Н має вигляд:
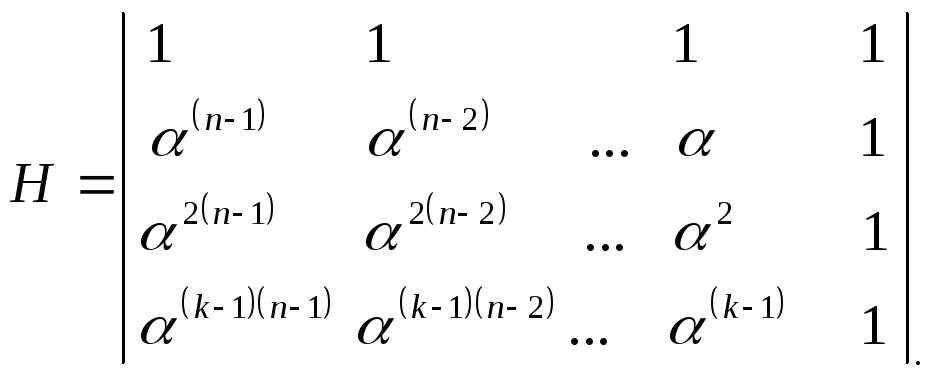
У цьому випадку, якщо позначити поодинокий блок вхідних даних як вектор-стовпець V = (Wn – 1, Wn – 2, W1, W0), де Wi = Wi + ei, ei – помилковий сигнал, то чотири синдроми S0, S1, S2 та S3 – отримуються для них на приймальному боці таким чином:
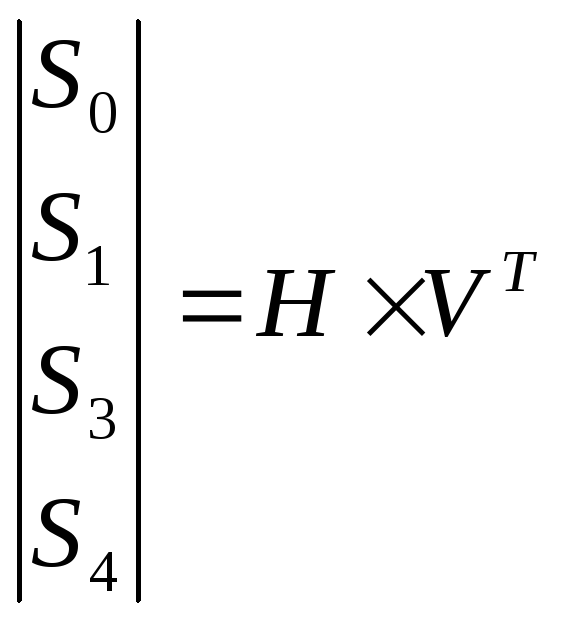 .
.
Чотири паритетних символи p = W3, q = W2, r = W1, s = W0 формуються з використанням таких співвідношень:

Після перетворень отримуємо в матричній формі:
 .
.
Кодування, що здійснюється на передавальному боці, забезпечує описаним методом формування паритетних символів p, q, r та s.
Суть кодування кодом Ріда – Соломона полягає у визначенні, згідно з даними інформаційними символами, значень паритетних символів із допомогою такого співвідношення:
 (4.1)
(4.1)
де
![]() – елементи поля ґалуа,
що складають перевірну матрицю; W1
– інформаційні та перевірні символи
(
– елементи поля ґалуа,
що складають перевірну матрицю; W1
– інформаційні та перевірні символи
(![]() );S1,
..., S4
– синдроми.
);S1,
..., S4
– синдроми.
Перевірні символи необхідно підібрати таким чином, щоби синдроми були нульовими.
Дослiдження розділу 3 для k-значних надлишкових кодiв показали, що для пiдвищення достовiрностi даних необхiдно збільшувати число позицiй кодового сповiщення та зберiгати спiввiдношення числа помилок до числа позицiй у кодовому повiдомленнi <0,5, а також впливати на ймовiрнiсть помилки як на входi, так i в структурі. Узагальнений висновок 1970-х років [58] щодо необхідності впливу на ймовiрнiсть помилки як на входi, так i в структурі, утілено в 1980-х шляхом уведення в каналах із каскадними кодами алгоритмів та пристроїв декореляцiї помилок (перемежування), якi забезпечують зменшення мiри статистичного взаємозв’язку мiж послідовними символами повiдомлення і підвищення завадостійкості. Як показав аналіз розділу 1 найбільшого поширення набула схема з двома рівнями кодування.
Перший етап кодування С2 – це формування зовнішнього коду РС (24, 28), тобто для блоку з 24 вхідних символів обчислюються 4 паритетних символи Q і розташовуються посередині блока даних так, що блок переформовується у 28 символів. Процедура полягає в розв’язку такої системи лінійних рівнянь:
 (4.2)
(4.2)
відокремивши невідомі, отримуємо систему в такому вигляді:
 (4.3)
(4.3)
Розв’язавши її, отримуємо:
 (4.4)
(4.4)
де T1, ..., T4 – вільні члени.
Другий етап С1 формування внутрішнього коду РС (28, 32) здійснюється так: згідно зі заданими 28 інформаційними символами обчислюються перевірні Р-символи й розташовуються в кінці блока даних:
 (4.5)
(4.5)
Зображаючи цю систему так:
 (4.6)
(4.6)
та розв’язуючи її в явному вигляді, отримуємо:
 (4.7)
(4.7)
де V1, ..., V4 – вільні члени системи (4.7).
Аналіз шляхів побудови k-значних структур, з одного боку, та побудови систем штучного інтелекту – з іншого, були б неповними без розгляду математичних моделей k-значного кодування даних із допомогою кодів Ріда – Соломона, адже дослідження на стику дисциплін дозволяють повніше розкрити особливості:
математичного моделювання шляхів кодування CIRC-кодами;
побудови і структури алгоритмів кодування CIRC-кодами;
створення технічних засобів завадостійкого кодування та захисту інформації від несанкціонованого доступу;
характеристик та вимог до технічних засобів кодування CIRC-кодами тощо.