

big_doc_LKG
.pdfФормування вихідної інформації для аналізу і дослідження систем |
81 |
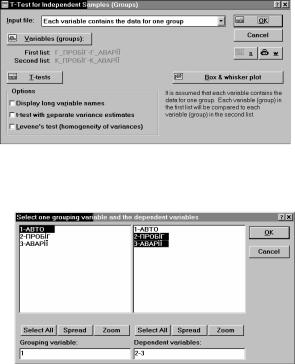
2) у полі INPUT FILE – ВИХІДНИЙ ФАЙЛ зі списку вибрати необхідний варіант представлення вихідних даних. Від варіанту представлення вихідних даних залежить зовнішній вигляд діалогового вікна Т-тесту.
Дані для аналізу у файлі даних можуть бути представлені двома способами:
– ONE RECORD PER CASE (USE A GROUPING VARIABLE) – ОДИН
ЗАПИС НА ВИПАДОК (ВИКОРИСТОВУВАТИ ЗМІННУ ГРУПУВАННЯ). В
цьому випадку для виділення вибірок з сукупності даних використовується так звана змінна групування (рис. 1.9). У наведеному прикладі досліджуються відмінності статистичних даних про пробіг та кількість аварій автомобілів типів КАМАЗ та ГАЗ у парку. Змінна АВТО у цьому випадку використовується як
групувальна.
Вона в процесі аналізу розрізняє дані у змінних ПРОБІГ та АВАРІЇ на дві незалежні вибірки (одна для автомобілів КАМАЗ, друга
– для автомобілів ГАЗ). В якості змінної групування може виступати будь-яка змінна, яка приймає як числові так і текстові значення. Наприклад, можна у змінній групування вка-
зати значення 1 для першої групи, 2 для другої групи і так далі;
– EACH VARIABLE CONTAINS THE DATA FOR ONE GROUP – КОЖНА ЗМІННА МІСТИТЬ ДАНІ ДЛЯ ОДНІЄЇ ГРУПИ. В цьому випадку тест прово-
диться між вибірками, кожна з яких є окремою змінною. Наприклад, дані попереднього прикладу можуть бути представлені у вигляді окремих змінних (рис. 1.10).
Таким чином, для кожної групи даних виділено окрему змінну. Зовнішній вигляд діалогового вікна Т-тесту в такому випадку наведений на рис. 1.11.
3) у випадку використання змінної групування натиснути кнопку  , після чого у діалоговому вікні SELECT ONE
, після чого у діалоговому вікні SELECT ONE
|
GROUP VARIABLE AND THE DEPENDENT |
|
|
VARIABLES – ВИБІР ОДНІЄЇ ЗМІННОЇ |
|
|
ГРУПУВАННЯ ТА ЗАЛЕЖНИХ ЗМІННИХ |
|
Рис. 1.10 – Представлення |
вказати необхідні змінні для аналізу (рис. |
|
1.12). |
||
даних без групування |
||
|
82 |
Розділ 1 |
Рис. 1.11. Діалогове вікно Т-тесту (без групування даних)
Рис. 1.12. Вибір змінної групування та залежних змінних
Після цього у полях CODE FOR GROUP 1 – КОД ДЛЯ ГРУПИ 1 ТА CODE FOR GROUP 2 – КОД ДЛЯ ГРУПИ 2 необхідно ввести значення змінної групування для досліджуваних вибірок (текстові значення вводяться в лапках). Після виконання цих дій діалогове вікно Т-тесту має вигляд, подібний представленому на рис. 1.8;
4) у випадку, коли змінна групування не використовується слід натиснути кнопку  , після чого у діалоговому вікні SELECT TWO
, після чого у діалоговому вікні SELECT TWO
VARIABLES LISTS (LISTS OF GROUPS) – ВИБІР ДВОХ СПИСКІВ ЗМІННИХ
(СПИСКИ ГРУП) вибрати змінні у двох списках (рис. 1.13).
При аналізі Т-тест буде проводитись для кожної пари змінних з цих списків. Після виконання цих дій діалогове вікно Т-тесту має вигляд, подібний представленому на рис. 1.11;

Формування вихідної інформації для аналізу і дослідження систем |
83 |
Рис. 1.13. Вибір змінних у списки для аналізу без групування даних
5) для виконання обчислень натиснути кнопку  діалогового вікна Т-тесту. У випадку використання змінної групування результати обчислення виводяться у електронну таблицю та мають вигляд, подібний представленому на рис. 1.14.
діалогового вікна Т-тесту. У випадку використання змінної групування результати обчислення виводяться у електронну таблицю та мають вигляд, подібний представленому на рис. 1.14.
Рис. 1.14. Результати Т-тесту з групуванням даних
У рядках цієї таблиці містяться досліджувані змінні. У стовпчиках таблиці наведені різні описові та розрахункові статистики, такі як се-
редні значення та стандартні відхилення для груп даних, розрахункове значення критерію Стьюдента (T-VALUE), кількість ступенів вільності (df), гранична імовірність прийняття гіпотези про однорідність вибірок (p), тощо;
У випадку проведення Т-тесту без змінної групування електронна таблиця результатів розрахунку має вигляд, подібний наведеному на рис. 1.15. Назви рядків цієї таблиці містять імена пар змінних, для яких проведений тест.
6) прийняти рішення про однорідність вибірок, тобто про суттєвість розбіжності між вибірками. Розбіжність між вибірками вважається несуттєвою, якщо розрахункове значення граничної імовірності p
перевищує прийнятий для тесту рівень значимості.

84 |
Розділ 1 |
Рис. 1.15. Результати Т-тесту (без групування даних)
Рівень значимості – імовірність неправильного скасування гіпотези, коли вона є вірною, зазвичай приймається рівною 0,1 чи 0,05. По умовчанню у системі STATISTICA встановлений рівень значимості 0,05. Таким чином, при рівні значимості 0,05 для наведених прикладів можна вважати, що відмінність, наприклад, між вибірками Г_ПРОБІГ та К_ПРОБІГ є несуттєвою (0,242 > 0,05) та вибірки можна вважати однорідними, а між вибірками Г_ПРОБІГ та К_АВАРІЇ є суттєвою (0,00019 < 0,05) і вони не можуть вважатись однорідними.
При порівнянні імовірностей слід використовувати підказку систе-
ми STATISTICA. Якщо відмінність між вибірками є значимою (тобто, вибірки неоднорідні) система підсвічує відповідний рядок червоним кольором. Для встановлення рівня значимості, що відрізняється від прийнятого по умовчанню при наявності на екрані вікна результатів тесту використовують кнопку  , розташовану під головним меню системи. Натиснення на кнопку викликає появу меню
, розташовану під головним меню системи. Натиснення на кнопку викликає появу меню
CHANGE ALPHA LEVEL (HIGHLIGHT) – ЗМІНИТИ РІВЕНЬ ЗНАЧИМОСТІ
(ПІДСВІЧУВАННЯ), після вибору якого відкривається діалогове вікно ALPHA LEVEL – РІВЕНЬ ЗНАЧИМОСТІ. У цьому вікні можна вказати необхідний рівень значимості, при якому суттєві розбіжності будуть підсвічуватися.
На рис. 1.16 наведені результати перевірки вибірок на однорідність за даними прикладу 23.
Рис. 1.16. Результати перевірки однорідності вибірок прикладу 23
Формування вихідної інформації для аналізу і дослідження систем |
85 |
Вибірки розглядались як незалежні з іменами  ,
,  та
та  , змінна групування не використовувалась. Всі значення у стовпчику р перевищують прийнятий рівень значимості
, змінна групування не використовувалась. Всі значення у стовпчику р перевищують прийнятий рівень значимості  , отже у таблиці результатів немає жодного підсвіченого червоним рядка. Це означає, що всі ви-
, отже у таблиці результатів немає жодного підсвіченого червоним рядка. Це означає, що всі ви-
бірки є попарно однорідними, належать до однієї генеральної сукупності і у подальшому аналізі всі три вибірки можна об’єднати у одну.
1.6. Визначення мінімально необхідної кількості спостережень для оцінки параметрів розподілу
З математичної точки зору найбільш характерними у транспортних системах є такі види вибірок із генеральної сукупності:
повторна – показники транспортного процесу при обслуговуванні будівельних об’єктів і виробничих цехів на промислових підприємствах; показники процесу формування транспортних партій вантажів для виробничих цехів підприємства; показники роботи автомобільного парку; показники роботи автомобільного транспорту на закріплених маршрутах тощо);
безповторна в натуральних або відносних одиницях – кіль-
кість вантажних одиниць в одному замовленні або в одній транспортній партії; ступінь завантаження транспортного засобу за одну їздку; величина вхідного вагонопотоку або вантажопотоку і ін.;
безповторна у часі – хронометричні спостереження тривалості транспортно-складських операцій).
Отримане на основі спостережень або експерименту середнє значення досліджуваної випадкової величини завжди буде відхилятись від істинного, генерального значення. Величина цього відхилення характеризує точність визначення істинної середньої. Надійність її визначення із заданою точністю за інших однакових умов (кваліфікація дослідника, досконалість використовуваних вимірювальних приладів тощо) повністю залежить від кількості здійснених спостережень. У зв’язку з цим виникає необхідність у визначенні такої кількості спостережень (дослідів, вимірювань), яка забезпечує досліднику упевненість у позитивному результаті. Разом з тим, кількість отриманої інформації для побудови моделі не повинна бути занадто великою. Тому задача полягає у визначенні мінімальної кількості спостережень

86 |
Розділ 1 |
(дослідів, вимірювань), яка дозволяє отримати позитивний результат з необхідною точністю і надійністю.
Наприклад, при вивченні досліджуваної змінної можна висунути таку умову: кількість спостережень повинна бути такою, щоб отримане за цими спостереженнями середнє значення змінної відрізнялось від істинної середньої не більше ніж на 5%, причому надійність цього результату повинна бути не нижче 95%.
Точність статистичної оцінки невідомого параметра  за допомогою його вибіркового значення
за допомогою його вибіркового значення  можна охарактеризувати деяким додатним числом
можна охарактеризувати деяким додатним числом  , для якого буде виконуватись нерівність
, для якого буде виконуватись нерівність
 . (1.74)
. (1.74)
Очевидно, чим меншим буде значення  , тим оцінка є точнішою. Величина
, тим оцінка є точнішою. Величина  характеризує абсолютну точність оцінки генеральної середньої розподілу.
характеризує абсолютну точність оцінки генеральної середньої розподілу.
Точність визначення генеральної середньої може бути також зада-
ною відносною похибкою у процентах
 . (1.75)
. (1.75)
Спостереження (досліди) вважаються точними, якщо  , середньої точності при
, середньої точності при  і малоточними, якщо
і малоточними, якщо  .
.
Надійність оцінки невідомого параметра згідно з його вибірковим значення відбивається довірчою ймовірністю  , з якою виконується нерівність (1.74)
, з якою виконується нерівність (1.74)
. (1.76)
Вираз (1.76) може бути записаний у вигляді
. (1.77)
Інтервал  , в якому з імовірністю
, в якому з імовірністю  міститься невідомий параметр
міститься невідомий параметр  , називається довірчим.
, називається довірчим.

Формування вихідної інформації для аналізу і дослідження систем |
87 |
Із викладеного виходить, що довірчий інтервал характеризує точність спостережень, а довірча ймовірність – імовірність того, що дійсне значення випадкової величини попаде в даний довірчий інтервал. Довірча імовірність характеризує не оцінювані параметри досліджуваної вибірки, а тільки межі довірчого інтервалу в різних вибірках генеральної сукупності. Величина  показує в частках одиниці або процентах кількість вибірок у генеральній сукупності, в яких зустрічається оцінюваний параметр з даним довірчим інтервалом. На практиці у більшості випадків задаються надійністю, що дорівнює
показує в частках одиниці або процентах кількість вибірок у генеральній сукупності, в яких зустрічається оцінюваний параметр з даним довірчим інтервалом. На практиці у більшості випадків задаються надійністю, що дорівнює
0,90; 0,95 або 0,99.
При плануванні і проведенні спостережень досліджуваних процесів або явищ задача полягає у тому, щоб за заданою регламентованою точністю  або
або  і довірчою імовірністю
і довірчою імовірністю 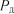 визначати мінімальну кількість вимірів випадкової величини, які гарантують необхідні зна-
визначати мінімальну кількість вимірів випадкової величини, які гарантують необхідні зна-
чення , і |
. |
|
|
В реальних виробничих процесах значення величин |
, і |
ви- |
|
бираються із конкретних вимог, що висуваються до припустимих відхилень досліджуваного параметру у даній вибірці. Підставою для обґрунтування величин абсолютної або відносної регламентованої точності можуть бути:
–обмеження, які пов’язані з виконанням технологічного процесу (швидкості руху транспортних засобів; режими роботи вантажних пунктів; наявні обсяги матеріальних, енергетичних і людських ресурсів і ін.);
–технічні умови на транспортні процеси (формування вантажних одиниць, кріплення вантажів на транспортних засобах, наван- таження-розвантаження транспортних засобів тощо);
–нормативи на певні показники транспортного процесу (завантаження транспортних засобів; тривалість виконання вантажних операцій; витрачання енергетичних, матеріальних і трудових ресурсів і ін.);
–точність вимірювальних пристроїв (ваги, дозатори, спідометри,
енерголічильники і ін.).
Розглянемо методи визначення мінімального обсягу вибіркових спостережень для деяких видів розподілу випадкових величин, які найчастіше зустрічаються в практиці дослідження параметрів транспортного процесу.

88 |
Розділ 1 |
1.6.1. Нормальний розподіл
1.6.1.1. Генеральне стандартне відхилення відоме. На практиці за генеральне можна прийняти стандартне відхилення  , обчислене за вибіркою обсягом
, обчислене за вибіркою обсягом  . Тоді абсолютна точність оцінки визначається із залежностей:
. Тоді абсолютна точність оцінки визначається із залежностей:
для випадкової повторної вибірки
|
; |
(1.78) |
для випадкової безповторної вибірки |
|
|
|
, |
(1.79) |
де |
– гарантований коефіцієнт; |
|
|
– чисельність сукупності із якої здійснюється відбір. |
|
При використанні відносної точності маємо такі залежності: |
|
|
для повторної вибірки |
|
|
|
; |
(1.80) |
для безповторної вибірки
, (1.81)
де  – оцінка генеральної середньої, отримана із вибірки об’ємом
– оцінка генеральної середньої, отримана із вибірки об’ємом  ;
;
 – коефіцієнт варіації.
– коефіцієнт варіації.
Значення  для різних значень
для різних значень 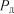 приймається за табл. 1.29. Розв’язуючи рівняння (1.76) і (1.78) відносно
приймається за табл. 1.29. Розв’язуючи рівняння (1.76) і (1.78) відносно  , отримаємо: для повторної вибірки
, отримаємо: для повторної вибірки
; |
(1.82) |

Формування вихідної інформації для аналізу і дослідження систем |
89 |
для безповторної вибірки
. (1.83)
При використанні величини  формули (1.82) та (1.83) набувають вигляду:
формули (1.82) та (1.83) набувають вигляду:
для повторної вибірки
; |
|
(1.84) |
для безповторної вибірки |
|
|
|
. |
(1.85) |
В формулах (1.84) та (1.85) величини |
і |
підставляються в |
процентах.
Визначення обсягу вибірки проводять в такій послідовності.
1.Виконують декілька попередніх (пробних) вимірювань у кількості від 30 до 50 в залежності від трудомісткості досліду.
2.Обчислюють вибіркове стандартне відхилення  .
.
3.У відповідності до поставлених задач дослідження встановлюють необхідну точність спостережень (вимірів)  або
або  . При інструмента-
. При інструмента-
льних дослідженнях ці величини повинні бути меншими за точність приладу, яким виконуються спостереження.
4.Задають довірчу імовірність  і нормоване відхилення
і нормоване відхилення 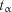 .
.
5.За формулами (1.82, 1.83) або (1.84, 1.85) визначають кількість спостережень. У подальшому ця кількість спостережень приймається
за мінімальну необхідну.
Приклад 24. Досліджується процес формування транспортних партій вантажів для централізованої доставки їх із центрального матеріального складу підприємства у виробничі цехи. Необхідно визначити мінімальну необхідну кількість спостережень (транспортних партій) для обчислення середнього обсягу поставок з регламентованою точністю  і
і  і надійністю
і надійністю  .
.

90 |
Розділ 1 |
Розв’язок. Для розв’язання задачі скористаємося даними прикладу 1, вважаючи їх за попередньо проведені спостереження для визначення  і
і  . Маємо:
. Маємо:
 ;
;  ;
; 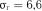 ;
;  .
.
Приймаємо, що абсолютна точність розрахунків повинна складати  т. Для заданої надійності
т. Для заданої надійності  із табл. 1.29 знаходимо
із табл. 1.29 знаходимо  .
.
За умовою задачі маємо повторну вибірку. Обчислюємо необхідну кількість спостережень за формулою (1.82)
 .
.
Робимо висновок, що попередньо прийнятий обсяг вибірки не може забезпечити прийнятої точності.
За формулою (1.78) визначаємо абсолютну точність розрахунків середнього обсягу поставки вантажів, що забезпечується даним обсягом вибірки
 т.
т.
Далі за формулою (1.84) визначаємо мінімальну необхідну кількість спостережень для розрахунку середнього обсягу поставок з точністю  :
:
 .
.
Приклад 25. Статистичні дані прикладу 1 характеризують динаміку величини складського запасу матеріалів за  доби. З надійністю
доби. З надійністю  за заданою регламентованою точністю
за заданою регламентованою точністю  і
і  визначити мінімально необхідну кількість спостережень для обчислення середньої величини запасу.
визначити мінімально необхідну кількість спостережень для обчислення середньої величини запасу.
Розв’язок. У даному випадку маємо безповторну вибірку. Для прийнятої абсолютної точності 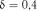 за формулою (1.83) обчислюємо обсяг вибірки
за формулою (1.83) обчислюємо обсяг вибірки
 .
.
Для відносної точності  за формулою (1.85) маємо
за формулою (1.85) маємо
.
Отже, для даних умов кількість спостережень  забезпечує з надійністю
забезпечує з надійністю 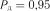 прийняті абсолютну
прийняті абсолютну  відносну
відносну  точність розрахунків.
точність розрахунків.