

big_doc_LKG
.pdfВступ |
11 |
що студенти мають базові знання з курсів вищої математики і теорії ймовірностей і математичної статистики.
Орієнтація на системний підхід визначила таку послідовність викладення матеріалу.
Упершому розділі розглядається порядок і основні прийоми опрацювання первинної статистичної інформації .
Удругому розділі викладені способи опису вхідних параметрів системи теоретичними і емпіричними статистичними законами розподілу.
Третій розділ присвячений дослідженню випадкових процесів, що відбуваються у транспортних системах.
Учетвертому розділі описані методи відбору суттєвих факторів що впливають на процеси функціонування систем.
П’ятий, шостий і сьомий розділи присвячені вивченню кореляційних і регресійних зв’язків між явищами в умовах пасивного експерименту.
Увосьмому розділі розглядаються задачі встановлення зв’язків між явищами в умовах активного експерименту.
Наприкінці кожного розділу наведений список питань для самостійного контролю.
Попереднє опрацювання матеріалу навчального посібника необхідне для вивчення низки дисциплін навчального плану підготовки фахівців за напрямком 6.070101 «Транспортні технології»:
основи теорії транспортних процесів і систем;
вантажні перевезення;
пасажирські перевезення;
взаємодія видів транспорту;
складські системи та комплекси;
організація і технологія вантажних робіт на транспорті;
методи і моделі організації дорожнього руху;
управління роботою транспорту.
Окремі розділи будуть корисними при виконанні дипломних проектів спеціалістами та випускних кваліфікаційних робіт магістрами, а також у науково-дослідній роботі студентів.
Автори сподіваються, що така структура подання матеріалу дасть змогу добре зорієнтувати фахівця-практика або дослідника у системному підході до аналізу і оцінки ефективності функціонування транспортних систем.
РОЗДІЛ 1
ФОРМУВАННЯ ВИХІДНОЇ ІНФОРМАЦІЇ ДЛЯ СТАТИСТИЧНОГО АНАЛІЗУ ТА ДОСЛІДЖЕННЯ СИСТЕМ
Мета вивчення теми – оволодіння методикою збирання і систематизації інформації в реальних умовах функціонування об’єкта.
Після вивчення теми ви повинні вміти:
–виділяти об’єкт із зовнішнього середовища;
–обґрунтовувати вхідні дії і вихідні характеристики досліджуваного процесу або явища;
–обґрунтовувати джерела і способи збирання інформації;
–проводити попереднє опрацювання статистичних даних.
1.1. Організація статистичного дослідження
Першим етапом дослідження є збирання даних, яке називається статистичним дослідженням. Довільне статистичне дослідження базується на певній множині емпіричних даних, для отримання яких використовують власні спостереження явищ, виробничу звітність, офіційну статистику, опитування задіяного у виробництві персоналу тощо. В результаті отримують статистичну суку-
пність, яка являє собою множину елементів або одиниць одного і того ж виду.
Для транспортних систем це можуть бути сукупності відправників і споживачів вантажу; сукупності видів вантажу; сукупності видів вантажопереробки; сукупності показників і характеристик транспортного процесу тощо.
Кожний елемент сукупності характеризується низкою властивостей або ознак, котрі змінюються під впливом різних причин або умов,
утворюючи їх мінливість, коливність, варіацію.
Вихідна, або статистична інформація спочатку являє собою неупорядкований ряд результатів окремих спостережень. Якщо ці спостереження розташувати у порядку зростання або спадання значень ознаки, то отримаємо ранжований, або упорядкований ряд.
Формування вихідної інформації для аналізу і дослідження систем |
13 |
На підставі ранжованого ряду визначають, скільки разів кожний варіант ознаки зустрічається у даній статистичній сукупності. У цьому випадку отримується ряд розподілу, або варіаційний ряд. Окремі значення ознаки прийнято називати варіантами ряду розподілу. Елементи статистичної сукупності групуються за варіантами ознаки, при цьому для кожної групи визначається кількість елементів або частота повторення ознаки.
Отже, ряд розподілу являє собою таблицю, в якій записані у певному порядку варіанти тієї чи іншої ознаки і вказані частоти їх повтору.
Розпізнають дискретні і неперервні варіації ознаки. Дискретною називають таку варіацію, у якої окремі значення досліджуваної ознаки відрізняються одна від одної на деяку скінченну величину або ціле число (наприклад, кількість транспортних партій; кількість транспортних засобів, що надходить на вантажний пункт; кількість відправників вантажу; кількість пунктів завозу вантажів на кільцевому маршруті тощо).
Неперервною варіацією ознаки називають таку, у якої окремі значення ознаки відрізняються одна від одної на як завгодно малу величину (наприклад швидкість руху автомобілів; обсяг перевезень; складський запас вантажів; тривалість вантажних операцій; продуктивність транспортних засобів тощо). Якщо ряд розподілу формується на основі неперервної ознаки, то розподіл ознаки задається у вигляді інтервалів. У цьому випадку частоти підраховують не по відношенню до окремого значення ознаки, а по відношенню до прийнятого інтер-
валу. Такі ряди називаються інтервальними варіаційними рядами.
Інтервальні ряди розподілу можуть бути з однаковими (всі інтервали мають однакову величину) і неоднаковими (інтервали мають різну величину) інтервалами.
Для характеристики варіації ознаки використовують не тільки абсолютні значення частот, але і відносні частоти, які визначаються
відношенням абсолютної частоти до обсягу статистичної сукуп-
ності. Такі величини називають частістю.
Розрізняють два види статистичних спостережень: суцільне і несуцільне. Суцільним називають таке спостереження, при якому обстежується вся статистична сукупність. Така сукупність називається генеральною. Практично суцільні спостереження не можна отримати. Однак, якщо ступінь охоплення спостереження дуже велика, то спо-
14 |
Розділ 1 |
стереження можна вважати суцільним. Несуцільним називається таке спостереження, при якому обстежується певна частина одиниці сукупності. Результатом такого спостереження є вибіркова сукупність. Із несуцільних спостережень найбільш поширеним є вибірковий метод спостереження, сутність якого полягає у випадковому відборі деякої кількості одиниць статистичної сукупності, виходячи із строго об’єктивного підходу до їх вибору. Вибірковий метод спостереження дає можливість отримати випадкову вибірку, на основі якої можна встановити характеристики генеральної сукупності.
При використанні вибіркового методу спостереження здійснюють відбір одиниць із генеральної сукупності. Систему організації відбору одиниць називають способом відбору. Розрізняють два види відбору:
повторний і безповторний.
Повторним називається такий вид відбору, при якому відібрана в перший раз одиниця повертається знову в генеральну сукупність і знову бере участь у виборці. Тут спостерігається постійна імовірність попадання у вибірку всіх одиниць сукупності.
Безповторним називається такий вид відбору, при якому відібрана в перший раз одиниця в генеральну сукупність знову не повертається. У цьому випадку спостерігається змінна ймовірність попадання у вибірку кожної нової одиниці.
При використанні статистичних досліджень розрізняють п’ять способів відбору:
1)випадковий, орієнтований на вибірку одиниць із генеральної сукупності без якого-небудь розчленування її на частини або групи і здійснюється на вдачу. Випадковий відбір здійснюється за допомогою
жеребкування або на основі таблиці випадкових чисел і дозволяє отримувати об’єктивну оцінку генеральної сукупності. Цей спосіб дає
власне випадкову вибірку;
2)при механічному відборі генеральна сукупність поділяється на
кількість груп, яка відповідає обсягу вибірки і з кожної групи в
вибірку відбирається одна одиниця. Відбір виконується у якомунебудь механічному порядку. Наприклад, у вибірку попадає кожна п’ята, кожна десята і т.д. одиниці, виходячи із певного місця в генеральній сукупності;
3)при типовому відборі генеральна сукупність розділяється за де-
якою ознакою на типові групи і із кожної групи здійснюється випадковий відбір одиниць;
Формування вихідної інформації для аналізу і дослідження систем |
15 |
4)при серійному відборі здійснюється вибірка не одиниць сукупності, а деяких груп або серій. Усередині відібраних серій виконують су-
цільне спостереження.
5)при комбінованому відборі передбачається використовувати одночасно декілька способів, наприклад серійний і випадковий. У цьому випадку спочатку генеральна сукупність розбивається на серії, а потім за відібраними серіями здійснюється випадковий відбір одиниць.
При вибірковому методі спостережень необхідно враховувати неточності спостережень, які називаються похибками спостережень. Останні включають похибки реєстрації і похибки репрезентатив-
ності.
Похибки реєстрації виникають внаслідок неправильних і неточних відомостей. Їх поява пов’язана з недостатнім розумінням сутності питання, похибок реєстраторів, пропускання або повторного рахунку деяких одиниць сукупності. Ці похибки призводять до спотворювання статистичної інформації, наприклад округлювання цифр, пропуски одиниць спостереження, а також похибки суб’єктивних вражень.
Похибки репрезентативності характеризують різницю між розмірами ознак, що вивчаються, в генеральній і вибірковій сукупностях Ці похибки притаманні тільки несуцільному спостереженню і вклю-
чають систематичні і випадкові похибки. Систематичні похибки
виникають через неправильний, тенденційний відбір одиниць спосте-
реження. Випадкові похибки обумовлені ступенем однорідності статистичної сукупності.
В залежності від кількості спостережень розрізняють великі (понад 30 спостережень) і малі (менше 30 спостережень) вибірки.
Сформована первинна статистична інформація спочатку підлягає попередньому опрацюванню і аналізу, який передбачає виявлення масштабів експериментів і спостережень, а також оцінювання якості отриманої вибірки з метою зменшення розсіювання випадкової величини. Обов’язковою умовою цього етапу є представлення первинної статистичної інформації у вигляді ранжованого ряду за зростанням значення досліджуваної ознаки або у вигляді інтервалів, кратних якому-небудь розміру.
При первинному опрацюванні і аналізі статистичних даних вирішують такі основні задачі:
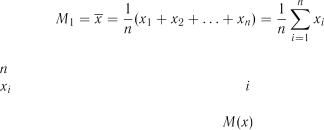
16 |
Розділ 1 |
1)визначення основних статистичних характеристик вибірки;
2)перевірка нормальності розподілу вибірки;
3)виключення аномальних значень випадкової величини;
4)перевірка статистичної однорідності вибірок;
5)визначення достатності обсягу вибірки.
1.2. Оцінювання вибіркових характеристик статистичної сукупності
1.2.1. Кількісні оцінки характеристик розподілу. Оцінка якості досліджуваної вибірки базується на її статистичних характеристиках. Числові характеристики, які визначаються згідно з вибіркою, є приблизними оцінками відповідних характеристик генеральної сукупності.
При розв’язуванні багатьох практичних задач достатньо знати тільки числові значення параметрів, які характеризують істотні відмінності того чи іншого статистичного розподілу випадкової величини.
Так як вихідна інформація є деякою випадковою вибіркою, то і шукані числові значення параметрів будуть випадковими оцінками вихідних характеристик. Ці оцінки повинні бути конзистентними (слуш-
ними, умотивованими), незміщеними і ефективними.
Серед основних оцінок виділяють чотири центральні моменти.
1. Центральний момент першого порядку використовується для числового вимірювання місця знаходження випадкової величини на числовій осі і являє собою оцінку середнього вибіркового значення випадкової величини
, |
(1.1) |
де – |
кількість спостережень; |
– |
значення випадкової величини у -му спостереженні. |
Середнє вибіркове  є слушною незміщеною оцінкою математи-
є слушною незміщеною оцінкою математи-
чного очікування середнього значення |
випадкової величини у |
генеральній сукупності. |
|

Формування вихідної інформації для аналізу і дослідження систем |
17 |
2. Центральний момент другого порядку характеризує міру розсі-
яння випадкової величини відносно її середнього значення і являє собою оцінку дисперсії випадкової величини
|
. |
(1.2) |
|
Ця оцінка є слушною, але зміщеною і при малих значеннях |
мо- |
же |
бути доволі великою. На практиці у випадку малих вибірок |
|
( |
) використовують оцінку дисперсії у вигляді |
|
|
|
. (1.3) |
|
Ця оцінка є незміщеною і дозволяє виключити систематичні по- |
|
хибки статистичних характеристик за даними вибіркових спостережень.
3. Центральний момент третього порядку використовується для вимірювання асиметрії розподілу і визначається за формулами:
– для зміщених оцінок (при ) |
|
|
|
; |
(1.4) |
– для незміщених оцінок (при |
) |
|
|
. |
(1.5) |
4. Центральний момент четвертого порядку характеризує ексцес
розподілу і визначається за формулами:
– для зміщених оцінок
; |
(1.6) |

18 |
Розділ 1 |
– для незміщених оцінок
(1.7)
Для оцінки розсіяння можливих значень випадкової величини відносно її середнього значення крім дисперсії використовують і деякі інші характеристики.
Середньоквадратичне (стандартне) відхилення являє собою дода-
тний корінь квадратний із дисперсії та обчислюється за формулами:
– для зміщених точкових оцінок
; (1.8)
– для незміщених оцінок
. (1.9)
Цю характеристику використовують у випадках, коли бажано, щоб оцінка розсіяння мала розмірність випадкової величини.
Коефіцієнт варіації використовується як відносна оцінка характеристики розсіювання випадкової величини і являє собою процентне відношення вибіркового стандартного відхилення до вибіркового середнього:
– для зміщеної оцінки
; |
(1.10) |
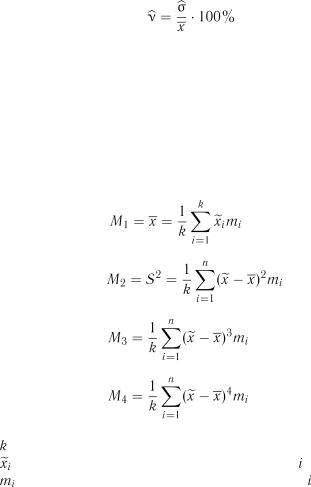
Формування вихідної інформації для аналізу і дослідження систем |
19 |
|
– для незміщеної оцінки |
|
|
. |
(1.11) |
|
За допомогою коефіцієнта варіації порівнюють величину розсіяння по відношенню до вибіркового середнього двох варіаційних рядів: ряд з більшим коефіцієнтом варіації має більше розсіяння відносно вибіркового середнього.
Так як коефіцієнт варіації безрозмірна величина, то він придатний для порівняння розсіювань варіаційних рядів з різними розмінностями.
Для вибірок великого обсягу ( ) оцінка статистичних харак-
) оцінка статистичних харак-
теристик може бути виконана за групованими даними: |
|
; |
(1.12) |
; |
(1.13) |
, |
(1.14) |
, |
(1.15) |
де – кількість груп; |
|
– середнє значення випадкової величини в |
-й групі; |
– абсолютна частота випадкової величини в |
-й групі. |
1.2.2. Розрахунок статистичних характеристик ручним способом.
При невеликій кількості спостережень обчислення значень характеристик дискретних і неперервних випадкових величин виконуються безпосередньо за відповідними формулами. Для великих вибірок (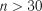 ) неперервних випадкових величин обчислення доцільно виконувати за групованими даними в табличній формі у такій послідовності.
) неперервних випадкових величин обчислення доцільно виконувати за групованими даними в табличній формі у такій послідовності.

20 |
Розділ 1 |
1. Весь діапазон значень випадкової величини  розбивають на
розбивають на 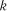 інтервалів. Кількість інтервалів може бути прийнятою апріорі: при кількості спостережень
інтервалів. Кількість інтервалів може бути прийнятою апріорі: при кількості спостережень 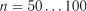 мінімальна кількість інтервалів дорівнює
мінімальна кількість інтервалів дорівнює 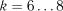 ; при
; при 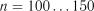 –
–  . Мінімальну кількість інтервалів групування можна визначити за формулою Стреджеса
. Мінімальну кількість інтервалів групування можна визначити за формулою Стреджеса
|
|
. |
(1.16) |
2. Розраховують інтервал групування вибірки за формулою |
|
||
|
|
, |
(1.17) |
де |
, |
– максимальне і мінімальне значення випадкової |
|
|
|
величини із спостережень. |
|
Бажано приймати всі інтервали однаковими за шириною та ціли-
ми за величиною.
3. Визначають середнє інтервальне значення випадкової величини у
кожному інтервалі |
|
, |
(1.18) |
де  ,
, 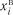 – відповідно нижня і верхня межі випадкової величини в
– відповідно нижня і верхня межі випадкової величини в  -му інтервалі.
-му інтервалі.
4.Підраховують абсолютну частоту  попадання випадкової величини до
попадання випадкової величини до  -го інтервалу і обчислюють її відносну частоту (частість) у кожному інтервалі
-го інтервалу і обчислюють її відносну частоту (частість) у кожному інтервалі 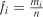 .
.
5.Обчислюють окремі складові вибіркових характеристик і числові значення самих характеристик.
Порядок розрахунку статистичних характеристик вибірки неперервної випадкової величини покажемо на прикладі.
Приклад 1. У табл. 1.1 наведені статистичні дані про обсяги поставок металопрокату з розподільчого складу споживачам на протязі двох місяців. Необхідно розрахувати основні статистичні характеристики даної випадкової величини.