

Глава шестая. Проектирование функциональных модулей интегрирующих вычислительных структур
Как следует из математической модели ИВС [32, 36], основными его составляющими являются универсальные решающие блоки, методику проектирования которых мы рассматривали в предыдущем разделе, и коммуникационная система.
Рассмотрим принцип организации коммутационных систем для синтеза УРБ и ФМ.
6.1. Исследование принципов построения коммутационных систем модульных интегрирующих вычислительных структур
Для построения модульных ИBC разработана система коммутации иерархического типа, на каждом уровне которой производится организация архитектурных единиц ИВС и вычислительных процессов как внутри архитектурных единиц, так и между ними. Иерархические уровни и архитектурные единицы ИВС – это понятия взаимосвязанные. С одной стороны, на каждом иерархическом уровне определяющим является выбранная архитектурная единица. С другой стороны, выбранная архитектурная единица на каждом уровне определяет систему связи между единицами – систему коммутации, обеспечивающую дальнейшее усложнение (рост) архитектурной единицы для перехода на следующий иерархический уровень и организующую вычислительные процессы.
Основными архитектурными единицами ИВС являются: операционные устройства (ОУ), универсальный цифровой интегратор (УЦИ), универсальный решающий блок (УРБ), цифровой решающий модуль (ЦРМ), функциональный модуль (ФМ), макроблок ИВС (МкБ), интегрирующая, вычислительная структура модульного типа (МИВС) [3, 14, 18, 19, 33, 36, 77, 97].
Используя понятие
графа коммутации
![]() и
вводя обозначенияNi
- количество
архитектурных единиц на i-м
уровне иерархии МИВС, Hi
- отображение
для графа коммутации на i-м
иерархическом уровне МИВС и
и
вводя обозначенияNi
- количество
архитектурных единиц на i-м
уровне иерархии МИВС, Hi
- отображение
для графа коммутации на i-м
иерархическом уровне МИВС и![]() - операции коммутации, можно представить
следующие уровни иерархии ИВС:
- операции коммутации, можно представить
следующие уровни иерархии ИВС:

Схематически описанную процедуру можно представить так, как это показано на рис. 6.1. Система коммутации, как видно из рисунка, должна быть построена так, чтобы можно было переходить как от низших уровней иерархии к высшим, так и наоборот. Это позволяет организовать вычислительный процесс в ИВС при отображении задач так, чтобы можно было использовать различной сложности вычислительные блоки от универсального цифрового интегратора до макроблока ИВС. При построении ИВС модульного типа принято, что функциональный модуль – основная архитектурная единица, а УЦИ, УРБ, ЦРМ – вырожденные функциональные модули различной степени сложности.
Между
макроблоками ИВС также имеется
двухсторонняя коммутация
![]() .
Наряду с этим, в зависимости от того,
какие структурные единицы организованы
коммутацией при решении конкретных
задач, в макроблоки могут объединяться
любые вычислительные блоки от УЦИ до
ФМ. При этом не обязательно, чтобы в
макроблоки объединялись однотипные
вычислительные блоки.
.
Наряду с этим, в зависимости от того,
какие структурные единицы организованы
коммутацией при решении конкретных
задач, в макроблоки могут объединяться
любые вычислительные блоки от УЦИ до
ФМ. При этом не обязательно, чтобы в
макроблоки объединялись однотипные
вычислительные блоки.
Такой подход к построению коммутационной системы (КС) позволяет представлять ИВС однородной на различных уровнях от операционных блоков до макроблоков, которые в исходном состоянии не связаны между собой. Под воздействием настроечной информации, вырабатываемой управляющим автоматом (базовой машиной), архитектурные единицы организовываются в вычислительные блоки различной степени сложности от универсального

Рис. 6.1. Иерархические
уровни МИВС
цифрового интегратора до функционального модуля или даже макроблока с помощью коммутационной системы, которая также обеспечивает связи между вычислительными блоками для реализации вычислительного процесса. С этих позиций разрабатываемые модульные интегрирующие вычислительные структуры относятся к однородным автоматам с перестраиваемой структурой [70, 77, 101, 102].
Вопросам разработки и построения различных типов коммутационных систем посвящено большое число работ [3, 19, 77, 97 и др.]. К настоящему времени установилось два подхода к решению вопроса об обмене информацией между вычислительными блоками параллельных интегрирующих вычислительных структурах [33]: параллельно-параллельный и параллельно-последовательный. Разница между способами, реализующими данные подходы, заключается в том, что в первом из них обмен приращениями между всеми решающими блоками ИВС осуществляется в момент времени между последним тактом предыдущего шага вычислений и первым тактом последующего шага через полнодоступную коммутирующую среду, обладающую свойством безынерционности. Временная диаграмма обмена информацией по данному способу представлена на рис. 6.2.
Во втором способе после выполнения каждого шага вычисления ИВС останавливается на время обмена информацией между вычислительными блоками. Причем обмен осуществляется последовательно, поэтому время решения задачи увеличивается на время обмена информацией. В работе [33] для целей упрощения коммутирующей среды и устранения эффекта гонок передаваемых через нее сигналов, предложено осуществлять передачу информации с выходов вычислительных блоков с задержкой на один шаг вычисления (рис. 6.3).
Данный способ предполагает наличие на входах вычислительных блоков элементов памяти, хранящих значения полученных приращений в течение времени до начала обработки следующего шага вычислений.
Рис. 6.3. Диаграмма
динамического (задержанного на )
способа обмена
Рис. 6.2. Диаграмма
параллельно-параллельного способа
обмена
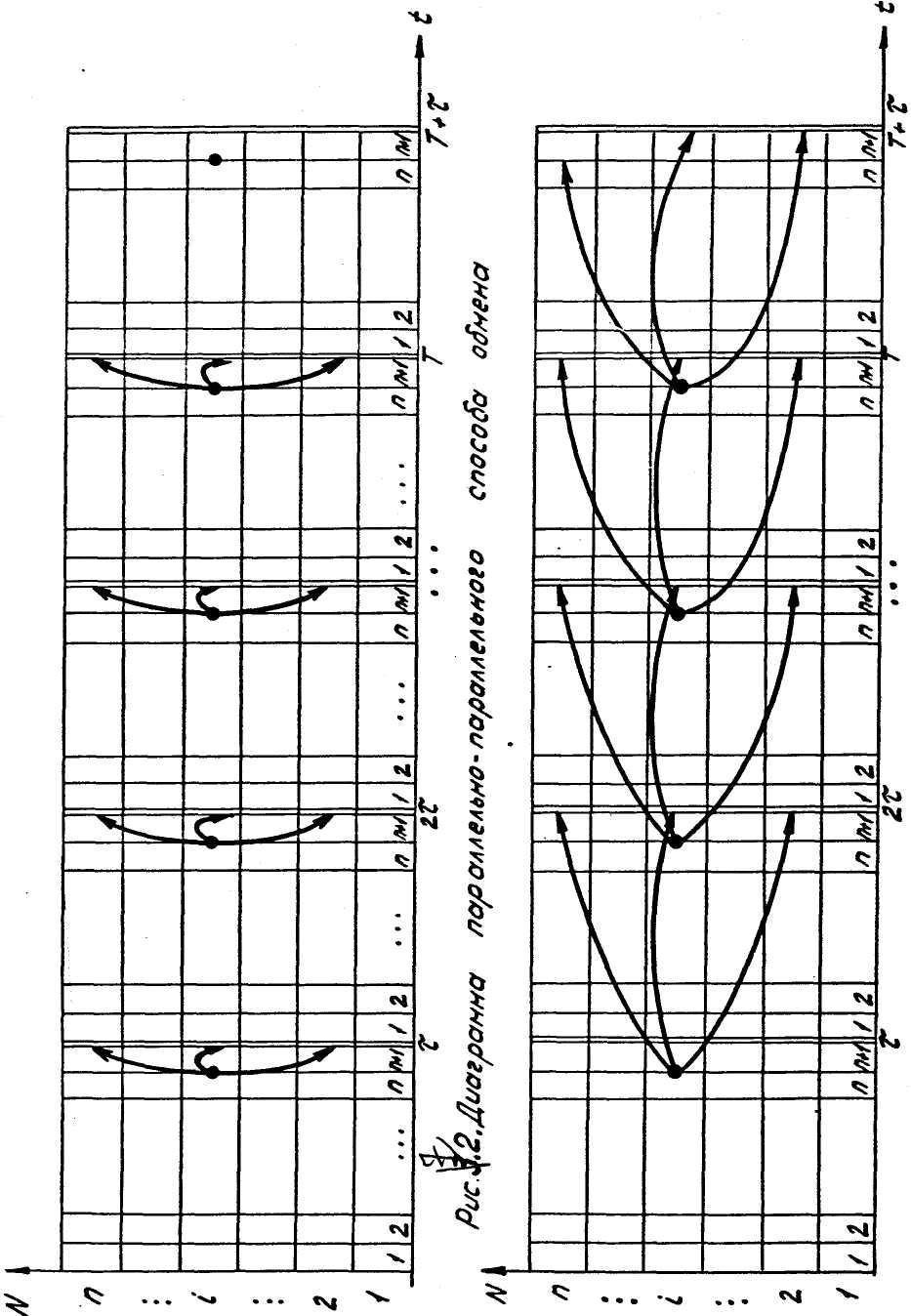

Во время хранения информации на входах вычислительные блоки обрабатывают приращения, полученные в предыдущем шаге.
Проведено
подробное исследование влияния внесенной
задержки вычислений на одну итерацию
на точность получаемых результатов
[33].
Исследования показали, что если
–
длительность одного шага интегрирования
в ИВС, т.е. =x,
то при численном интегрировании для
получения неискаженных результатов
необходимо экстраполировать приращения
![]() на
два шага вперед в структурах
экстраполяционного типа и на один шаг
вперед в структурах интерполяционного
типа.
на
два шага вперед в структурах
экстраполяционного типа и на один шаг
вперед в структурах интерполяционного
типа.
Представляет
интерес рассмотрение организации
вычислительного процесса в ИВС с
динамическим способом обмена информацией
между вычислительными блоками без
дополнительной экстраполяции приращений.
Пусть результатом решения задачи
является подынтегральная функция
![]() где
где
![]() .
Зафиксировав момент вычислений в точкеx=Т,
получим
.
Зафиксировав момент вычислений в точкеx=Т,
получим
.
Сравнивая полученные результаты, отметим, что при организации вычислений с задержкой приращений, подынтегральные функции отстают от соответствующих функций, полученных при параллельном обмене, на один шаг интегрирования. Несмотря на отставание значений подынтегральных функций, смещенный процесс обмена информацией обладает существенным преимуществом. Он позволяет использовать время смещения для обмена приращениями между решающими блоками, т.е. организовать не пространственный, а временный принцип коммутации входов и выходов решающих блоков ИВС.
Пусть
ИВС содержит N
решающих
блоков, а длительность одного шага
интегрирования составляет n
тактов.
Разделим решающие блоки на m
групп
(макроблоков),
![]() .
Организуем обмен информацией в ИВС
следующим образом. Внутри каждой группы
в
течение
i-го
такта
.
Организуем обмен информацией в ИВС
следующим образом. Внутри каждой группы
в
течение
i-го
такта
![]() выходное
приращение передает решающий блок с
номером i.
На входах УРБ предусмотрены регистры
длиной
выходное
приращение передает решающий блок с
номером i.
На входах УРБ предусмотрены регистры
длиной
![]() ,
в которые записываются номера УРБ,
приращения которых должны поступать
на входы в соответствии со схемой
решаемой задачи.
,
в которые записываются номера УРБ,
приращения которых должны поступать
на входы в соответствии со схемой
решаемой задачи.
Объединив все входные полюса УРБ одной группы в один полюс, соединим его с выходом каждого УРБ, предусмотрев развязывающие элементы, исключающие взаимное влияние выходных цепей УРБ друг на друга. На вход j УРБ с номером i будет поступать информация с общего узла только во время следования такта с номером i, что обеспечивает организацию временной коммутации УРБ внутри группы.
Для
обмена информацией между группами
введем во входные регистры УРБ
дополнительно по
![]() разрядов.
В эти разряды записываются номера групп,
которым принадлежат коммутируемые УРБ.
Данная часть регистра каждого входа
УРБ через цепи дешифрации включает
постоянно информационную шину (узел)
соответствующей группы.
разрядов.
В эти разряды записываются номера групп,
которым принадлежат коммутируемые УРБ.
Данная часть регистра каждого входа
УРБ через цепи дешифрации включает
постоянно информационную шину (узел)
соответствующей группы.
Приняв
за конструктивную единицу один разряд
регистра с управляемыми им цепями, для
построения коммутационной системы
необходимо
![]() конструктивных
единиц. При выборе N
кратным n
число
Qк.е.
будет
заключено в интервале
конструктивных
единиц. При выборе N
кратным n
число
Qк.е.
будет
заключено в интервале
![]()
![]() .
Левая часть этого выражения соответствует
случаю, когда n
и
m
являются
степенями двойки. Правая часть
характеризует общий случай.
.
Левая часть этого выражения соответствует
случаю, когда n
и
m
являются
степенями двойки. Правая часть
характеризует общий случай.
Таким образом, построив коммутационную систему по чисто временному принципу, задержанный обмен информацией между УРБ позволяет строить параллельно-параллельные ИВС. Это утверждение справедливо в том случае, когда время смещения решения мало по сравнению со временем вывода результатов. Этот принцип коммутации позволяет также осуществлять связи входов и выходов УРБ по принципу полного графа в пределах всей ИВС.
Если
параметр l2
выбрать
равным
![]() ,
где
ттах
–
максимально возможное число групп УРБ,
равное степени двойки, то ИВС будет
обладать свойством доращивания в
интервале от 1 до ттах
групп
без изменения блоков управления и ввода
- вывода информации.
,
где
ттах
–
максимально возможное число групп УРБ,
равное степени двойки, то ИВС будет
обладать свойством доращивания в
интервале от 1 до ттах
групп
без изменения блоков управления и ввода
- вывода информации.
Для оценки материальных затрат КС, построенную на основе введенной выше конструктивной единицы, будем проводить сравнение с КС, построенной на основе коммутирующих элементов (КЭ). В качестве сравниваемого варианта возьмем трехкаскадную коммутирующую среду для 1, 2, ..., 16 групп УРБ с числом УРБ в группе – 24. Количество УРБ в группе выбрано равным числу тактов в шаге интегрирования трехвходового УРБ, построенного на основе микросхем серии К502 [2].
Данные о структурных параметрах и аппаратурных затратах на построение задержанных временных коммутационных систем и самых экономичных - каскадных условно неблокируемых сред приведены в табл. 6.1. Как видно из таблицы, коммутационные временные системы, обеспечивая коммутацию по принципу полного графа, существенно более экономичны, и кроме того обладают свойством доращивания ИВС без изменения блоков управления и ввода - вывода.
Как показали исследования, задержки приращений на шаг интегрирования приводят к смещению процесса накопления подынтегральной функции. Рассмотрим вариант задержанного обмена, позволяющего или исключить, или минимизировать смещение значений подынтегральных функций.
Пусть
ИВС содержит одну групп из N
= n
УРБ,
где n
–
число тактов в шаге интегрирования.
Пронумеруем УРБ от единицы до n.
Свяжем конец шага интегрирования i-го
УРБ
![]() с
i-м
синхронизирующим
сигналом последовательностей сигналов,
обеспечивающих синхронизацию работы
ИВС. Построим временную диаграмму работы
такой структуры (рис. 6.4),
видим, что время начала и конца отработки
одного шага интегрирования в ИВС
растягивается в пределах от 1 до n
тактов.
Данный принцип синхронизации назван
плавающим.
с
i-м
синхронизирующим
сигналом последовательностей сигналов,
обеспечивающих синхронизацию работы
ИВС. Построим временную диаграмму работы
такой структуры (рис. 6.4),
видим, что время начала и конца отработки
одного шага интегрирования в ИВС
растягивается в пределах от 1 до n
тактов.
Данный принцип синхронизации назван
плавающим.
Рис. 6.4. Диаграмма
способа обмена с плавающей синхронизацией
Таблица
6.1.


Рис. 6.4. Диаграмма
способа обмена с плавающей синхронизацией

Как и в предыдущем случае, обмен между УРБ осуществляется по временному принципу и на входах УРБ необходимо предусмотреть регистры, запоминающие значения входных приращений в соответствии со схемой решаемой задачи. Будем включать входные регистры УРБ, соединенные с i-м УРБ, во время следования i-го синхронизирующего сигнала. Для определенности, выход i-го УРБ соединим с собственными входами, входами 2-го и n-го УРБ. Выбрав n < i > 2 , будем иметь следующий случай обмена информацией между УРБ: i-й и n-й УРБ смогут принимать приращения непосредственно в следующем же шаге интегрирования, входное приращение во второй УРБ поступит на шаг интегрирования позже, если предположить, что все УРБ осуществляют считывание приращений со входных регистров во время следования первого синхронизирующего сигнала.
Таким
образом, обмен с плавающей синхронизацией
позволяет i-му
УРБ
![]() обмениваться
со всеми j
i.
УРБ без задержки информации и со всеми
j
< i
с
задержкой на один шаг интегрирования.
обмениваться
со всеми j
i.
УРБ без задержки информации и со всеми
j
< i
с
задержкой на один шаг интегрирования.
Как показали исследования, способ обмена информацией между УРБ с плавающей синхронизацией полностью согласуется с временным задержанным обменом по результатам решения задач, поэтому способ обмена с плавающей синхронизацией может быть обобщен на случай многогруппового построения ИВС.
Задержанные способы обмена информацией между УРБ, обеспечивая параллельно-параллельное решение задач, позволяют строить самые экономичные коммутационные системы, аналогичные чисто временным системам.
Если ИВС построена по групповому принципу с числом УРБ в группе, равным числу тактов в одном шага интегрирования, то структура получает свойство неограниченного наращивания, обладая свойством соединения УРБ по принципу полного графа для обоих рассмотренных задержанных способов обмена.
Задержанный способ с параллельной синхронизацией работы УРБ смещает процесс накопления подынтегральных функций практически на постоянные величины.
Способ обмена с плавающей (последовательной) синхронизацией работы УРБ не смещает процесс накопления подынтегральных функций при интегрировании по Стилтьесу и приводит к медленному накоплению дополнительной погрешности при интегрировании по Риману.