

Оценка результатов тестирования
Процесс исследования статистических свойств выходной последовательности алгоритма маскирования данных состоит из следующих шагов, представленных на Рис. 4.7.

Рис. 4.7. Алгоритм технологического процесса исследования статистических свойств выходной последовательности алгоритма маскирования данных
Генерация последовательностей для тестирования
Для алгоритма маскирования данных формируется m последовательностей длины n.
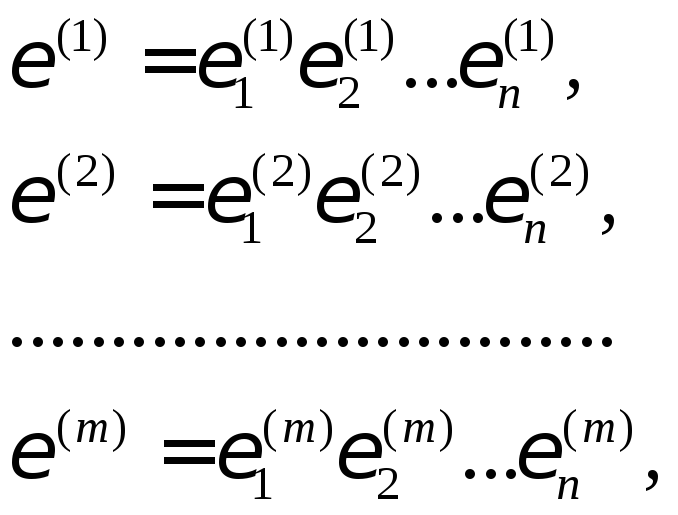
Длина последовательности n выбирается таким образом, чтобы все тесты могли быть пройдены.
Исполнение набора статистических тестов
Каждая из m –последовательностей проверяется каждым из t тестов набора. Результатом работы каждого теста является вычисление тестовой статистики s(obs). Таким образом, после проверки всех последовательностей получается mt тестовых статистик, как показано в табл. 4.4.
Табл. 4.4. Результаты выполнения набора статистических тестов
|
Последовательность |
Тест1 |
Тест2 |
……… |
Тест t |
|
|
|
|
……… |
|
|
|
|
|
……… |
|
|
……… |
……… |
……… |
……… |
……… |
|
|
|
|
……… |
|
Анализ прохождения статистических тестов
Анализ прохождения статистических тестов начинается с анализа тестовой статистики. Существует три варианта оценки тестовой статистики.
Пороговые значения. Если тестовая статистика больше (меньше) порогового значения, последовательность считается неслучайной.
Фиксированные интервалы. Если тестовая статистика выходит за пределы заданного интервала, последовательность считается неслучайной.
Вероятностные значения. Для тестовой статистики вычисляется Р –значение. Под Р –значение понимается вероятность того, что совершенный генератор случайных чисел произвел бы последовательность менее случайную, чем исследуемая, для типа неслучайности, проверяемого тестом. Для теста выбирается уровень значимости α. Если значение Р –значение больше либо равно α, то последовательность считается случайной.
Поскольку для первых двух способов необходимо заранее рассчитывать пороговые значения и фиксированные интервалы, вычисление Р –значения представляется наиболее эффективным вариантом оценки тестовой статистики.
Таким образом, вычисляются Р –значения для тестовых статистик s(obs) как показано в табл. 4.5.
Табл.4.5.Результаты вычисления Р –значения для тестовых статистик s(obs)
|
Последовательность |
Тест1 |
Тест2 |
……… |
Тест t |
|
|
|
|
……… |
|
|
|
|
|
……… |
|
|
……… |
……… |
……… |
……… |
……… |
|
|
|
|
……… |
|
Оценить прохождение последовательностями i –го теста, i =1…t можно следующим образом:
Анализ
Р –значения.
Подсчитывается
доля последовательностей, прошедших
данный тест (т. е доля последовательностей,
для которых Р
–значение
![]() α). Значение этой доли должны лежать в
интервале
α). Значение этой доли должны лежать в
интервале 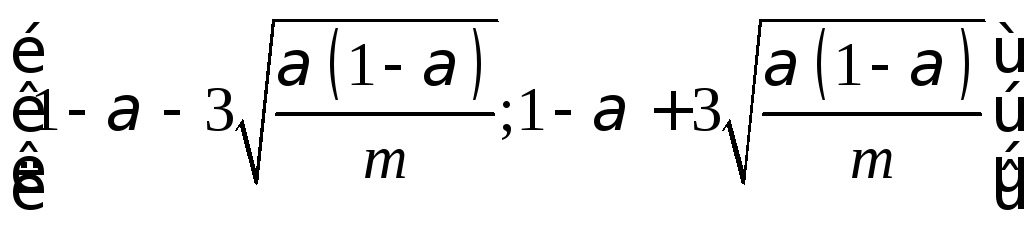 .
.
Результаты тестирования набора из m – последовательностей каждым из t тестов могут быть сведены в таблицу 4.6.
Табл. 4.6. Результаты тестирования m- последовательностей набором из t статистических тестов.
|
Последовательность |
Тест1 |
Тест2 |
……… |
Тест t |
|
|
прошла / не прошла |
прошла / не прошла |
……… |
прошла / не прошла |
|
|
прошла / не прошла |
прошла / не прошла |
……… |
прошла / не прошла |
|
……… |
……… |
……… |
……… |
……… |
|
|
прошла / не прошла |
прошла / не прошла |
……… |
прошла / не прошла |
|
Результат проверки алгоритма маскирования |
прошел / не прошел |
прошел / не прошел |
……… |
прошел / не прошел |
Не прохождение какого-либо теста свидетельствует о статистических слабостях в структуре алгоритма маскирования данных.
Таким образом, выходные последовательности алгоритма маскирования должны состоять примерно из равного числа единиц и нулей; около половины серий (последовательностей одинаковых бит) должны быть единичной длины, четверть – состоять из двух бит, восьмая часть – из трех бит, и.т.д. Последовательности должны быть несжимаемы. Маурэр показал, что все тесты на случайность можно вывести из попытки сжатия последовательности. Если случайная последовательность сжимаема, ее нельзя полагать истинно случайной. Распределение длин серий из нулей и единиц должно быть одинаковым. Последовательность должна быть непредсказуемой. Это означает, что никакими вычислительными средствами невозможно предсказать каждый последующий случайный бит, даже при абсолютном знании всех предшествующих битов потока, а также алгоритма или устройства, генерирующего данную последовательность.
Выводы
В данном разделе были рассмотрены общие принципы тестирования алгоритма маскирования данных. Даны краткие описания методик оценки качества, методов тестирования и оценки результатов тестирования алгоритма маскирования данных.