

4.5.5. Криптоанализ шифра Виженера
Рассмотрим шифр модульного гаммирования с уравнением (1), для которого гамма является периодической последовательностью знаков алфавита. Как указывалось ранее, такая гамма обычно получалась периодическим повторением некоторого ключевого слова. Например, ключевое слово KEY дает гамму KEYKEYKEY... . Рассмотрим задачу вскрытия такого шифра по тексту одной криптограммы достаточной длины.
Пусть – длина ключевого слова. Обычно криптоанализ шифра Виженера проводится в два этапа. На первом этапе определяется число , на втором этапе – само ключевое слово.
Для определения числа применяется так называемый тест Казиски, названный в честь Ф. Казиски, применившего его в 1863 г. Тест основан на простом наблюдении того, что два одинаковых отрезка открытого текста, отстоящих друг от друга на расстоянии, кратном , будут одинаково зашифрованы. В силу этого в шифртексте ищутся повторения длины, не меньшей трех, и расстояния между ними. Обратим внимание на то, что случайно такие одинаковые отрезки могут появиться в тексте с достаточно малой вероятностью.
Пусть d1,d2,... – найденные расстояния между повторениями и d – наибольший общий делитель этих чисел. Тогда должно делить d. Чем больше повторений имеет текст, тем более вероятно, что совпадает с d. Для уточнения значения можно использовать так называемый индекс совпадения, введенный в практику У. Фридманом в 1920 г.
Для строки х = (х1,...,xm) длины т, составленной из букв алфавита А, индексом совпадения в х, обозначаемым Ic(х), будем называть вероятность того, что две случайно выбранные буквы из х совпадают.
Пусть А = {a1,...,аn}. Будем отождествлять буквы алфавита с числами, так что а1 0,..., an-1 n — 2, аn n — 1.
Т еорема.
Индекс
совпадения в х вычисляется по формуле
еорема.
Индекс
совпадения в х вычисляется по формуле
(14)
где fi – число вхождений буквы аi в х, i Zn.
П![]() усть
х –
строка осмысленного текста. Допустим,
как и ранее, что буквы в х
появляются на любом месте текста с
соответствующими вероятностями р0,…,pn-1
независимо друг от друга, где рi
–
вероятность появления буквы i
в осмысленном тексте, iZn.
В такой модели открытого текста
вероятность того, что две случайно
выбранные буквы из х
совпадают с iZn,
равна рi2,
следовательно,
усть
х –
строка осмысленного текста. Допустим,
как и ранее, что буквы в х
появляются на любом месте текста с
соответствующими вероятностями р0,…,pn-1
независимо друг от друга, где рi
–
вероятность появления буквы i
в осмысленном тексте, iZn.
В такой модели открытого текста
вероятность того, что две случайно
выбранные буквы из х
совпадают с iZn,
равна рi2,
следовательно,
(17)
Взяв за основу значения вероятностей рi, приведенные в Приложении 1 для открытых текстов, получим значения индексов совпадения для ряда европейских языков:
Таблица 6. Индексы совпадения европейских языков
-
Язык
Русский
Англ.
Франц.
Нем.
Итал.
Испан.
Ic(х)
0,0529
0,0662
0,0778
0,0762
0,0738
0,0775
Предположим, что х – реализация независимых испытаний случайной величины, имеющей равномерное распределение на Zn. Тогда индекс совпадения вычисляется по формуле Ic(х)=1/n.
Вернемся к вопросу об определении числа .
Пусть y1y2,…,ym – данный шифртекст. Выпишем его с периодом :
|
Y1 |
Y2
|
…
|
Y
|
|
y1
|
y2
|
...
|
y
|
|
y+1
|
y+2
|
…
|
y2
|
|
y2+1
|
y2+2
|
…
|
y3
|
… … … …
и обозначим столбцы получившейся таблицы через Y1 ,Y2 ,…,Y.
Если – это истинная длина ключевого слова, то каждый столбец Yi , i1,…, , представляет собой участок открытого текста, зашифрованный простой заменой.
В силу сказанного выше (для английского языка) Ic(Yi)= 0,066 при любом i. С другой стороны, если отлично от длины ключевого слова, то столбцы Yi будут более "случайными", поскольку они являются результатом зашифрования фрагментов открытого текста некоторым многоалфавитным шифром. Тогда Ic(Yi) будет ближе (для английского языка) к числу 1/26=0,038.
Заметная разница значений Ic(х) для осмысленных открытых текстов и случайных последовательностей букв (для английского языка – 0,066 и 0,038, для русского языка – 0,053 и 0,030) позволяет в большинстве случаев установить точное значение .
Предположим, что на первом этапе мы нашли длину ключевого слова . Рассмотрим теперь вопрос о нахождении самого ключевого слова. Для его нахождения можно использовать так называемый взаимный индекс совпадения.
Пусть х=(х1,...,хm),у=(у1,...,yl) – две строки букв алфавита А. Взаимным индексом совпадения в х и у, обозначаемым МIc(х,у), называется вероятность того, что случайно выбранная буква из х совпадает со случайно выбранной буквой из у.
Пусть fi – число вхождений буквы аi в х, gi – число вхождений буквы аi в y, iZn.
Теорема. Взаимный индекс совпадения в х и у вычисляется по формуле
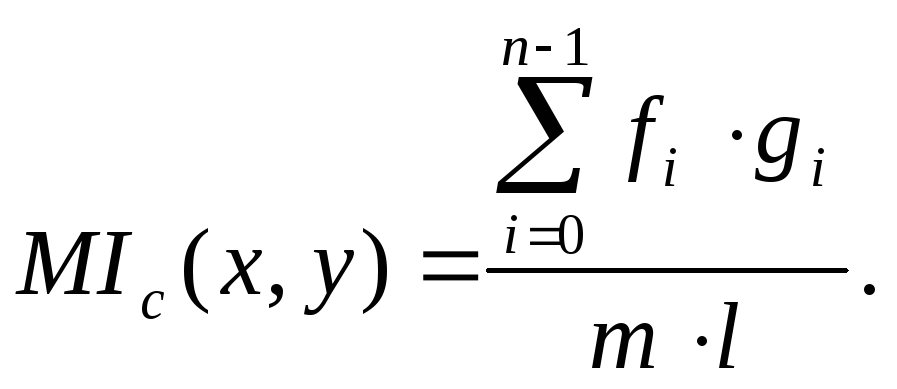
(19)
Пусть k=(k1,...,k ) – истинное ключевое слово. Попытаемся оценить индексы М1c(Yi, Yj).
Д![]() ля
этого напомним, что Ys
является результатом зашифрования
фрагмента открытого текста простой
заменой букв алфавита (подстановкой)
со сдвигом s.
На основании этого получаем:
ля
этого напомним, что Ys
является результатом зашифрования
фрагмента открытого текста простой
заменой букв алфавита (подстановкой)
со сдвигом s.
На основании этого получаем:
(20)
Заметим, что сумма в правой части последнего равенства зависит только от разности (si -sj)mod n, которую назовем относительным сдвигом Yi и Yj, поэтому Yi и Yj с относительными сдвигами s и п – s имеют одинаковые взаимные индексы совпадения. Приведем таблицу значений сумм (20) для английского языка:
Таблица 7. Взаимный индекс совпадения при сдвиге s
|
Сдвиг s
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
|
MIc(x,y)
|
0,066
|
0,039
|
0,032
|
0,034
|
0,044
|
0,033
|
0,036
|
0,039
|
0,034
|
0,034
|
0,038
|
0,045
|
0,039
|
0,043
|
Аналогичные таблицы можно получить и для других языков.
Обратим внимание на то, что ненулевые "сдвиги" дают взаимные индексы совпадения, изменяющиеся в пределах от 0,032 до 0,045, в то время как при нулевом сдвиге индекс М1с(х,у) близок к 0,066. Это наблюдение позволяет определить величины относительных сдвигов si – sj столбцов Yi и Yj .
Используя изложенный метод, мы сможем связать системой уравнений относительные сдвиги различных пар столбцов Yi и Yj .В результате останется 26 вариантов для ключевого слова, из которых можно выбрать наиболее предпочтительный вариант (если ключевое слово является осмысленным).
Следует отметить, что предложенный метод будет эффективным для не слишком больших значений . Это объясняется тем, что для хороших приближений индексов совпадения требуются тексты достаточно большой длины.
Контрольные вопросы
-
Приведите пример шифра перестановки, который может рассматриваться и как блочный шифр замены.
-
Как определить по криптограмме, полученной с помощью шифра вертикальной перестановки, число коротких столбцов заполненного открытым текстом основного прямоугольника?
-
Какие свойства открытого текста используются при вскрытии шифра вертикальной перестановки?
-
Каким образом можно использовать вероятные слова для вскрытия ряда криптограмм, полученных на одном ключе шифра перестановки?
-
С какими примерами шифров замены и перестановки Вы познакомились в историческом обзоре?
-
Существуют ли шифры, не являющиеся ни шифрами замены, ни шифрами перестановки?
-
Приведите пример шифра многозначной замены.
-
Может ли блочный шифр быть шифром разнозначной замены?
-
Может ли шифр простой замены быть равнозначным, разнозначным, блочным шифром?
-
В каком случае шифр гаммирования является одноалфавитным шифром?
-
Каково максимальное число простых замен, из которых может состоять многоалфавитный шифр?
-
Можно ли рассматривать множество возможных открытых и шифрованных текстов как множество шифровеличин и шифрообозначений шифра замены?
-
Какие шифры называются шифрами простой замены?
-
Что является ключом шифра простой замены? Каково максимально возможное число ключей шифра простой замены?
-
Что более целесообразно для надежной защиты информации:
архивация открытого текста с последующим шифрованием или шифрование открытого текста с последующей архивацией?
-
Имеет ли шифр Плейфера эквивалентные ключи, то есть такие ключи, на которых любые открытые тексты шифруются одинаково? Сколько различных неэквивалентных ключей имеет шифр Плейфера?
-
Предположим, что матричный шифр Хилла используется для зашифрования открытого текста, представленного в виде двоичной последовательности. Сколько ключей имеет такой шифр?
-
В чем слабость шифра гаммирования с неравновероятной гаммой?
-
Является ли надежным шифрование литературного текста с помощью модульного гаммирования, использующего гамму, два знака которой имеют суммарную вероятность, совпадающую с суммарной вероятностью остальных знаков? Почему?
-
Почему наложение на открытый текст гаммы, представляющей собой периодическую последовательность небольшого периода, не дает надежной защиты?
-
Почему недопустимо использовать дважды одну и ту же гамму (даже случайную и равновероятную!) для зашифрования разных открытых текстов?
-
Почему в качестве гаммы нецелесообразно использовать текст художественного произведения? Можете ли Вы предложить метод вскрытия такого шифра?
-
Можно ли по шифртексту получить приближения для вероятностей знаков гаммы?
-
Назовите основные этапы работы по вскрытию шифра Виженера.
-
Каким образом рассчитывается индекс совпадения для реального языка?
-
Из каких простых замен «состоит» шифр гаммирования (как многоалфавитный шифр)?