

Лабораторная работа № 12 Частотный анализ при обработке исторических фактов и географических названий.
Задание 1. Обработка исторических фактов с использованием аппарата математической статистики.
В исторических исследованиях часто возникают задачи анализа какого нибудь признака, свойственного большой группе объектов.
Например, в таблице 3.1 приведен данные по наделам земли в десятинах на душу населения для различных губерний Царской России.
Таблица 3.1
-
N
Губерния
Посев
на душу
(дес.)
N
Губерния
Посев
на душу
(дес.)
1
Архангельская
0,19
26
Новгородская
0,48
2
Астраханская
0,38
27
Олонецкая
0,37
3
Бессарабская
0,99
28
Оренбургская
0,94
4
Виленская
0,67
29
Орловская
0,81
5
Витебская
0,6
30
Пензенская
0,94
6
Владимирская
0,57
31
Пермская
0,64
7
Вологодская
0,45
32
Петербургская
0,42
8
Волынская
0,57
33
Подольская
0,66
9
Воронежская
0,89
34
Полтавская
0,73
10
Вятская
0,99
35
Псковская
0,54
11
Гродненская
0,59
36
Рязанская
0,75
12
Донская
1,55
37
Самарская
1,14
13
Екатеринославская
1,26
38
Саратовская
1,06
14
Казанская
0,86
39
Симбирская
0,91
15
Калужская
0,5
40
Смоленская
0,58
16
Киевская
0,52
41
Таврическая
1,95
17
Ковенская
0,61
42
Тамбовская
0,88
18
Костромская
0,64
43
Тверская
0,5
19
Курляндская
0,76
44
Тульская
0,9
20
Курская
0,87
45
Уфимская
0,71
21
Лифляндская
0,66
46
Харьковская
0,9
22
Минская
0,6
47
Херсонская
1,62
23
Могилевская
0,56
48
Черниговская
0,69
24
Московская
0,35
49
Эстляндская
0,56
25
Нижегородская
0,65
50
Ярославская
0,52
В этой таблице через N обозначен порядковый номер губерний, которые расположены в алфавитном порядке. Далее через x будем обозначать величину посевного надела земли в десятинах. Эту величину х можно принять в качестве статистического признака, характеризующего конкретную губернию, а величина этого признака может объяснять те или иные социально-исторические процессы, имевшие место в губерниях. Методы математической статистики позволяют сгруппировать губернии по величине указанного признака.
Для этого, прежде всего, необходимо расположить губернии в строках табл.1 в порядке возрастания величины х. Эта операция называется ранжированием по данному признаку. Теперь необходимо весь диапазон изменения величины х поделить на равные интервалы, середины которых будем обозначать через хi, и определим число губерний ni, попадающих в каждый интервал хi. Далее определим частоту fi следующим образом
fi= ni/n , (3.1)
где n называют объемом выборки.
Изменение величины fi в зависимости от хi называют рядом распределения статистической величины, а график функции fi(хi) называют гистограммой. Функция fi(хi) обладает некоторыми статистическими характеристиками, которые также проливают свет на некоторые социально-исторические явления.
Цель работы состоит в том, чтобы в пакете Excel 7 построить гистограмму fi(хi) и вычислить ее статистические характеристики.
Это выполняется в среде Excel следующим образом.
Сначала осуществим запуск Excel.
Для этого необходимо:
-
Щелкнуть на кнопке ПУСК на панели задач Windows и выбрать меню ПРОГРАММЫ.
-
В открывшемся меню активизировать пункт Microsoft Excel.
-
Во время запуска программы на экране появляется заставка Excel, и через несколько секунд система готова к работе.
Теперь данные таблицы 1 внесем в ячейки таблицы Excel. Данные 1-го столбца внесем в ячейки столбца A.
В первой ячейке этого столбца поместим номер варианта N. С этой целью выделим ячейку А1. Для этого необходимо щелкнуть на ней левой клавишей мыши, т. е. поместить в эту ячейку курсор мыши (он имеет вид крестика), нажать и отпустить левую клавишу мыши. Ячейка становится активной и выделяется жирной рамкой. Теперь введем в эту ячейку с клавиатуры букву N.
Затем в ячейку А2 введем начальный номер 1 Заполним теперь столбец А, используя формулу арифметической прогрессии.
С этой целью сначала выделим те ячейки столбца А, которые будут заполнены (ячейки A2:A51). Для этого необходимо подвести курсор мыши к ячейке А2, нажать левую клавишу и, не отпуская ее, протащить курсор от ячейки А2 до ячейки А51, а затем отпустить. Ячейки А2:А51 становятся активными и выделяются жирной рамкой.
Затем выполним команду ПРАВКА- ЗАПОЛНИТЬ- ПРОГРЕССИЯ.
В открывшемся диалоговом окне ПРОГРЕССИЯ выбрать подходящие опции (РАСПОЛОЖЕНИЕ- ПО СТОЛБЦАМ; ТИП- АРИФМЕТИЧЕСКАЯ; ШАГ- 1) и щелкнуть по клавише ОК. В результате ячейки А2:A51 будут заполнены рядом значений от 1 до 50.(фиг.3.1).
Ячейки столбцов B и C заполняются подобно ячейке А1.
Замечание 1. При заполнении ячеек числами следует помнить, что целая часть числа от дробной отделяется не точкой, а запятой.
Замечание 2. Перенос на другую строку в ячейке осуществляется с помощью нажатия клавиш Alt + Enter.
При заполнении ячеек можно отрегулировать размеры столбцов. Для этого курсор мыши необходимо поместить в строку заголовков столбцов на границу между столбцами. Курсор превратится в двухстрелочный указатель. Перемещая его, можно изменять ширину столбца.
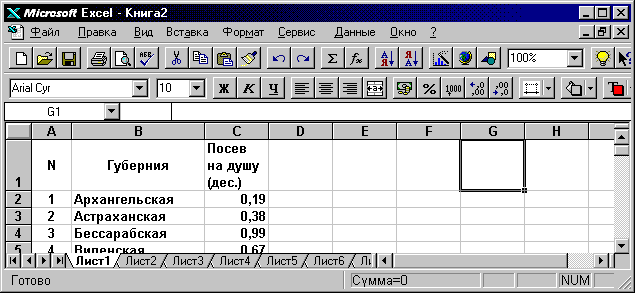
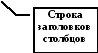
Фиг. 3.1
Ряд данных, представленный на фиг. 1 не ранжирован. Для ранжирнования таблицы 3.1 необходимо губернии расположить не в алфавитном порядке, а в порядке возрастания величины посева на душу.
С этой целью необходимо выполнить следующие действия:
-
Выделим столбцы A, B, C. Для этого поместим курсор на заголовок столбца А, нажмем левую клавишу мыши и, не отпуская ее, протащим курсор от А до С. Затем в С отпустим клавишу мыши.
-
Выполним команды меню: ДАННЫЕ- СОРТИРОВКА. На экране появляется диалоговое окно, показанные на фиг. 3.2.
Фиг. 3.2
-
Щелкнув на кнопке со стрелкой в группе СОРТИРОВАТЬ ПО, получим список полей. Выберем в этом списке поле ПОСЕВ НА ДУШУ и щелкнем по кнопке ОК.
-
В итоге получим список губерний, ранжированный по величине ПОСЕВА НА ДУШУ (Фиг. 3.3 )
Теперь осуществим группировку данных по интервалам.
Для этого предварительно в столбец D введем массив интервалов.
Минимальное число массива должно быть меньше минимального значения признака, равного 0,19. Выберем его равным нулю и введем в ячейку D2. Величину интервала выберем равной 0,1. Затем заполним ячейки D2:D32 рядом значений арифметической прогрессии от 0 до 3 с шагом 0,1. (см. Заполнение столбца A). Полученный результат изображен на фиг. 3.4.
Определим теперь частоты попадания результатов в каждую группу(т.е. интервал). Для этого выделим ячейки E2:E32.
Ф иг.
3.3
иг.
3.3
Затем щелкнем по кнопке МАСТЕР ФУНКЦИЙ. Он отобразит список функций в графе КАТЕГОРИЯ. Выберем в нем СТАТИСТИЧЕСКИЕ. В графе ФУНКЦИЯ выберем ЧАСТОТА и нажмем кнопку ДАЛЕЕ. На экране отобразится диалоговое окно второго из двух шагов выбора функции ЧАСТОТА. Поставим курсор в поле МАССИВ ДАННЫХ. С помощью мыши выделим диапазон значений для функции ЧАСТОТА, т. е. ячейки C2:C51. Он будет окаймлен пунктирной мерцающей рамкой. Теперь поставим курсор в поле ДВОИЧНЫЙ МАССИВ. С помощью мыши выделим диапазон интервалов, т.е. ячейки D3:D32. Затем щелкнем по кнопке ГОТОВО. Поставим курсор в СТРОКУ ФОРМУЛ
(Фиг. 3.3). Нажмем [SHIFT]+[CTRL]+[ENTER], указав тем самым программе, что вводится не просто очередная формула, а формула массивов. Результат появится в ячейках Е2:E32. Здесь в каждой ячейке помещается величина попадания результатов в каждую группу(т.е. в интервал) (xi). (Фиг.3.4)
Определим теперь частоту (fi), по формуле (3.1).
Значения частоты для различных интервалов разместим в ячейках F2:F32.
Для этого выделим ячейку F2 и введем в неё формулу: =E2/50. В нижнем правом углу рамки этой ячейки находится небольшой квадратик, именуемый маркером заполнения. Подведём курсор к маркеру заполнения. Курсор превратится в чёрный крестик. Нажмём левую клавишу мыши и, не отпуская её, протащим маркер до конца ячейки F32, затем отпустим. Ячейки F2:F32 будут заполнены значениями частоты. В ячейку F1 поместим соответствующий заголовок (См. Фиг.3.4).
Стандартный набор статистических характеристик обычно включает: среднее арифметическое значение, дисперсию, среднее квадратическое отклонение, а также минимальное и максимальное значения признака.
Средним арифметическим значением признака x называется величина
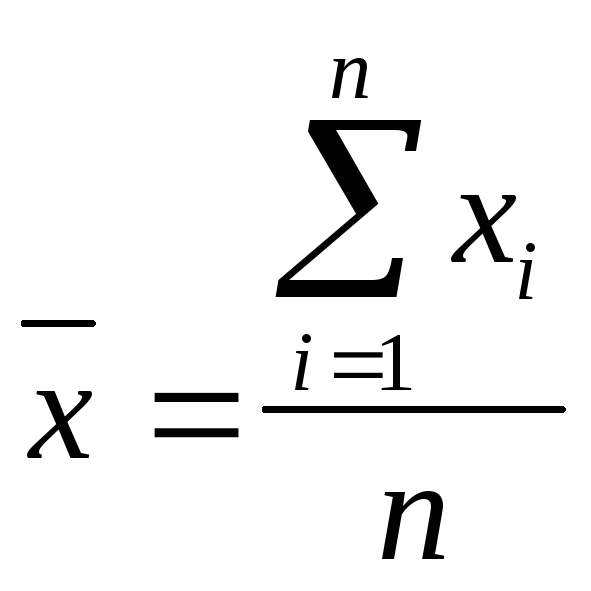 , (3.2)
, (3.2)
где xi- значение признака у i-го объекта, n- число объектов в совокупности.
Среднее арифметическое является характеристикой расположения признака х, которая представляет собой типичное значение признака, центральную точку его распределения.
Дисперсия D(x) есть среднее арифметическое из квадратов отклонений значений признака от среднего арифметического, то есть:
D(х)=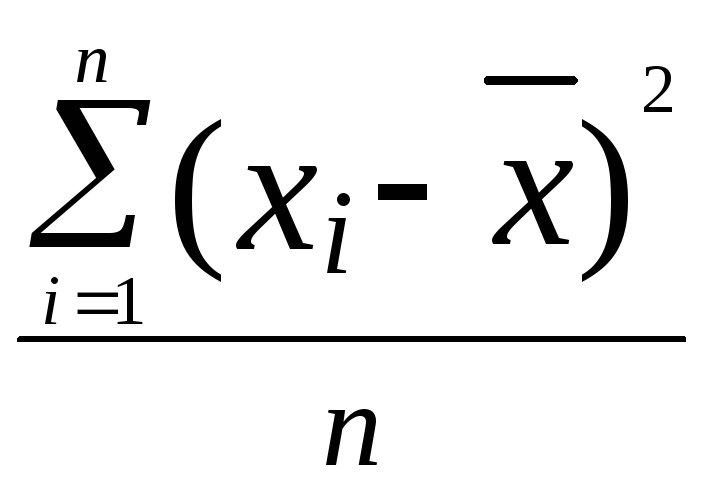 .
(3.3)
.
(3.3)
При небольших объемах выборки используется другая формула, позволяющая получить несмещенную оценку
D(х)=![]() . (3.4)
. (3.4)
Дисперсия является параметром, показывающим, насколько широко разбросаны значения признака по каждую сторону от типичного значения.
Параметр такого рода называется характеристикой рассеяния или, иногда, характеристикой сосредоточения. Рассеяние и сосредоточение находятся, конечно, в обратной зависимости: чем больше рассеяние, тем меньше сосредоточение, и наоборот.
Средним квадратическим отклонением (стандартным отклонением) признака х называется величина
a(х)=![]() . (3.5)
. (3.5)
Стандартное отклонение является более удобной характеристикой чем дисперсия, так как измеряется в тех же единицах, что и сам признак.
Теперь определим среднее арифметическое посева на душу. Для этого выделим ячейку, в которую поместим результат, например, ячейку N2. Затем щелкнем по кнопке МАСТЕР ФУНКЦИЙ. Он отобразит список функций в графе КАТЕГОРИЯ. Выберем в нем СТАТИСТИЧЕСКИЕ. В графе ФУНКЦИЯ выберем СРЗНАЧ и нажмем кнопку ДАЛЕЕ. На экране отобразится диалоговое окно второго из двух шагов выбора функции СРЗНАЧ. Поставим курсор в поле ЧИСЛО 1.С помощью мыши выделим диапазон значений для функции СРЗНАЧ, т. е. ячейки C2:C51. Он будет окаймлен пунктирной мерцающей рамкой. Затем щелкнем по кнопке ГОТОВО. Результат появится в ячейке N2. ( Фиг. 3.4 )
Для определения дисперсии:
-
выделим ячейку, в которую поместим результат, например, ячейку N3.
-
Затем щелкнем по кнопке МАСТЕР ФУНКЦИЙ. Он отобразит список функций в графе КАТЕГОРИЯ. Выберем в нем СТАТИСТИЧЕСКИЕ. В графе ФУНКЦИЯ выберем ДИСП и нажмем кнопку ДАЛЕЕ. На экране отобразится диалоговое окно второго из двух шагов выбора функции ДИСП. Поставим курсор в поле ЧИСЛО 1.С помощью мыши выделим диапазон значений для функции ДИСП, т. е. ячейки C2:C51. Он будет окаймлен пунктирной мерцающей рамкой. Затем щелкнем по кнопке ГОТОВО. Результат появится в ячейке N3. (Фиг.3.4)
Для определения стандартного отклонения :
-
Выделим ячейку для помещения в нее значения стандартного отклонения (N4),
-
Щелкнем по кнопке ГОТОВО. Он отобразит список функций в графе КАТЕГОРИЯ.
-
Выберем в нем МАТЕМАТИЧЕСКИЕ.
-
В графе ФУНКЦИЯ выберем КОРЕНЬ и нажмем кнопку ДАЛЕЕ.
-
Поставим курсор в поле ЧИСЛО 1.
-
Выделим ячейку N3,
-
Затем щелкнем по кнопке ГОТОВО. Результат появится в ячейке N4.
( Фиг. 3.4 )
Теперь в ячейки M2, M3, M4 поместим названия полученных параметров Среднее, Дисперсия, Станд. Откл, а в ячейку M1 в нескольких соответствующий заголовок (Фиг.3.4).
Фиг.3.4
 Если
заголовок необходимо расположить
столбцах, то следует выделить этот
заголовок и ряд ячеек левее его, затем
нажать кнопку ЦЕНТРИРОВАТЬ ПО СТОЛЦБАМ
(Фиг.3.4)
Если
заголовок необходимо расположить
столбцах, то следует выделить этот
заголовок и ряд ячеек левее его, затем
нажать кнопку ЦЕНТРИРОВАТЬ ПО СТОЛЦБАМ
(Фиг.3.4)
Частота f задаёт закон распределения выбранного признака, т.е. посева на душу, по заданным интервалам, а Среднее, Дисперсия и Станд. Откл являются характеристиками этого распределения.
Построим теперь гистограмму этого закона распределения.
Для этого выполним следующие действия:
-
Выделим ряд значений частоты f (ячейки F1:F32).
-
Щелкнем по кнопке МАСТЕР ДИАГРАММ. При этом курсор превращается в крестик, сопровождаемый значком гистограммы. Поместим его в верхний левый угол той области, в которой будет расположена гистограмма.
-
После этого вызывается МАСТЕР ДИАГРАММ (ШАГ 1). Поскольку нужный диапазон уже определен щелкнем по кнопке Далее.
-
На экране появляется диалоговое окно (ШАГ 2), предлагающее 15 вариантов диаграмм. Сделаем щелчек на диаграмме ГИСТОГРАММА, затем на кнопке ДАЛЕЕ.
-
На экране появляется диалоговое окно (ШАГ 3), предлагающее 10 вариантов выбранной диаграммы. Щелкнем на гистограмме 8, затем на кнопке ДАЛЕЕ.
-
На экране появляется диалоговое окно (ШАГ 4), в котором изображен выбранный график. Щелкнем по кнопке ДАЛЕЕ.
-
На экране появляется диалоговое окно (ШАГ 5). Это последний шаг. На этом шаге выберем ЛЕГЕНДУ, т. е. условное обозначение на графике рядов данных. Затем в окне НАЗВАНИЕ ДИАГРАММЫ введем с пульта ГИСТОГРАММА. В окнах НАЗВАНИЕ ПО ОСИ введем названия осей X и f. Теперь щелкнем по кнопке ГОТОВО. Полученная диаграмма изображена на Фиг.3.5.
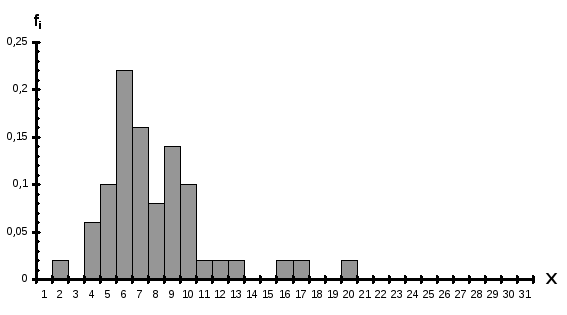
Фиг.3.5
В полученную гистограмму можно вносить изменения. Для этого двойным щелчком на ней выделим её, затем осуществляем щелчок правой кнопкой мыши по той области гистограммы, в которую нужно внести изменения. В появившемся контекстном меню следует выбрать подходящую команду.
Сначала изменим значения оси Х. Щёлкнем правой кнопкой мыши по оси Х. В появившемся контекстном меню следует выбрать команду ФОРМАТ РЯДА... В появившемся диалоговом окне ФОРМАТИРОВАНИЕ РЯДА ДАННЫХ щёлкнем по вкладке ЗНАЧЕНИЯ Х. Затем щёлкнем по окошку ЗНАЧЕНИЯ Х. После этого в нём появится мигающий курсор. Для выбора ячеек, содержащих значения Х необходимо щёлкнуть по листу Excel, в котором находятся эти ячейки. С помощью мыши выделим диапазон значений для оси Х, т. е. ячейки D2:D32. Он будет окаймлен пунктирной мерцающей рамкой. Затем щелкнем по
кнопке ГОТОВО. Для оси Х будут введены новые значения от 0 до 3. (Фиг.3.6).
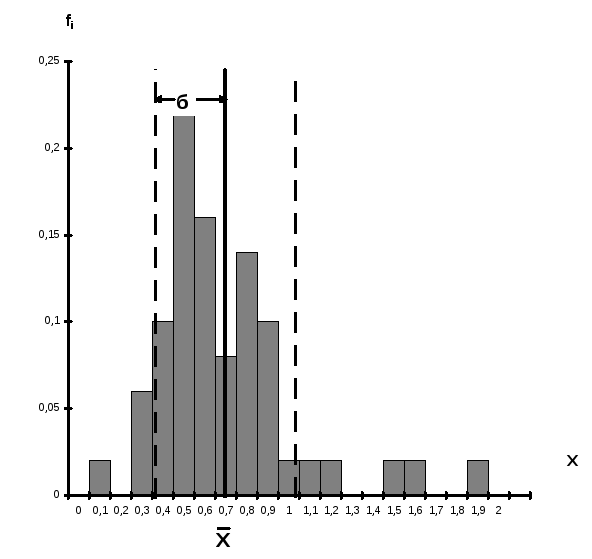
Задание 2. Частотный анализ географических названий
В качестве исходных данных рассматриваются географические названия в количестве N=17788. Все названия разбиваются на группы слов, начинающиеся с одинаковой буквы. В таблице 3.3 приведено количество слов в каждой группе.
|
№ группы |
Нач. буква |
Колич. слов в группе |
№ группы |
Нач. буква |
Колич. слов в группе |
|
1 |
А |
930 |
16 |
П |
1034 |
|
2 |
Б |
1397 |
17 |
Р |
473 |
|
3 |
В |
691 |
18 |
С |
1678 |
|
4 |
Г |
625 |
19 |
Т |
1029 |
|
5 |
Д |
750 |
20 |
У |
457 |
|
6 |
Е |
95 |
21 |
Ф |
330 |
|
7 |
Ж |
95 |
22 |
Х |
504 |
|
8 |
З |
249 |
23 |
Ц |
185 |
|
9 |
И |
392 |
24 |
Ч |
440 |
|
10 |
Й |
46 |
25 |
Ш |
335 |
|
11 |
К |
2148 |
26 |
Щ |
13 |
|
12 |
Л |
776 |
27 |
Ы |
4 |
|
13 |
М |
1268 |
28 |
Э |
348 |
|
14 |
Н |
767 |
29 |
Ю |
129 |
|
15 |
О |
467 |
30 |
Я |
133 |
В этой таблице в качестве признака служит количество слов в группе. Различные значения этого признака для разных начальных букв представляют собой статистический ряд.
Построим теперь гистограмму статистического ряда. В качестве независимой переменной Х будем считать начальную букву географического названия или соответствующий ей номер группы. В качестве функции будем рассматривать численное значение признака, т.е. количество слов, попадающих в ту или иную группу.
Построение гистограммы выполняется в среде Excel следующим образом.
Сначала осуществим запуск Excel.
Для этого необходимо:
-
Щелкнуть на кнопке ПУСК на панели задач Windows и выбрать меню ПРОГРАММЫ.
-
В открывшемся меню активизировать пункт Microsoft Excel.
-
Во время запуска программы на экране появляется заставка Excel, и через несколько секунд система готова к работе.
Теперь данные таблицы 3.3 внесем в ячейки таблицы Excel. Данные 1-го столбца внесем в ячейки столбца A.
В первой ячейке этого столбца поместим заголовок - № группы. С этой целью выделим ячейку А1. Для этого необходимо щелкнуть на ней левой клавишей мыши, т. е. поместить в эту ячейку курсор мыши (он имеет вид крестика), нажать и отпустить левую клавишу мыши. Ячейка становится активной и выделяется жирной рамкой. Теперь введем в эту ячейку с клавиатуры - № группы.
Затем в ячейку А2 введем начальный номер 1 Заполним теперь столбец А, используя формулу арифметической прогрессии.
С этой целью сначала выделим те ячейки столбца А, которые будут заполнены (ячейки A2:A31). Для этого необходимо подвести курсор мыши к ячейке А2, нажать левую клавишу и, не отпуская ее, протащить курсор от ячейки А2 до ячейки А31, а затем отпустить. Ячейки А2:А31 становятся активными и выделяются жирной рамкой.
Затем выполним команду ПРАВКА- ЗАПОЛНИТЬ- ПРОГРЕССИЯ.
В открывшемся диалоговом окне ПРОГРЕССИЯ выбрать подходящие опции (РАСПОЛОЖЕНИЕ- ПО СТОЛБАМ; ТИП- АРИФМЕТИЧЕСКАЯ; ШАГ- 1) и щелкнуть по клавише ОК. В результате ячейки А2:A31 будут заполнены рядом значений от 1 до 30.(Фиг.3.8).
Ячейки столбцов B и C заполняются подобно ячейке А1.
В ячейку F1 внести букву N, в ячейку F2 число 17788.
Замечание 1. При заполнении ячеек числами следует помнить, что целая часть числа от дробной отделяется не точкой, а запятой.
Замечание 2. Перенос на другую строку в ячейке осуществляется с помощью нажатия клавиш Alt + Enter.
При заполнении ячеек можно отрегулировать размеры столбцов. Для этого курсор мыши необходимо поместить в строку заголовков столбцов на границу между столбцами. Курсор превратится в двух стрелочный указатель. Перемещая его, с нажатой левой клавишей мыши можно изменять размеры столбца.
Определим теперь частоту (fi), равную отношению количества
слов в группе- ni к общему числу слов- N, т.е.
fi = ni / N,
где N=17788.
Значения частоты для различных начальных слов разместим в ячейках D2:D31.
Для этого выделим ячейку D2 и введем в неё формулу: =C2/$F$2. В нижнем правом углу рамки этой ячейки находится небольшой квадратик, именуемый маркером заполнения. Подведём курсор к маркеру заполнения. Курсор превратится в чёрный крестик. Нажмём левую клавишу мыши и, не отпуская её, протащим маркер до конца ячейки D31, затем отпустим. Ячейки D2:D31 будут заполнены значениями частоты. В ячейку D1 поместим соответствующий заголовок (Фиг.3.8)
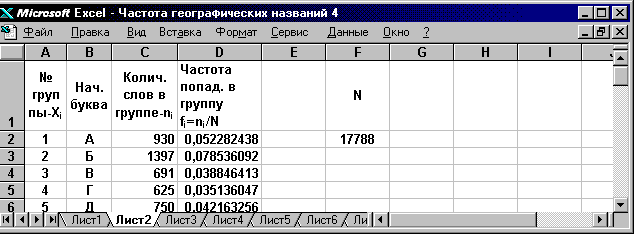
Фиг. 3.8
Построим теперь гистограмму статистического ряда.
Для этого выполним следующие действия:
-
Выделим ряд значений частоты f (ячейки F1:F32).
-
Щелкнем по кнопке МАСТЕР ДИАГРАММ. При этом курсор превращается в крестик, сопровождаемый значком гистограммы. Поместим его в верхний левый угол той области, в которой будет расположена гистограмма.
-
После этого вызывается МАСТЕР ДИАГРАММ (ШАГ 1). Поскольку нужный диапазон уже определен щелкнем по кнопке Далее.
-
На экране появляется диалоговое окно (ШАГ 2), предлагающее 15 вариантов диаграмм. Сделаем щелчок на диаграмме ГИСТОГРАММА, затем на кнопке ДАЛЕЕ.
-
На экране появляется диалоговое окно (ШАГ 3), предлагающее 10 вариантов выбранной диаграммы. Щелкнем на гистограмме 8, затем на кнопке ДАЛЕЕ.
-
На экране появляется диалоговое окно (ШАГ 4), в котором изображен выбранный график. Щелкнем по кнопке ДАЛЕЕ.
-
На экране появляется диалоговое окно (ШАГ 5). Это последний шаг. На этом шаге выберем ЛЕГЕНДУ, т. е. условное обозначение на графике рядов данных. Затем в окне НАЗВАНИЕ ДИАГРАММЫ введем с клавиатуры ГИСТОГРАММА. В окнах НАЗВАНИЕ ПО ОСИ введем названия осей X и f. Теперь щелкнем по кнопке ГОТОВО.
В полученную гистограмму можно вносить изменения. Для этого двойным щелчком на ней выделим её, затем осуществляем щелчок правой кнопкой мыши по той области гистограммы, в которую нужно внести изменения. В появившемся контекстном меню следует выбрать подходящую команду.
Сначала изменим значения оси Х. Щёлкнем правой кнопкой мыши по оси Х. В появившемся контекстном меню следует выбрать команду ФОРМАТ РЯДА... В появившемся диалоговом окне ФОРМАТИРОВАНИЕ РЯДА ДАННЫХ щёлкнем по вкладке ЗНАЧЕНИЯ Х. Затем щёлкнем по окошку ЗНАЧЕНИЯ Х. После этого в нём появится мигающий курсор. Для выбора ячеек, содержащих значения Х необходимо щёлкнуть по листу Excel, в котором находятся эти ячейки. С помощью мыши выделим диапазон значений для оси Х, т. е. ячейки
D2:D32. Он будет окаймлен пунктирной мерцающей рамкой. Затем щелкнем по кнопке ГОТОВО. Для оси Х будут введены новые значения от А до Я.
Теперь эти новые значения поместим над столбиками гистограммы.
Для этого щёлкнем правой кнопкой мыши по оси Х. В появившемся контекстном меню следует выбрать команду ФОРМАТ РЯДА... В появившемся диалоговом окне ФОРМАТИРОВАНИЕ РЯДА ДАННЫХ щёлкнем по вкладке МЕТКИ. В графе ВЫВЕСТИ В КАЧЕСТВЕ МЕТКИ щёлкнем левой кнопкой мыши по отметке НАЗВАНИЕ КАТЕГОРИИ. Значения букв появятся над столбиками гистограммы (Фиг. 3.9). Для внедрения гистограммы в документ Excel необходимо щёлкнуть левой кнопкой мыши вне редактируемой гистограммы.
Для
окончательного редактирования нужно
убрать буквы под осью Х и заменить их
цифрами. При этом необходимо использовать
панель инструментов РИСОВАНИЕ,
которую можно вызвать с помощью
соответствующей кнопки. На панели
РИСОВАНИЕ
нужно нажать кнопку НАДПИСЬ
![]() и
с помощью мыши развернуть пунктирную
рамку на месте букв, помещенных под осью
Х. В полученной рамке напечатать
необходимый ряд цифр (Фиг. 3.9).
и
с помощью мыши развернуть пунктирную
рамку на месте букв, помещенных под осью
Х. В полученной рамке напечатать
необходимый ряд цифр (Фиг. 3.9).
Полученная гистограмма соответствует алфавитному порядку расположения букв. В ряде случаев алфавитный порядок непригоден для решения некоторых вопросов анализа и возникает задача определения другого, соответствующего решаемой проблеме, порядка расположения букв. Следует отметить, что общее число всех возможных порядков равно n!, где n- число букв алфавита, в данном случае равное 30.
Определим ряд новых порядков расположения букв, исходя из соответствующих критериев.
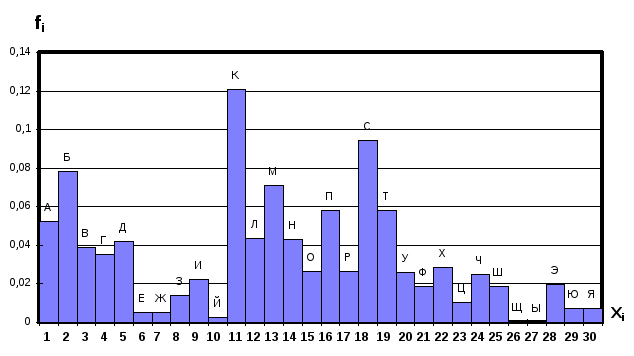
Фиг. 3.9
В качестве первого критерия установим необходимость возрастания численного значения признака с увеличением номера группы.
Для этого необходимо проранжировать таблицу 1, т.е. буквы расположить не в алфавитном порядке, а в порядке возрастания величины признака.
С этой целью необходимо выполнить следующие действия:
-
Выделим столбцы A, B, C, D. Для этого поместим курсор на заголовок столбца А, нажмем ее левую клавишу и, не отпуская ее, протащим курсор от А до D. Затем в D отпустим клавишу мыши.
-
Выполним команды меню: ДАННЫЕ- СОРТИРОВКА . На экране появляется диалоговое окно, подобное показанному на фиг. 3.10. Щелкнув на кнопке со стрелкой в группе СОРТИРОВАТЬ ПО, получим список полей. Выберем в этом списке поле ЧАСТОТА и щелкнем по кнопке ОК.
-
В итоге получим список букв, ранжированный по величине ЧАСТОТА ( Фиг.. 3.10)
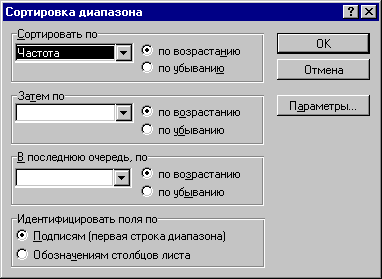
Фиг. 3.10
Новый порядок расположения букв изображен на фиг. 3.11.
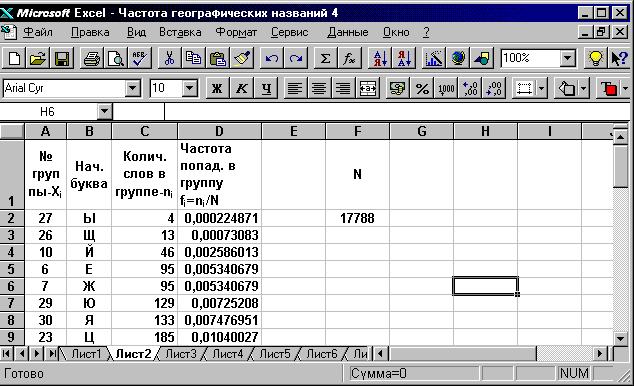
Фиг. 3.11
Для нового порядка расположения букв гистограмма получается автоматически (Фиг. 3.12).
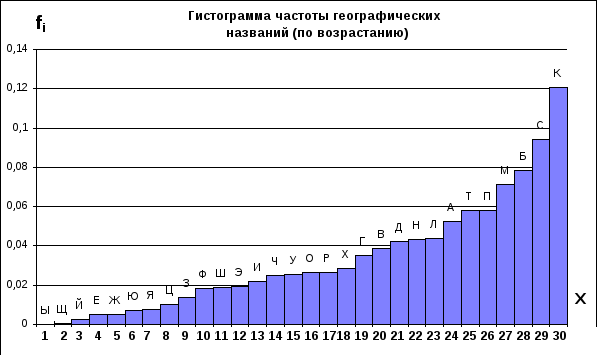
Фиг. 3.12
Этот порядок обозначим, как номер 2, в отличие от алфавитного, который обозначим номером 1.
Порядок 3 определим, исходя из одномодального распределения частоты. Для такого порядка должен иметь место максимум частоты, приходящийся на середину буквенного интервала. С этой целью преобразуем таблицу, соответствующую Фиг.3.11 следующим образом.
Выделим в столбцах A,B,C,D строки с номера 1 по номер 31. Затем при нажатой клавише Ctrl подведем курсор к границе выделенного участка и нажмем левую клавишу мыши. Рядом с курсором появится знак +. Не отпуская нажатых клавиш, переместим выделенную часть таблицы в ячейки, начиная с номера G2 и отпустим обе клавиши. В ячейках G2:J31 разместится второй экземпляр таблицы.
Теперь в первом экземпляре таблицы выделим нечетные, а во втором- четные строки (Фиг.3.13). Для этого при выделении необходимо держать нажатой клавишу Ctrl.
После этого следует нажать клавишу Delete. Выделенные строки исчезнут. Затем необходимо выделить снова первый экземпляр таблицы и выполнить команды меню: ДАННЫЕ- СОРТИРОВКА... На экране появляется диалоговое окно, подобное показанному на фиг.3.10. Щелкнув на кнопке со стрелкой в группе СОРТИРОВАТЬ ПО, получим список полей. Выберем в этом списке поле ЧАСТОТА и щелкнем по кнопке ОК. В результате этой операции пустые строки исчезнут и заполнение таблицы будет сплошным (Фиг. 3.13).
Фиг. 3.13
Затем необходимо выделить второй экземпляр таблицы и выполнить команды меню: ДАННЫЕ- СОРТИРОВКА... На экране появляется диалоговое окно, подобное показанному на рис. 3.10 Щелкнув на кнопке со стрелкой в группе СОРТИРОВАТЬ ПО, получим список полей. Выберем в этом списке поле СТОЛБЕЦ J, ПО УБЫВАНИЮ и щелкнем по кнопке ОК. В результате этой операции пустые строки исчезнут и заполнение таблицы будет сплошным (Фиг. 3.14).
Фиг. 3.14
Теперь необходимо
второй экземпляр таблицы расположить
вплотную под первым. Для этого второй
экземпляр таблицы нужно выделить и
перетащить с помощью мыши. После этой
процедуры автоматически создается
гистограмма, соответствующая новому
порядку букв (Фиг. 3.15). 

 Определим
теперь среднее значение Х
полученного
распределения.
Определим
теперь среднее значение Х
полученного
распределения.
Для этого воспользуемся следующей формулой:
![]() ( 3.6 ),
( 3.6 ),
где Х i - номер группы, f i - соответствующая этому номеру частота,
n - число групп, равное 30.


Фиг. 3.15
Для реализации формулы (3.6) в ячейку E2 введем =A2*D2 и нажмем клавишу Enter. В нижнем правом углу рамки этой ячейки находится небольшой квадратик, именуемый маркером заполнения. Подведём курсор к маркеру заполнения. Курсор превратится в чёрный крестик. Нажмём левую клавишу мыши и, не отпуская её, протащим маркер до конца ячейки E31, затем отпустим. Ячейки E2:E31 будут заполнены значениями произведений Xi fi. В ячейку E1 поместим соответствующий заголовок
(Фиг.3.16).
Теперь определим среднее значение Х полученного распределения. Для этого выделим ячейку, в которую поместим результат, например, ячейку F4. Затем щелкнем по кнопке МАСТЕР ФУНКЦИЙ. Он отобразит список функций в графе КАТЕГОРИЯ. Выберем в нем МАТЕМАТИЧЕСКИЕ. В графе ФУНКИЯ выберем СУММ и нажмем кнопку ДАЛЕЕ. На экране отобразится диалоговое окно второго из двух шагов выбора функции СУММ. Поставим курсор в поле ЧИСЛО 1.С помощью мыши выделим диапазон значений для функции СУММ, т. е. ячейки E2:E31. Он будет окаймлен пунктирной мерцающей рамкой. Затем щелкнем по кнопке ГОТОВО. Результат появится в ячейке F4. ( Фиг. 3.16 ). В ячейку F3 введем соответствующий заголовок (Фиг. 3.16 ).
Стандартное отклонение б(Х) определяется следующим образом:
 (3.7)
(3.7)
Для реализации формулы (2) в ячейку G2 введем =D2*(A2-$F$4)^2 и нажмем клавишу Enter. В нижнем правом углу рамки этой ячейки находится небольшой квадратик, именуемый маркером заполнения. Подведём курсор к маркеру заполнения. Курсор превратится в чёрный крестик. Нажмём левую клавишу мыши и, не отпуская её, протащим маркер до конца ячейки G31, затем отпустим. Ячейки G2:G31 будут заполнены значениями произведений для формулы (3.7). В ячейку G1 поместим соответствующий заголовок (См. Фиг.3.16).
Теперь определим квадрат cтандартного отклонения б(Х) полученного распределения. Для этого выделим ячейку, в которую поместим результат, например, ячейку F6. Затем щелкнем по кнопке МАСТЕР ФУНКЦИЙ. Он отобразит список функций в графе КАТЕГОРИЯ . Выберем в нем МАТЕМАТИЧЕСКИЕ. В графе ФУНКЦИЯ выберем СУММ и нажмем кнопку ДАЛЕЕ. На экране отобразится диалоговое окно второго из двух шагов выбора функции СУММ. Поставим курсор в поле ЧИСЛО1. С помощью мыши выделим диапазон значений для функции СУММ, т. е. ячейки G2:G31. Он будет окаймлен пунктирной мерцающей рамкой. Затем щелкнем по кнопке ГОТОВО. Результат- б2 появится в ячейке F6. ( Фиг. 3.16 ). В ячейку F5 введем соответствующий заголовок ( Фиг. 3.16 ).
Для определения б выделим ячейку F8 и введем в нее формулу =F5^,5. После нажатия клавиши Enter в ячейке F8 появится результат.
Фиг. 3.16
В полученной гистограмме можно произвести также другие изменения. Два самых крупных объекта гистограммы это фон, или область диаграммы, и пространство между двумя осями, или область построения.
Можно изменять цвета, узоры и рамки областей. Позиционируя курсор между осями, двойным щелчком вы инициируете форматирование области построения; то же самое, но вне осей, обеспечивает форматирование области гистограммы. Двойным щелчком по столбикам гистограммы можно изменить их раскраску.

 Теперь
отметим на гистограмме значения среднего-
Х и стандартного
отклонения-
б. Для этого,
нажав на кнопку РИСОВАНИЕ
вызовем
панель инструментов РИСОВАНИЕ. Щёлкнем
по клавише ЛИНИЯ
. Курсор
превратится в крестик. Этот крестик
установим в точку на оси Х, соответствующую
Х, нажмём SHIFT
и левую клавишу мыши и протащим курсор,
не отпуская клавиш, до верхней рамки
гистограммы, где отпустим клавиши. С
помощью двойного щелчка по проведённой
линии можно изменить её вид, цвет и
толщину.
Теперь
отметим на гистограмме значения среднего-
Х и стандартного
отклонения-
б. Для этого,
нажав на кнопку РИСОВАНИЕ
вызовем
панель инструментов РИСОВАНИЕ. Щёлкнем
по клавише ЛИНИЯ
. Курсор
превратится в крестик. Этот крестик
установим в точку на оси Х, соответствующую
Х, нажмём SHIFT
и левую клавишу мыши и протащим курсор,
не отпуская клавиш, до верхней рамки
гистограммы, где отпустим клавиши. С
помощью двойного щелчка по проведённой
линии можно изменить её вид, цвет и
толщину.

 Точно таким же способом проведём линию
через значение Х=Х+б. Затем при нажатой
клавише CTRL
перетащим данную линию к значению
Точно таким же способом проведём линию
через значение Х=Х+б. Затем при нажатой
клавише CTRL
перетащим данную линию к значению
Х =Х-
б.
=Х-
б.
Для размещения на гистограмме дополнительных надписей ( Х и б ) необходимо на панели инструментов РИСОВАНИЕ щёлкнуть по клавише НАДПИСЬ . Курсор превратится в крестик. С помощью этого крестика следует в нужном месте гистограммы нарисовать прямоугольник, в который вносится дополнительная надпись. С помощью двойного щелчка по дополнительной надписи её можно отредактировать, в том числе убрать рамку, т. е. прямоугольник.
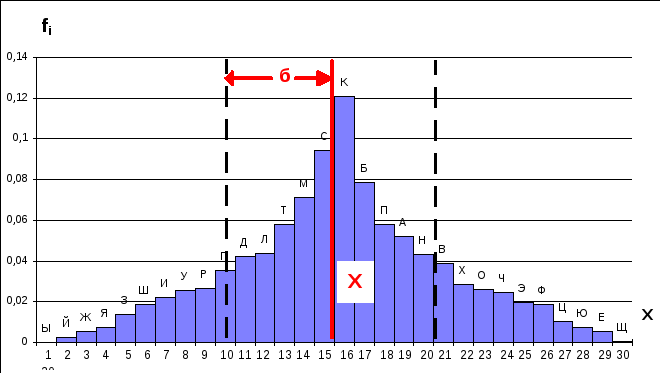
Рассматривая построенную гистограмму, можно сделать вывод, что среднее является характеристикой расположения полученного распределения и представляет собой центральную точку его распределения. Величина среднего, равного 15,8, показывает, что это значение находится в 15-ой группе, соответствующей букве С. Если бы распределение было симметричным, то среднее совпало бы с модой распределения, т.е. с буквой А. По обе стороны от этого значения группируются остальные значения признака.
Стандартное отклонение- б является параметром, показывающим, насколько широко разбросаны значения признака по каждую сторону от типичного значения. Параметр такого рода называется характеристикой рассеяния или, иногда, характеристикой сосредоточения.
Преобразуем теперь полученную таблицу Excel таким образом, чтобы в начале ее следовали гласные, а затем согласные. При этом порядок следования гласных и согласных не должен меняться. Для этого строки, содержащие гласные и включающие ячейки A-E, необходимо выделить и переместить в другое место таблицы, например, начиная с ячейки H2.

Фиг. 3.17
Оставшиеся строки с согласными буквами необходимо сдвинуть вниз вплотную друг к другу , а на освободившееся место переместить строки с гласными буквами. Теперь необходимо перенумеровать столбец А по порядку следования строк. Для этого следует выделить столбец А и нажать клавишу Delete. Порядок выполнения нумерации описан выше.(Фиг. 3.18).
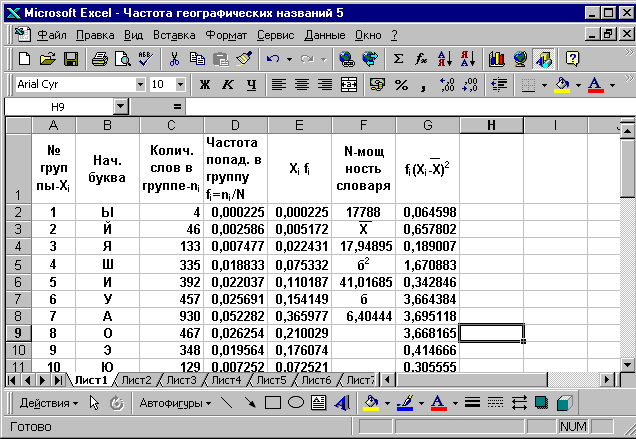
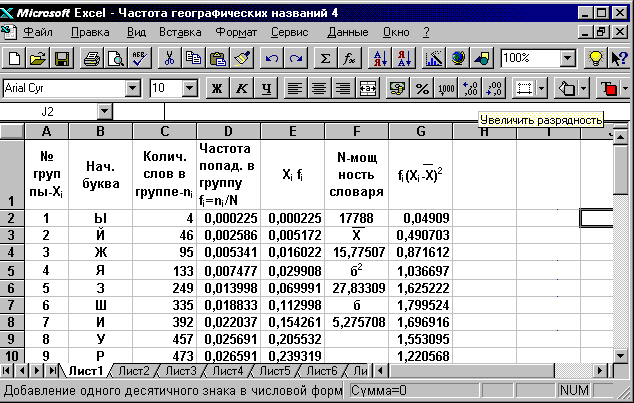
После этой процедуры автоматически создается гистограмма, соответствующая новому порядку букв (Фиг. 3.19).
Определим теперь характеристики нового распределения отдельно для гласных и согласных. Так как мы имеем дело с совместным распределением, то формулы (3.6) и (3.7) необходимо пронормировать. Тогда средние для гласных и согласных будут иметь вид (3.8) и (3.9).
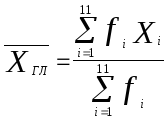 (3.8)
(3.8)
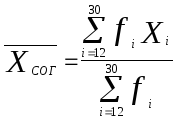 (3.9)
(3.9)
Стандартные отклонения для гласных и согласных будут иметь вид (3.10) и (3.11)
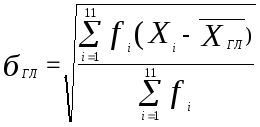 (3.10)
(3.10)
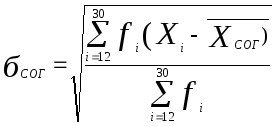 (3.11)
(3.11)
Теперь необходимо, используя полученные формулы, получить численные значения данных характеристик.
Прежде всего очистим ячейки F3-F8. Затем определим среднее значение Х полученного распределения для гласных. Для этого выделим ячейку, в которую поместим первый промежуточный результат, например, ячейку F10. Затем щелкнем по кнопке МАСТЕР ФУНКЦИЙ. Он отобразит список функций в графе КАТЕГОРИЯ. Выберем в нем МАТЕМАТИЧЕСКИЕ. В графе ФУНКЦИЯ выберем СУММ и нажмем кнопку ДАЛЕЕ. На экране отобразится диалоговое окно второго из двух шагов выбора функции СУММ. Поставим курсор в поле ЧИСЛО 1.С помощью мыши выделим диапазон значений для функции СУММ, т. е. ячейки E2:E11. Он будет окаймлен пунктирной мерцающей рамкой. Затем щелкнем по кнопке ГОТОВО. Результат появится в ячейке F10. ( Фиг. 3.19). В ячейку F9 введем соответствующий заголовок, используя редактор формул Equation из меню ВСТАВКА- ОБЪЕКТ- EQUATIN ( Фиг. 3.19).
Такую же процедуру проделаем для ячеек D2:D11. Второй промежуточный результат и соответствующий заголовок поместим в ячейки F8 и F7.
Теперь найдем среднее для гласных. Для этого выделим ячейку, в которую поместим окончательный результат, например, ячейку F4. Затем щелкнем по клавише = , последовательно щелкнем ячейку F10, клавишу / , ячейку F8 и нажмем клавишу ENTER. В ячейку F3 поместим соответствующий заголовок.
Аналогичным образом определим среднее для согласных. Разница заключается лишь в том, что вместо ячеек E2:E11 и D2:D11 используются ячейки E12:E31 и D12:D31.
Промежуточные результаты поместим в ячейки F11:F14, а окончательный результат, т.е. среднее для согласных, в ячейки F5:F6.
Перейдем теперь к определению стандартного отклонения для гласных и согласных. Для этого выделим ячейку, в которую поместим первый промежуточный результат, например, ячейку F16. Затем щелкнем по кнопке МАСТЕР ФУНКЦИЙ. Он отобразит список функций в графе КАТЕГОРИЯ. Выберем в нем МАТЕМАТИЧЕСКИЕ. В графе ФУНКЦИЯ выберем СУММ и нажмем кнопку ДАЛЕЕ. На экране отобразится диалоговое окно второго из двух шагов выбора функции СУММ. Поставим курсор в поле ЧИСЛО 1.С помощью мыши выделим диапазон значений для функции СУММ, т. е. ячейки G2:G11. Он будет окаймлен пунктирной мерцающей рамкой. Затем щелкнем по кнопке ГОТОВО. Результат появится в ячейке F10. ( Фиг. 3.19). В ячейку F9 введем соответствующий заголовок, используя редактор формул Equation из меню ВСТАВКА- ОБЪЕКТ- EQUATIN ( Фиг. 3.19).
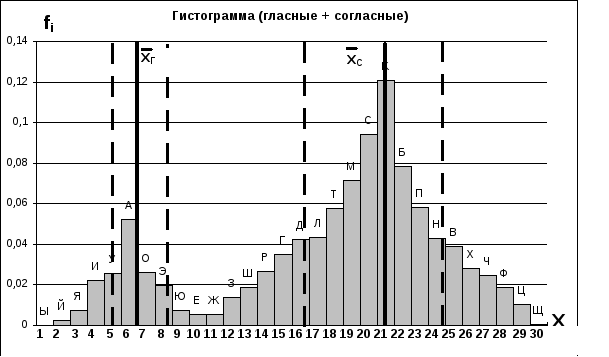
Фиг. 3.19
Теперь найдем квадрат стандартного отклонения для гласных. Для этого выделим ячейку, в которую поместим результат, например, ячейку F18. Затем щелкнем по клавише = , последовательно щелкнем ячейку F16, клавишу / , ячейку F8 и нажмем клавишу Enter. В ячейку F17 поместим соответствующий заголовок.
Для определения стандартного отклонения для гласных выделим ячейку, в которую поместим результат, например, ячейку F20. Затем щелкнем по клавише = , последовательно щелкнем ячейку F18, клавишу ^ , цифру 0,5 и нажмем клавишу Enter. В ячейку F19 поместим соответствующий заголовок.
Аналогичным образом определим стандартное отклонение для согласных. Разница заключается лишь в том, что вместо ячеек G2:G11 используются ячейки G12:G31.
Промежуточные результаты поместим в ячейки F21:F24, а окончательный результат, т.е. стандартное отклонение для согласных, в ячейки F25:F26.
Рисование соответствующих линий на полученной диаграмме осуществляется по методике, которая описана выше.