

Лабораторная работа № 13 Частотный анализ в филологических исследованиях (на базе словарей)
В качестве исходных данных рассматриваются географические названия в количестве N=17788. Все названия разбиваются на группы слов, начинающиеся с одинаковой буквы. В таблице 3.3 приведено количество слов в каждой группе.
|
№ группы |
Нач. буква |
Колич. слов в группе |
№ группы |
Нач. буква |
Колич. слов в группе |
|
1 |
А |
930 |
16 |
П |
1034 |
|
2 |
Б |
1397 |
17 |
Р |
473 |
|
3 |
В |
691 |
18 |
С |
1678 |
|
4 |
Г |
625 |
19 |
Т |
1029 |
|
5 |
Д |
750 |
20 |
У |
457 |
|
6 |
Е |
95 |
21 |
Ф |
330 |
|
7 |
Ж |
95 |
22 |
Х |
504 |
|
8 |
З |
249 |
23 |
Ц |
185 |
|
9 |
И |
392 |
24 |
Ч |
440 |
|
10 |
Й |
46 |
25 |
Ш |
335 |
|
11 |
К |
2148 |
26 |
Щ |
13 |
|
12 |
Л |
776 |
27 |
Ы |
4 |
|
13 |
М |
1268 |
28 |
Э |
348 |
|
14 |
Н |
767 |
29 |
Ю |
129 |
|
15 |
О |
467 |
30 |
Я |
133 |
Таблица 3.3
В этой таблице в качестве признака служит количество слов в группе. Различные значения этого признака для разных начальных букв представляют собой статистический ряд.
Построим теперь гистограмму статистического ряда. В качестве независимой переменной Х будем считать начальную букву географического названия или соответствующий ей номер группы. В качестве функции будем рассматривать численное значение признака, т.е. количество слов, попадающих в ту или иную группу.
Построение гистограммы выполняется в среде Excel следующим образом.
Сначала осуществим запуск Excel.
Для этого необходимо:
-
Щелкнуть на кнопке ПУСК на панели задач Windows и выбрать меню ПРОГРАММЫ.
-
В открывшемся меню активизировать пункт Microsoft Excel.
-
Во время запуска программы на экране появляется заставка Excel, и через несколько секунд система готова к работе.
Теперь данные таблицы 3.3 внесем в ячейки таблицы Excel. Данные 1-го столбца внесем в ячейки столбца A.
В первой ячейке этого столбца поместим заголовок - № группы. С этой целью выделим ячейку А1. Для этого необходимо щелкнуть на ней левой клавишей мыши, т. е. поместить в эту ячейку курсор мыши (он имеет вид крестика), нажать и отпустить левую клавишу мыши. Ячейка становится активной и выделяется жирной рамкой. Теперь введем в эту ячейку с клавиатуры - № группы.
Затем в ячейку А2 введем начальный номер 1 Заполним теперь столбец А, используя формулу арифметической прогрессии.
С этой целью сначала выделим те ячейки столбца А, которые будут заполнены (ячейки A2:A31). Для этого необходимо подвести курсор мыши к ячейке А2, нажать левую клавишу и, не отпуская ее, протащить курсор от ячейки А2 до ячейки А31, а затем отпустить. Ячейки А2:А31 становятся активными и выделяются жирной рамкой.
Затем выполним команду ПРАВКА- ЗАПОЛНИТЬ- ПРОГРЕССИЯ.
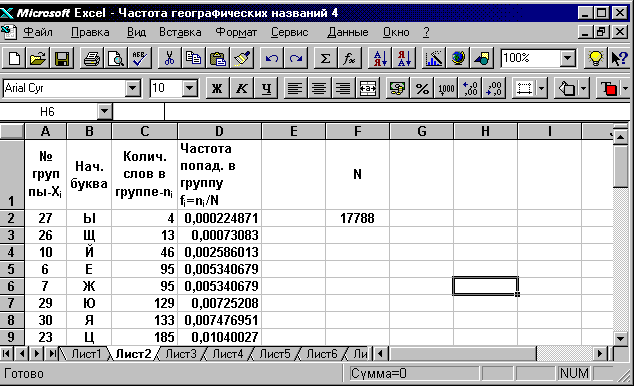
В открывшемся диалоговом окне ПРОГРЕССИЯ выбрать подходящие опции (РАСПОЛОЖЕНИЕ- ПО СТОЛБАМ; ТИП- АРИФМЕТИЧЕСКАЯ; ШАГ- 1) и щелкнуть по клавише ОК. В результате ячейки А2:A31 будут заполнены рядом значений от 1 до 30.(Фиг.3.8).
Ячейки столбцов B и C заполняются подобно ячейке А1.
В ячейку F1 внести букву N, в ячейку F2 число 17788.
Замечание 1. При заполнении ячеек числами следует помнить, что целая часть числа от дробной отделяется не точкой, а запятой.
Замечание 2. Перенос на другую строку в ячейке осуществляется с помощью нажатия клавиш Alt + Enter.
При заполнении ячеек можно отрегулировать размеры столбцов. Для этого курсор мыши необходимо поместить в строку заголовков столбцов на границу между столбцами. Курсор превратится в двух стрелочный указатель. Перемещая его, с нажатой левой клавишей мыши можно изменять размеры столбца.
Определим теперь частоту (fi), равную отношению количества
слов в группе- ni к общему числу слов- N, т.е.
fi = ni / N,
где N=17788.
Значения частоты для различных начальных слов разместим в ячейках D2:D31.
Для этого выделим ячейку D2 и введем в неё формулу: =C2/$F$2. В нижнем правом углу рамки этой ячейки находится небольшой квадратик, именуемый маркером заполнения. Подведём курсор к маркеру заполнения. Курсор превратится в чёрный крестик. Нажмём левую клавишу мыши и, не отпуская её, протащим маркер до конца ячейки D31, затем отпустим. Ячейки D2:D31 будут заполнены значениями частоты. В ячейку D1 поместим соответствующий заголовок (Фиг.3.8)
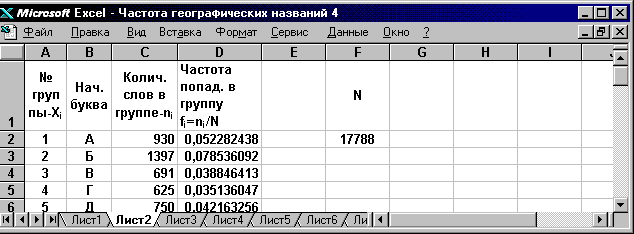
Фиг. 3.8
Построим теперь гистограмму статистического ряда.
Для этого выполним следующие действия:
-
Выделим ряд значений частоты f (ячейки F1:F32).
-
Щелкнем по кнопке МАСТЕР ДИАГРАММ. При этом курсор превращается в крестик, сопровождаемый значком гистограммы. Поместим его в верхний левый угол той области, в которой будет расположена гистограмма.
-
После этого вызывается МАСТЕР ДИАГРАММ (ШАГ 1). Поскольку нужный диапазон уже определен щелкнем по кнопке Далее.
-
На экране появляется диалоговое окно (ШАГ 2), предлагающее 15 вариантов диаграмм. Сделаем щелчок на диаграмме ГИСТОГРАММА, затем на кнопке ДАЛЕЕ.
-
На экране появляется диалоговое окно (ШАГ 3), предлагающее 10 вариантов выбранной диаграммы. Щелкнем на гистограмме 8, затем на кнопке ДАЛЕЕ.
-
На экране появляется диалоговое окно (ШАГ 4), в котором изображен выбранный график. Щелкнем по кнопке ДАЛЕЕ.
-
На экране появляется диалоговое окно (ШАГ 5). Это последний шаг. На этом шаге выберем ЛЕГЕНДУ, т. е. условное обозначение на графике рядов данных. Затем в окне НАЗВАНИЕ ДИАГРАММЫ введем с клавиатуры ГИСТОГРАММА. В окнах НАЗВАНИЕ ПО ОСИ введем названия осей X и f. Теперь щелкнем по кнопке ГОТОВО.
В полученную гистограмму можно вносить изменения. Для этого двойным щелчком на ней выделим её, затем осуществляем щелчок правой кнопкой мыши по той области гистограммы, в которую нужно внести изменения. В появившемся контекстном меню следует выбрать подходящую команду.
Сначала изменим значения оси Х. Щёлкнем правой кнопкой мыши по оси Х. В появившемся контекстном меню следует выбрать команду ФОРМАТ РЯДА... В появившемся диалоговом окне ФОРМАТИРОВАНИЕ РЯДА ДАННЫХ щёлкнем по вкладке ЗНАЧЕНИЯ Х. Затем щёлкнем по окошку ЗНАЧЕНИЯ Х. После этого в нём появится мигающий курсор. Для выбора ячеек, содержащих значения Х необходимо щёлкнуть по листу Excel, в котором находятся эти ячейки. С помощью мыши выделим диапазон значений для оси Х, т. е. ячейки
D2:D32. Он будет окаймлен пунктирной мерцающей рамкой. Затем щелкнем по кнопке ГОТОВО. Для оси Х будут введены новые значения от А до Я.
Теперь эти новые значения поместим над столбиками гистограммы.
Для этого щёлкнем правой кнопкой мыши по оси Х. В появившемся контекстном меню следует выбрать команду ФОРМАТ РЯДА... В появившемся диалоговом окне ФОРМАТИРОВАНИЕ РЯДА ДАННЫХ щёлкнем по вкладке МЕТКИ. В графе ВЫВЕСТИ В КАЧЕСТВЕ МЕТКИ щёлкнем левой кнопкой мыши по отметке НАЗВАНИЕ КАТЕГОРИИ. Значения букв появятся над столбиками гистограммы (Фиг. 3.9). Для внедрения гистограммы в документ Excel необходимо щёлкнуть левой кнопкой мыши вне редактируемой гистограммы.
Для
окончательного редактирования нужно
убрать буквы под осью Х и заменить их
цифрами. При этом необходимо использовать
панель инструментов РИСОВАНИЕ,
которую можно вызвать с помощью
соответствующей кнопки. На панели
РИСОВАНИЕ
нужно нажать кнопку НАДПИСЬ
 и
с помощью мыши развернуть пунктирную
рамку на месте букв, помещенных под осью
Х. В полученной рамке напечатать
необходимый ряд цифр (Фиг. 3.9).
и
с помощью мыши развернуть пунктирную
рамку на месте букв, помещенных под осью
Х. В полученной рамке напечатать
необходимый ряд цифр (Фиг. 3.9).
Полученная гистограмма соответствует алфавитному порядку расположения букв. В ряде случаев алфавитный порядок непригоден для решения некоторых вопросов анализа и возникает задача определения другого, соответствующего решаемой проблеме, порядка расположения букв. Следует отметить, что общее число всех возможных порядков равно n!, где n- число букв алфавита, в данном случае равное 30.
Определим ряд новых порядков расположения букв, исходя из соответствующих критериев.
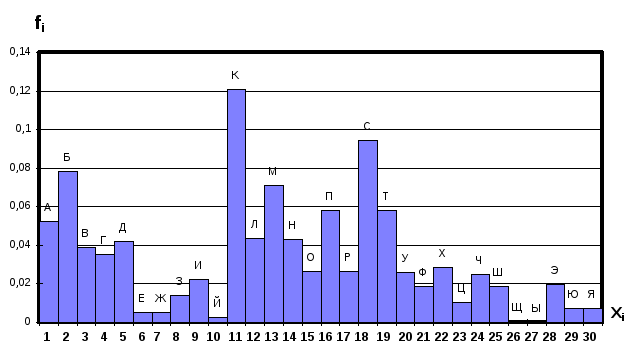
Фиг. 3.9
В качестве первого критерия установим необходимость возрастания численного значения признака с увеличением номера группы.
Для этого необходимо проранжировать таблицу 1, т.е. буквы расположить не в алфавитном порядке, а в порядке возрастания величины признака.
С этой целью необходимо выполнить следующие действия:
-
Выделим столбцы A, B, C, D. Для этого поместим курсор на заголовок столбца А, нажмем ее левую клавишу и, не отпуская ее, протащим курсор от А до D. Затем в D отпустим клавишу мыши.
-
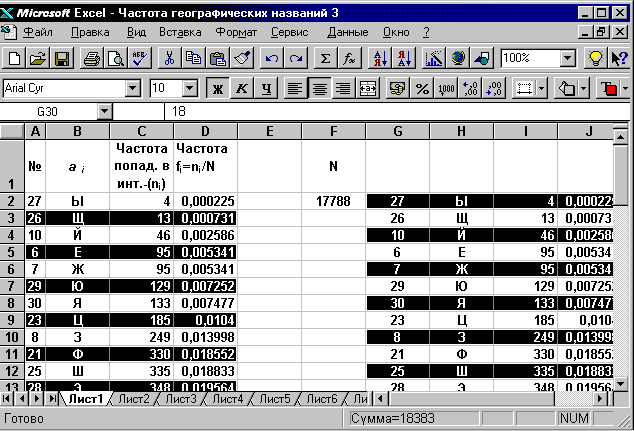
Выполним команды меню: ДАННЫЕ- СОРТИРОВКА . На экране появляется диалоговое окно, подобное показанному на фиг. 3.10. Щелкнув на кнопке со стрелкой в группе СОРТИРОВАТЬ ПО, получим список полей. Выберем в этом списке поле ЧАСТОТА и щелкнем по кнопке ОК.
-
В итоге получим список букв, ранжированный по величине ЧАСТОТА ( Фиг.. 3.10)
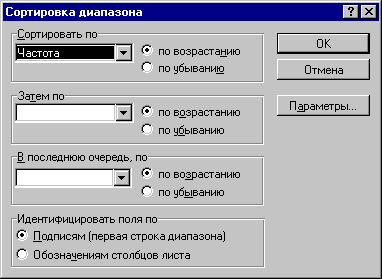
Фиг. 3.10
Новый порядок расположения букв изображен на фиг. 3.11.
Фиг. 3.11
Для нового порядка расположения букв гистограмма получается автоматически (Фиг. 3.12).

Фиг. 3.12
Этот порядок обозначим, как номер 2, в отличие от алфавитного, который обозначим номером 1.
Порядок 3 определим, исходя из одномодального распределения частоты. Для такого порядка должен иметь место максимум частоты, приходящийся на середину буквенного интервала. С этой целью преобразуем таблицу, соответствующую Фиг.3.11 следующим образом.
Выделим в столбцах A,B,C,D строки с номера 1 по номер 31. Затем при нажатой клавише Ctrl подведем курсор к границе выделенного участка и нажмем левую клавишу мыши. Рядом с курсором появится знак +. Не отпуская нажатых клавиш, переместим выделенную часть таблицы в ячейки, начиная с номера G2 и отпустим обе клавиши. В ячейках G2:J31 разместится второй экземпляр таблицы.
Теперь в первом экземпляре таблицы выделим нечетные, а во втором- четные строки (Фиг.3.13). Для этого при выделении необходимо держать нажатой клавишу Ctrl.
После этого следует нажать клавишу Delete. Выделенные строки исчезнут. Затем необходимо выделить снова первый экземпляр таблицы и выполнить команды меню: ДАННЫЕ- СОРТИРОВКА... На экране появляется диалоговое окно, подобное показанному на фиг.3.10. Щелкнув на кнопке со стрелкой в группе СОРТИРОВАТЬ ПО, получим список полей. Выберем в этом списке поле ЧАСТОТА и щелкнем по кнопке ОК. В результате этой операции пустые строки исчезнут и заполнение таблицы будет сплошным (Фиг. 3.13).
Фиг. 3.13
Затем необходимо выделить второй экземпляр таблицы и выполнить команды меню: ДАННЫЕ- СОРТИРОВКА... На экране появляется диалоговое окно, подобное показанному на рис. 3.10 Щелкнув на кнопке со стрелкой в группе СОРТИРОВАТЬ ПО, получим список полей. Выберем в этом списке поле СТОЛБЕЦ J, ПО УБЫВАНИЮ и щелкнем по кнопке ОК. В результате этой операции пустые строки исчезнут и заполнение таблицы будет сплошным (Фиг. 3.14).
Фиг. 3.14
Теперь необходимо
второй экземпляр таблицы расположить
вплотную под первым. Для этого второй
экземпляр таблицы нужно выделить и
перетащить с помощью мыши. После этой
процедуры автоматически создается
гистограмма, соответствующая новому
порядку букв (Фиг. 3.15). 

 Определим
теперь среднее значение Х
полученного
распределения.
Определим
теперь среднее значение Х
полученного
распределения.
Для этого воспользуемся следующей формулой:
![]() ( 3.6 ),
( 3.6 ),
где Х i - номер группы, f i - соответствующая этому номеру частота,
n - число групп, равное 30.


Фиг. 3.15
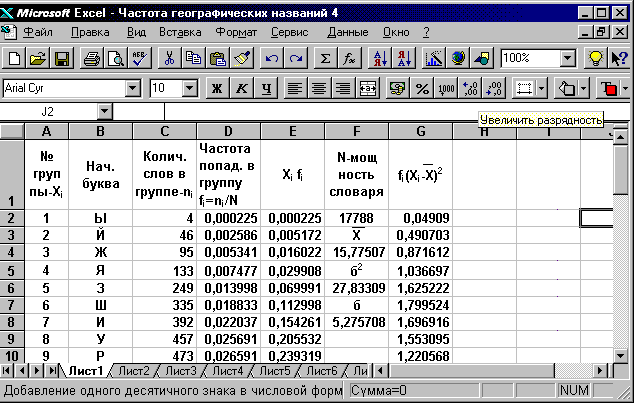
Для реализации формулы (3.6) в ячейку E2 введем =A2*D2 и нажмем клавишу Enter. В нижнем правом углу рамки этой ячейки находится небольшой квадратик, именуемый маркером заполнения. Подведём курсор к маркеру заполнения. Курсор превратится в чёрный крестик. Нажмём левую клавишу мыши и, не отпуская её, протащим маркер до конца ячейки E31, затем отпустим. Ячейки E2:E31 будут заполнены значениями произведений Xi fi. В ячейку E1 поместим соответствующий заголовок
(Фиг.3.16).
Теперь определим среднее значение Х полученного распределения. Для этого выделим ячейку, в которую поместим результат, например, ячейку F4. Затем щелкнем по кнопке МАСТЕР ФУНКЦИЙ. Он отобразит список функций в графе КАТЕГОРИЯ. Выберем в нем МАТЕМАТИЧЕСКИЕ. В графе ФУНКИЯ выберем СУММ и нажмем кнопку ДАЛЕЕ. На экране отобразится диалоговое окно второго из двух шагов выбора функции СУММ. Поставим курсор в поле ЧИСЛО 1.С помощью мыши выделим диапазон значений для функции СУММ, т. е. ячейки E2:E31. Он будет окаймлен пунктирной мерцающей рамкой. Затем щелкнем по кнопке ГОТОВО. Результат появится в ячейке F4. ( Фиг. 3.16 ). В ячейку F3 введем соответствующий заголовок (Фиг. 3.16 ).
Стандартное отклонение б(Х) определяется следующим образом:
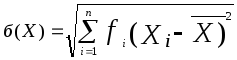 (3.7)
(3.7)
Для реализации формулы (2) в ячейку G2 введем =D2*(A2-$F$4)^2 и нажмем клавишу Enter. В нижнем правом углу рамки этой ячейки находится небольшой квадратик, именуемый маркером заполнения. Подведём курсор к маркеру заполнения. Курсор превратится в чёрный крестик. Нажмём левую клавишу мыши и, не отпуская её, протащим маркер до конца ячейки G31, затем отпустим. Ячейки G2:G31 будут заполнены значениями произведений для формулы (3.7). В ячейку G1 поместим соответствующий заголовок (См. Фиг.3.16).
Теперь определим квадрат cтандартного отклонения б(Х) полученного распределения. Для этого выделим ячейку, в которую поместим результат, например, ячейку F6. Затем щелкнем по кнопке МАСТЕР ФУНКЦИЙ. Он отобразит список функций в графе КАТЕГОРИЯ . Выберем в нем МАТЕМАТИЧЕСКИЕ. В графе ФУНКЦИЯ выберем СУММ и нажмем кнопку ДАЛЕЕ. На экране отобразится диалоговое окно второго из двух шагов выбора функции СУММ. Поставим курсор в поле ЧИСЛО1. С помощью мыши выделим диапазон значений для функции СУММ, т. е. ячейки G2:G31. Он будет окаймлен пунктирной мерцающей рамкой. Затем щелкнем по кнопке ГОТОВО. Результат- б2 появится в ячейке F6. ( Фиг. 3.16 ). В ячейку F5 введем соответствующий заголовок ( Фиг. 3.16 ).
Для определения б выделим ячейку F8 и введем в нее формулу =F5^,5. После нажатия клавиши Enter в ячейке F8 появится результат.
Фиг. 3.16
В полученной гистограмме можно произвести также другие изменения. Два самых крупных объекта гистограммы это фон, или область диаграммы, и пространство между двумя осями, или область построения.
Можно изменять цвета, узоры и рамки областей. Позиционируя курсор между осями, двойным щелчком вы инициируете форматирование области построения; то же самое, но вне осей, обеспечивает форматирование области гистограммы. Двойным щелчком по столбикам гистограммы можно изменить их раскраску.

 Теперь
отметим на гистограмме значения среднего-
Х и стандартного
отклонения-
б. Для этого,
нажав на кнопку РИСОВАНИЕ
вызовем
панель инструментов РИСОВАНИЕ. Щёлкнем
по клавише ЛИНИЯ
. Курсор
превратится в крестик. Этот крестик
установим в точку на оси Х, соответствующую
Х, нажмём SHIFT
и левую клавишу мыши и протащим курсор,
не отпуская клавиш, до верхней рамки
гистограммы, где отпустим клавиши. С
помощью двойного щелчка по проведённой
линии можно изменить её вид, цвет и
толщину.
Теперь
отметим на гистограмме значения среднего-
Х и стандартного
отклонения-
б. Для этого,
нажав на кнопку РИСОВАНИЕ
вызовем
панель инструментов РИСОВАНИЕ. Щёлкнем
по клавише ЛИНИЯ
. Курсор
превратится в крестик. Этот крестик
установим в точку на оси Х, соответствующую
Х, нажмём SHIFT
и левую клавишу мыши и протащим курсор,
не отпуская клавиш, до верхней рамки
гистограммы, где отпустим клавиши. С
помощью двойного щелчка по проведённой
линии можно изменить её вид, цвет и
толщину.

 Точно таким же способом проведём линию
через значение Х=Х+б. Затем при нажатой
клавише CTRL
перетащим данную линию к значению
Точно таким же способом проведём линию
через значение Х=Х+б. Затем при нажатой
клавише CTRL
перетащим данную линию к значению
Х =Х-
б.
=Х-
б.
Для размещения на гистограмме дополнительных надписей ( Х и б ) необходимо на панели инструментов РИСОВАНИЕ щёлкнуть по клавише НАДПИСЬ
. Курсор превратится в крестик. С помощью этого крестика следует в нужном месте гистограммы нарисовать прямоугольник, в который вносится дополнительная надпись. С помощью двойного щелчка по дополнительной надписи её можно отредактировать, в том числе убрать рамку, т. е. прямоугольник.
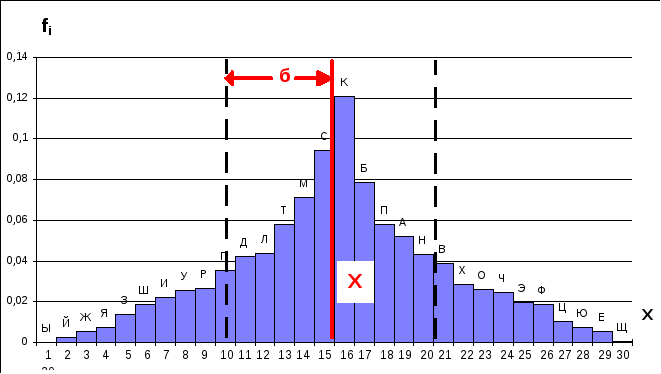
Рассматривая построенную гистограмму, можно сделать вывод, что среднее является характеристикой расположения полученного распределения и представляет собой центральную точку его распределения. Величина среднего, равного 15,8, показывает, что это значение находится в 15-ой группе, соответствующей букве С. Если бы распределение было симметричным, то среднее совпало бы с модой распределения, т.е. с буквой А. По обе стороны от этого значения группируются остальные значения признака.
Стандартное отклонение- б является параметром, показывающим, насколько широко разбросаны значения признака по каждую сторону от типичного значения. Параметр такого рода называется характеристикой рассеяния или, иногда, характеристикой сосредоточения.
Преобразуем теперь полученную таблицу Excel таким образом, чтобы в начале ее следовали гласные, а затем согласные. При этом порядок следования гласных и согласных не должен меняться. Для этого строки, содержащие гласные и включающие ячейки A-E, необходимо выделить и переместить в другое место таблицы, например, начиная с ячейки H2.

Оставшиеся строки с согласными буквами необходимо сдвинуть вниз вплотную друг к другу , а на освободившееся место переместить строки с гласными буквами. Теперь необходимо перенумеровать столбец А по порядку следования строк. Для этого следует выделить столбец А и нажать клавишу Delete. Порядок выполнения нумерации описан выше.(Фиг. 3.18).
После этой процедуры автоматически создается гистограмма, соответствующая новому порядку букв (Фиг. 3.19).
Определим теперь характеристики нового распределения отдельно для гласных и согласных. Так как мы имеем дело с совместным распределением, то формулы (3.6) и (3.7) необходимо пронормировать. Тогда средние для гласных и согласных будут иметь вид (3.8) и (3.9).
 (3.8)
(3.8)
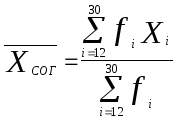 (3.9)
(3.9)
Стандартные отклонения для гласных и согласных будут иметь вид (3.10) и (3.11)
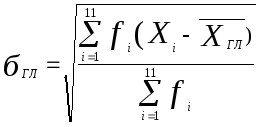 (3.10)
(3.10)
 (3.11)
(3.11)
Теперь необходимо, используя полученные формулы, получить численные значения данных характеристик.
Прежде всего очистим ячейки F3-F8. Затем определим среднее значение Х полученного распределения для гласных. Для этого выделим ячейку, в которую поместим первый промежуточный результат, например, ячейку F10. Затем щелкнем по кнопке МАСТЕР ФУНКЦИЙ. Он отобразит список функций в графе КАТЕГОРИЯ. Выберем в нем МАТЕМАТИЧЕСКИЕ. В графе ФУНКЦИЯ выберем СУММ и нажмем кнопку ДАЛЕЕ. На экране отобразится диалоговое окно второго из двух шагов выбора функции СУММ. Поставим курсор в поле ЧИСЛО 1.С помощью мыши выделим диапазон значений для функции СУММ, т. е. ячейки E2:E11. Он будет окаймлен пунктирной мерцающей рамкой. Затем щелкнем по кнопке ГОТОВО. Результат появится в ячейке F10. ( Фиг. 3.19). В ячейку F9 введем соответствующий заголовок, используя редактор формул Equation из меню ВСТАВКА- ОБЪЕКТ- EQUATIN ( Фиг. 3.19).
Такую же процедуру проделаем для ячеек D2:D11. Второй промежуточный результат и соответствующий заголовок поместим в ячейки F8 и F7.
Теперь найдем среднее для гласных. Для этого выделим ячейку, в которую поместим окончательный результат, например, ячейку F4. Затем щелкнем по клавише = , последовательно щелкнем ячейку F10, клавишу / , ячейку F8 и нажмем клавишу ENTER. В ячейку F3 поместим соответствующий заголовок.
Аналогичным образом определим среднее для согласных. Разница заключается лишь в том, что вместо ячеек E2:E11 и D2:D11 используются ячейки E12:E31 и D12:D31.
Промежуточные результаты поместим в ячейки F11:F14, а окончательный результат, т.е. среднее для согласных, в ячейки F5:F6.
Перейдем теперь к определению стандартного отклонения для гласных и согласных. Для этого выделим ячейку, в которую поместим первый промежуточный результат, например, ячейку F16. Затем щелкнем по кнопке МАСТЕР ФУНКЦИЙ. Он отобразит список функций в графе КАТЕГОРИЯ. Выберем в нем МАТЕМАТИЧЕСКИЕ. В графе ФУНКЦИЯ выберем СУММ и нажмем кнопку ДАЛЕЕ. На экране отобразится диалоговое окно второго из двух шагов выбора функции СУММ. Поставим курсор в поле ЧИСЛО 1.С помощью мыши выделим диапазон значений для функции СУММ, т. е. ячейки G2:G11. Он будет окаймлен пунктирной мерцающей рамкой. Затем щелкнем по кнопке ГОТОВО. Результат появится в ячейке F10. ( Фиг. 3.19). В ячейку F9 введем соответствующий заголовок, используя редактор формул Equation из меню ВСТАВКА- ОБЪЕКТ- EQUATIN ( Фиг. 3.19).
Фиг. 3.19
Теперь найдем квадрат стандартного отклонения для гласных. Для этого выделим ячейку, в которую поместим результат, например, ячейку F18. Затем щелкнем по клавише = , последовательно щелкнем ячейку F16, клавишу / , ячейку F8 и нажмем клавишу Enter. В ячейку F17 поместим соответствующий заголовок.
Для определения стандартного отклонения для гласных выделим ячейку, в которую поместим результат, например, ячейку F20. Затем щелкнем по клавише = , последовательно щелкнем ячейку F18, клавишу ^ , цифру 0,5 и нажмем клавишу Enter. В ячейку F19 поместим соответствующий заголовок.
Аналогичным образом определим стандартное отклонение для согласных. Разница заключается лишь в том, что вместо ячеек G2:G11 используются ячейки G12:G31.
Промежуточные результаты поместим в ячейки F21:F24, а окончательный результат, т.е. стандартное отклонение для согласных, в ячейки F25:F26.
Рисование соответствующих линий на полученной диаграмме осуществляется по методике, которая описана выше.
В теории нормальных алгоритмов всякое слово естественного языка признается математическим объектом, который характеризуется длиной, начальной и конечной буквами. При проведении частотного анализа слов, морфем и частей предложения мало кто из исследователей обращает внимания на такой признак слова как его начальная буква. По этому признаку составлены словари естественного языка, но в них буквы алфавита расположены в определенной последовательности, нумерация которой числами не единственна.
В данной работе производится средствами информационных технологий частотный анализ слов по начальной букве. Объектами языкознания для исследования принимаются топонимика как дисциплина, изучающая географические названия; ономастика, изучающая происхождение имен и фамилий, а также пласт слов, традиционно включаемый в орфографические словари.
Нами зафиксировано топонимов N= 17788 (Выборка-1 ), древнерусских фамилий - N= 8097 ( Выборка-2 ) и числоN=96318 слов традиционных для орфографического словаря ( Выборка-3).
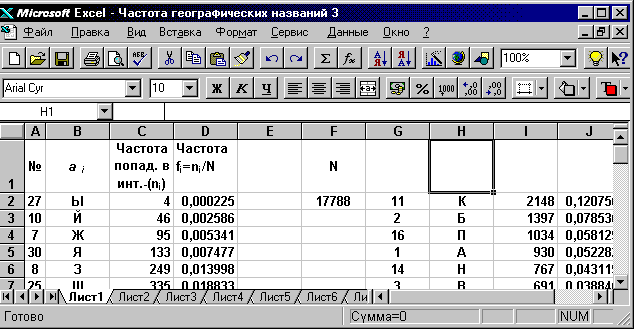
В каждой из выборок подсчитано число слов ni, начинающихся с одной и той же буквы ai. Буквы ai русского алфавита представляют элементы некоторого счетного множества A={ ai}, которые можно пронумеровать числами натурального ряда xi. В таблице 3.4 буквы ai пронумерованы числами xi так как это принято для букв русского алфавита.
Таблица 3.4. Выборка слов по начальной букве алфавита
-
xi
Начальная буква ai
Число слов ni на данную букву алфавита
Выборка-1
N1=17788
Выборка -2 N2=8097
Выборка-3 N3=96318
1
А
930
136
3148
2
Б
1397
880
3975
3
В
691
344
6859
4
Г
625
374
2736
5
Д
750
295
3798
6
Е
95
83
227
7
Ё
0
0
21
8
Ж
95
141
647
9
З
249
202
4197
10
И
392
77
2328
11
Й
46
0
23
12
К
2148
1006
5795
13
Л
776
338
1945
14
М
1268
470
3950
15
Н
767
248
5263
16
О
467
310
6729
17
П
1034
695
17817
18
Р
473
260
4828
19
С
1678
748
8989
20
Т
1029
412
3420
21
У
457
75
2290
22
Ф
330
25
1558
23
Х
504
165
10000
24
Ц
185
36
539
25
Ч
440
259
1090
26
Ш
335
369
1307
27
Щ
13
66
163
28
Ы
4
0
0
29
Ь
0
0
0
30
Э
348
0
1230
31
Ю
129
24
125
32
Я
133
59
321
Определим частоту появления слова на выбранную начальную букву в рассматриваемой выборке по общеизвестной формуле
fi = ni / N, (3.12)
где N - полное число слов выборки.
Возможности пакета Excel-7 позволяют в автоматическом режиме производить расчеты по (3.12) и строить зависимости fi от статистического признака xi.
Результат такой автоматической обработки представлен на фиг.3.20, где расположение букв ai по позициям xi соответствует общепринятому порядку следования букв русского алфавита.
Так как множество A={ ai} (i=1, 2, ..., 30) дискретно, то на фиг.3.20 интервал между числами xi нельзя устремлять к нулю, и каждое из чисел xi следует приписывать середине соответствующего интервала числовой оси х. Этой особенностью отличается данная гистограмма, от обычных гистограмм математической статистики, в которых возможен переход от дискретной функции к непрерывной.
Дискретная функция fi, изображенная на фиг.3.20 не монотонна, поэтому ее анализ математическими средствами затруднен. Однако из комбинаторики известно, что число размещений из тридцати элементов по тридцати позициям равно тридцати факториал, который представляет довольно большое число. Это позволяет значения fi , соответствующие начальной букве ai переставлять в каком-либо порядке на числовой оси х.
Порядок расположения fi на оси х можно выбрать, например, так чтобы функция fi(xi) была монотонно возрастающая. В математической статистике такая операция называется ранжированием статистической величины по абсолютной величине. Результат операции ранжирования, выполненной в пакете Excel-7 с одновременной перенумерацией букв алфавита, представлен на фиг.3.21. Алгоритм выполнения этой операции описан в работе 3.2.
Дискретная функция на этом рисунке суть монотонно возрастающая и с ее помощью легко определяются подмножества букв русского алфавита, топонимы которых встречаются либо наиболее часто, либо наиболее редко.
Монотонно возрастающую гистограмму легко перестроить в симметричную относительно наибольшей частоты. Для этого необходимо значение fi равное максимальной частоте поместить в среднюю позицию на числовой оси. Затем частоты в нечетных позициях располагать слева от максимальной в порядке убывания, а частоты в четных позициях располагать таким же образом справа. Этот алгоритм легко реализовывается в пакете Excel-7 и результат вычислений представляет фиг.3.22 (См. 3.2) В математической статистике такие гистограммы называются одномодальными.
Одномодальная гистограмма характеризуется математическим ожиданием
![]() (
3.13),
(
3.13),
и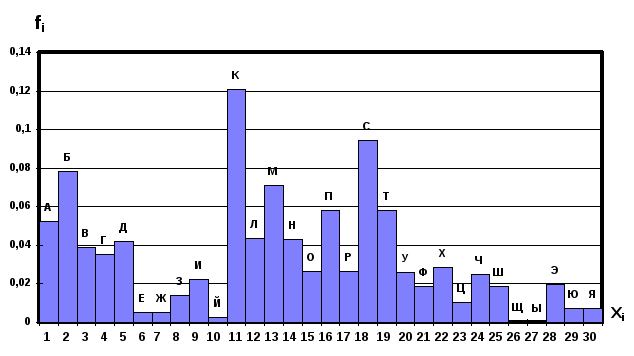 средним квадратичным отклонением
средним квадратичным отклонением
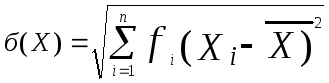 (3.14)
(3.14)
Фиг. 3.20.
Гистограмма частоты
географических названий (по алфавиту)

Фиг. 3.21. Гистограмма частоты географических названий
по возрастанию частоты
Таблица 3.5. Статистические параметры выборок
|
Параметры |
Выборка-1 |
Выборка-2 |
Выборка-3 |
|
|
15,77 |
16,75 |
16,71 |
|
|
5,26 |
4,80 |
4,68 |
|
xгл |
6,03 |
6,94 |
7.17 |
|
|
1,69 |
1,43 |
1,28 |
|
хсог |
20,36 |
21,40 |
20,99 |
|
бсог |
3,85 |
3,90 |
3,54 |
|
н |
4,68 |
4,25 |
4,54 |
|
нгл |
2,68 |
2.42 |
2,32 |
|
нсог |
3,96 |
3,78 |
3,77 |
 x
x б
б бгл
бгл
 Значения
х
и б
для ‘’ Выборки - 1 ‘’ получены при n=30
формулах (3.13)и (3.14) и помещены в таблицу
3.5. (См. раб. 3.1) Число х=15,77 отложено на
числовой оси х (рис.3) и оно оказалось
близко к числу хi=16,
которое определяет номер позиции
максимальной частоты . Число хi=16
называют модой
статистической величины fi.
Значения
х
и б
для ‘’ Выборки - 1 ‘’ получены при n=30
формулах (3.13)и (3.14) и помещены в таблицу
3.5. (См. раб. 3.1) Число х=15,77 отложено на
числовой оси х (рис.3) и оно оказалось
близко к числу хi=16,
которое определяет номер позиции
максимальной частоты . Число хi=16
называют модой
статистической величины fi.
На фиг.3.22 влево и вправо от точки х отложена величина б=5,26, которая характеризует поведение статистической величины внутри интервала 2б.
При частотном анализе слов по начальной букве интересуются начальной буквой, попадающей в позицию, номер которой совпадает с модой, и числом букв внутри интервала 2б.
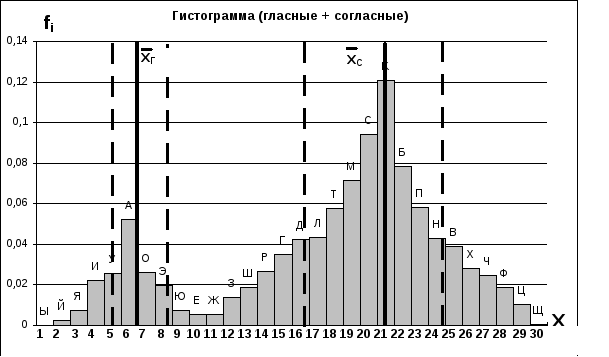
Для дальнейшего анализа интересно одномодальную гистограмму перестроить в двухмодальную, для чего необходимо производить размещение гласных и согласных букв по позициям раздельно. Этот процесс следует начинать с определения мод распределений гласных и согласных букв, а затем по указанному выше алгоритму строить симметричные гистограммы для гласных и согласных. Построенные таким образом гистограммы с помощью пакета Excel-7 и помещенные на одной числовой оси представляют одну двух модальную гистограмму (фиг.3.23). (См. Раб. 3.2)На фиг.3.23 первая мода определяет гласную букву, на которую начинается максимальное число слов данной выборки, а вторая- согласную. Порядок расположения указанных мод на числовой оси произволен.

Фиг. 3.22 Одномодальная гистограмма частоты географических названий
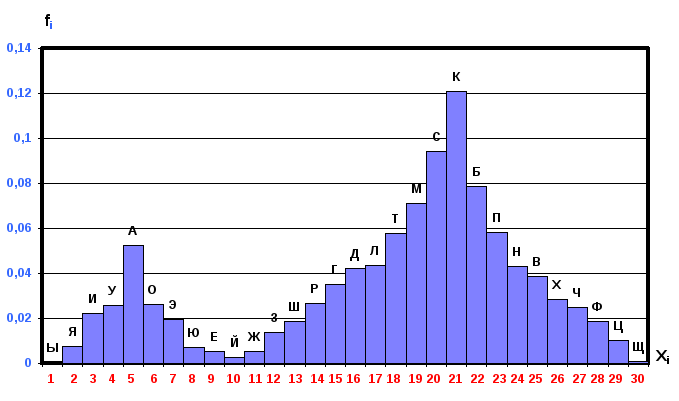
Фиг. 3.23. Двухмодальная гистограмма частоты географических названий
Д
 ля
подсчета числовых параметров двухмодальной
гистограммы формулы (3.13) и (3.14) необходимо
перенумеровать. Тогда математические
ожидания для гласных х гл.
и согласных хсог.
необходимо вычислять по формулам
ля
подсчета числовых параметров двухмодальной
гистограммы формулы (3.13) и (3.14) необходимо
перенумеровать. Тогда математические
ожидания для гласных х гл.
и согласных хсог.
необходимо вычислять по формулам
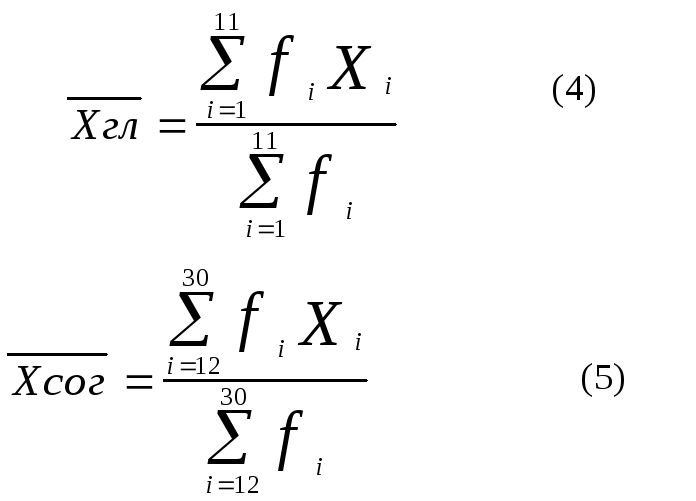
а средние квадратичные отклонения по следующим соотношениям
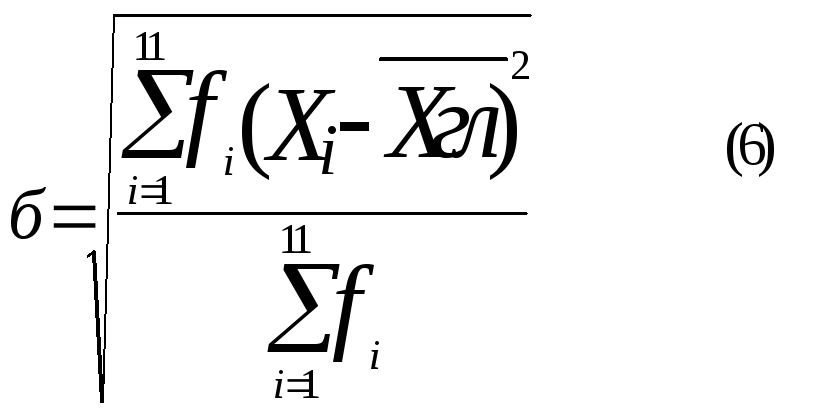

Результаты расчетов по (4) - (7) представлены в таблице 3.5 (См. раб. 3.1). На ниже следующих рисунках и в таблице 3.5 представлены результаты обработки выборок N2 и N3 из таблицы 3.4 по указанной методике с помощью пакета Excel 7 . Из анализа таблицы 3.5 следует ,что статистические параметры всех трех выборок близки друг к другу . Aнализ же одномодальных гистограмм показывает ,что все три выборки имеют ряд общих букв ,попадающих в интервал 2б
.
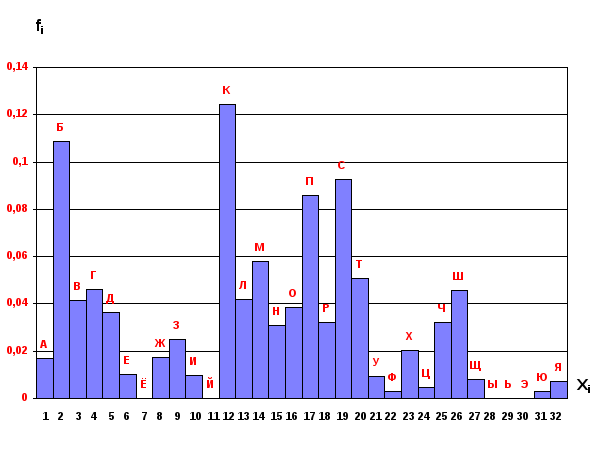
Фиг. 3.24. Гистограмма древнерусских фамилий.
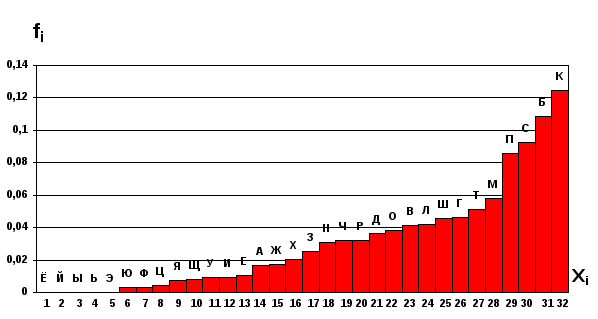
Фиг. 3.25. Ранжированная гистограмма древнерусских фамилий.
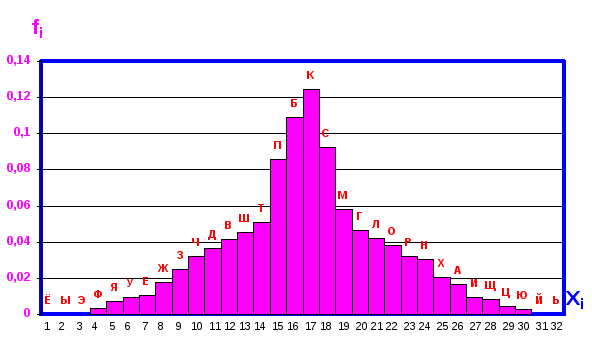
Фиг. 3.26. Одномодальная гистограмма древнерусских фамилий.
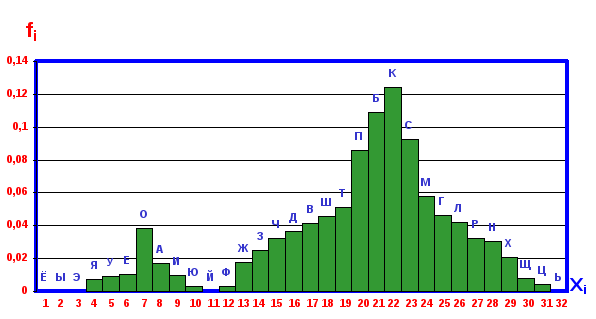
Фиг. 3.27. Двухмодальная гистограмма древнерусских фамилий.
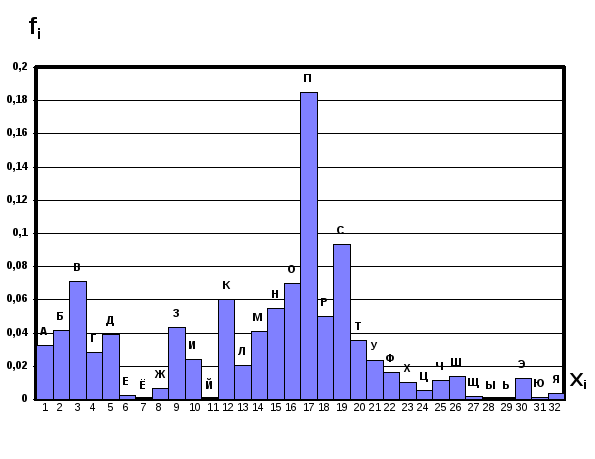
Фиг. 3.28. Гистограмма орфографического словаря.
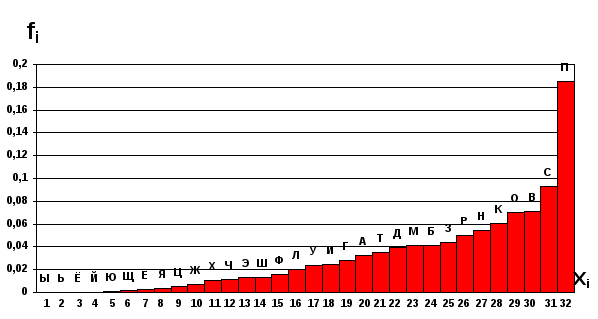
Фиг. 3.29. Ранжированная гистограмма орфографического словаря.
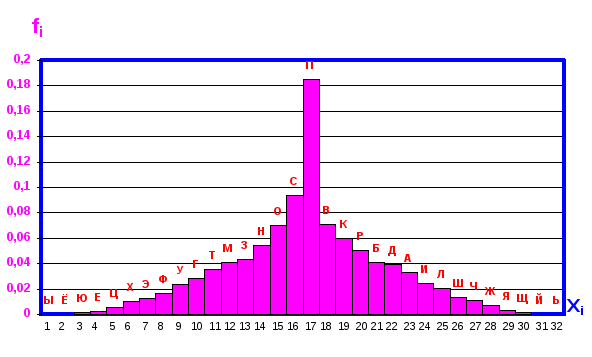
Фиг. 3.30. Одномодальная гистограмма орфографического словаря.
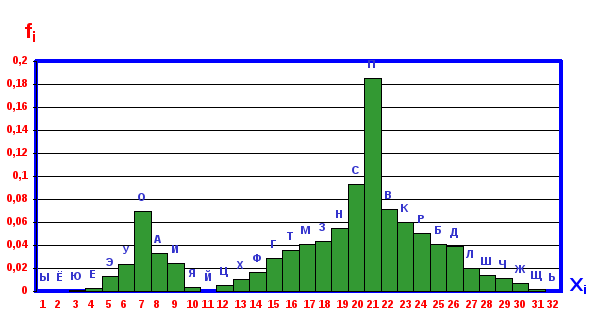
Фиг. 3.31. Двухмодальная гистограмма орфографического словаря.
Для определения количественной меры информации существует общеизвестная формула
m=log2N, (3.19)
связывающая длину слова m с количеством слов этой длины, составленных из букв двоичного алфавита. Американский исследователь Л. Хартли в 1928 г. отождествил максимальное количество информацииН с длиной слова m , т.е.
Н=log2N (3.20)
Впоследствии формула Л. Хартли (3.20) была принята за основу при установлении формата памяти вычислительных машин.
В рассматриваемом случае N слов -это объем выборки. Естественно, что выборка состоит из нескольких групп слов. Предположим, что в пределах каждой группы слова имеют одинаковую длину. Если через ni обозначить объем каждой группы слов, то
N = ni (3.21)
По формуле (3.19) вычислим длину слова из группы n1 .
m1 = log2n1 (3.22)
Затем вычислим разности левых и правых частей формул (3.19) и (3.22) , после чего будем иметь
m-m1 = H1=log2(N/n1) (3.23)
Из (3.23) следует , что Н1 суть длина не идентифицированных слов. Аналогично можно составить
H2= log2(N/n2)..., Hk= log2(N/nk) (3.24)
Составим среднюю статистическую величину
H=(1/N)niHi , (3.25)
которая с учетом (3.24) и (3.25) переписывается так
H=(ni/N) log2(N/ni) (3.26)
Если в каждой группе число слов равно единице (ni=1) и число групп k равно N, то формула (3.26)переходит в формулу(3.20).В противном случае формула(3.26) с учетом (3.12) принимает следующий вид.
H=-fi log2fi (3.27)
Эта формула известна как формула Шенона для вычисления количества информации в битах .Результаты расчетов по(3.27) для изучаемых выборок представлены в таблице 3.5. Следует заметить, что при вычислении Нгл и Нсог необходимо производить дополнительную нормировку по частотам.
Из таблицы 3.5 следует близость числовых значений б и H. Совпадение указанных параметров тем лучше, чем лучше одномодальная гистограмма напоминает кривую нормального распределения.