

Описательная статистика: Числовые характеристики случайной величины
Медиана – это значение случайной величины, которое делит распределение пополам: половина значений будет больше медианы, половина – не больше.
Процентиль – значение случайной величины, которое делит распределение на соответствующие доли (25%, 75% и т. д.)
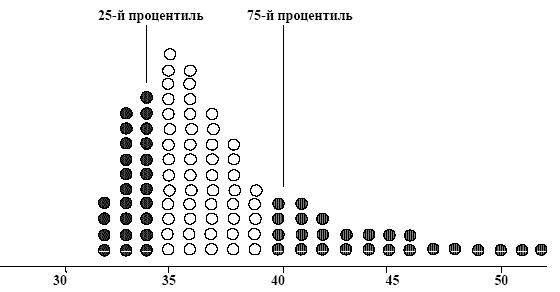

Процентной точкой порядка α (α – процентной точкой) распределения называется такое возможное значение xα этой случайной величины, для которого вероятность события X > xα равна заданной вероятности α
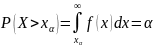
Квантилем порядка p называется такое возможное значение xp этой случайной величины, для которого вероятность события X < xp равна заданной вероятности p
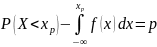
А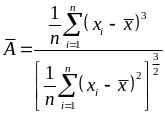 симметрия
симметрия
Э ксцесс
ксцесс
Мода – это наиболее часто встречающееся значение случайной величины
В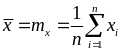 ыборочное
среднее, представляющее собой оценку
математического ожидания генеральной
совокупности:
ыборочное
среднее, представляющее собой оценку
математического ожидания генеральной
совокупности:
В ыборочная
дисперсия, служащая несмещенной оценкой
дисперсии генеральной совокупности:
ыборочная
дисперсия, служащая несмещенной оценкой
дисперсии генеральной совокупности:
Выборочное
среднеквадратическое (стандартное)
отклонение:
Описательная статистика: Точность выборочных оценок
С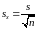 тандартная
ошибка среднего
тандартная
ошибка среднего
Анализ резко выделяющихся наблюдений
Речь пойдет об анализе наблюдений, которые сильно отклоняются от центра распределения. Иногда такие большие отклонения возникают в результате случайного просчета, неправильного считывания показаний измерительного прибора, т.е. в результате допущенной грубой ошибки. Иногда большие отклонения отражают более тонкие моменты, такие как несоответствие в отдельных точках используемой математической модели, незамеченное исследователем изменение условий эксперимента и т.п.
В любом случае с математической точки зрения речь идет о выявлении наблюдений, значение которых не согласуется с распределением основной массы данных. Выявление таких наблюдений позволяет обычно еще раз проверить условия регистрации и тем самым выявить и устранить ошибку. Если же ошибку устранить
не удается, то возможно эти наблюдения следует просто исключить из данных как нетипичные (неправдоподобные).
Рассматриваемая задача анализа разделяется на два этапа:1) выявление “подозрительных” наблюдений и 2) проверка статистической значимости их отличия от основной массы данных.
Сложность анализа резко выделяющихся (аномальных) наблюдений заключается в, казалось бы, парадоксальном выводе: чем больше объем выборки, тем с большей вероятностью следует ожидать резких выбросов в наблюдениях.
Существует несколько различных критериев для идентификации резко выделяющихся наблюдений, но все они основываются на предположении о том, что распределение наблюдаемых значений описывается нормальным законом распределения.
Один
из критериев основан на статистике
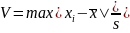
здесь
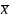 выборочное
среднее
выборочное
среднее
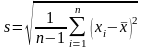
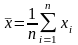
s – среднеквадратическое отклонение
Если V < Vкр, то резко выделяющееся значение в выборке нельзя считать промахом и его лучше оставить
Построение гистограммы распределения
Как правило область изменения данных разбивают на m одинаковых интервалов длинной Δx и вычисляется относительная плотность попадания значений в каждый интервал:
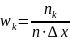
Д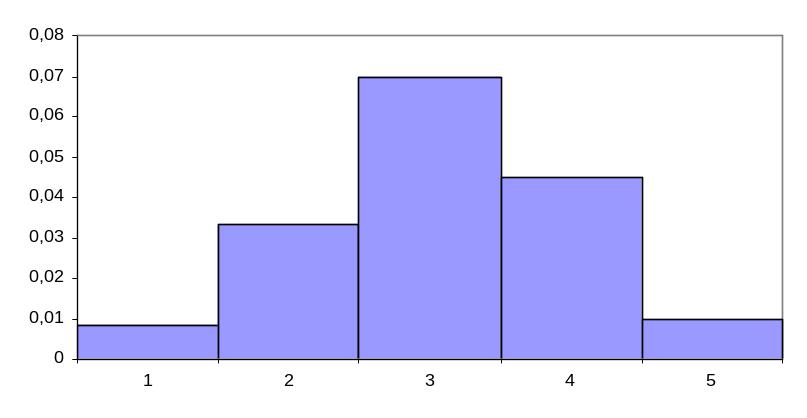 иаграмму
построенную из прямоугольников с
основанием Δx
и высотами wk
называют гистограммой
иаграмму
построенную из прямоугольников с
основанием Δx
и высотами wk
называют гистограммой
Отмечаются наименьшее и наибольшее значения в выборке и диапазон между ними разбивается на m равных интервалов.
Отмечаются крайние точки каждого из интервалов в порядке их возрастания, а также середины интервалов x01 , x02 , ..., x0m.
Подсчитывается количество значений данных, попавших в каждый из интервалов: n1,n2, ..., nm.
Г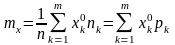 руппированные
данные могут быть использованы для
оценки математического ожидания и
дисперсии:
руппированные
данные могут быть использованы для
оценки математического ожидания и
дисперсии:
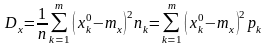
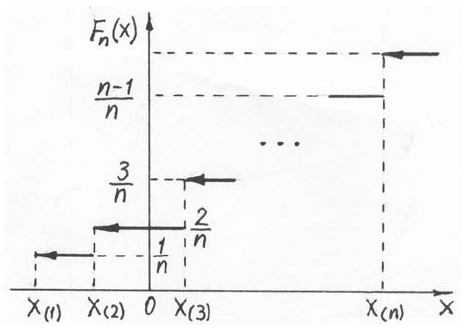
Построение эмпирической функции распределения
Представление
о характере распределения выборочных
данных может давать также эмпирическая
функция распределения, которой называется
функция F(x)
определяющая для каждого выборочного
значения случайной величины X относительную
частоту события X < x:
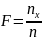
Здесь nx число наблюдений меньших X
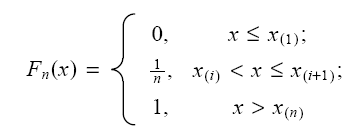
![]()
Проверка соответствия выбранной модели закона распределения исходным данным. Критерий согласия χ2 (хи-квадрат)
Применение многих методов статистической обработки данных предполагает, что результаты наблюдений являются выборкой из генеральной совокупности с вполне определенным законом распределения, например нормальным.
Чтобы оценить, насколько выбранный теоретически закон распределения согласуется с результатами наблюдений, используют так называемые критерии согласия.
В качестве меры расхождения между эмпирическим и теоретическим законами распределения К. Пирсоном была предложена статистика:
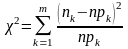
Здесь: m ─ число значений, принятых случайной величиной, n – общее число наблюдений, pk ─ вероятность появления k-го значения в теоретическом законе распределения
Соответствие выбранного теоретического закона распределение результатам наблюдения должно быть отвергнута при уровне значимости α, если полученное в опыте значение статистики c2 превысит критическое значение c2m−1,α.
Для различного числа степеней свободы и уровня значимости составлены таблицы критических значений c2
Когда вероятность появления k-го значения в теоретическом законе распределения pk определяются с помощью параметров распределения оцененных по выборке число степеней свободы равно m-s-1. Здесь s – количество параметров теоретического закона распределения оцененных по выборке