

Анализ множественных связей
Оценка степени тесноты связи между входной переменной Y и входными переменными X1, X2, ..., Xp, осуществляется с помощью множественного коэффициента корреляции Ry.
Величина Ry2 показывает, какая доля от полной дисперсии D[Y] результирующей переменой Y определяется контролируемым нами изменением функции φ(X1, X2, ..., Xp):
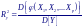
З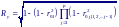 начение
множественного коэффициента корреляции
Ry
можно
вычислить, используя частные коэффициенты
корреляции, следующим образом:
начение
множественного коэффициента корреляции
Ry
можно
вычислить, используя частные коэффициенты
корреляции, следующим образом:
Для проверки нулевой гипотезы H0: Ry2 = 0 используют статистику:
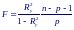
которая при справедливости гипотезы H0 имеет распределение Фишера с р и n−p−1 степенями свободы. Гипотеза об отсутствии множественной корреляционной связи между Y и X отвергается с уровнем значимости α, если расчетное значение статистики F превышает α-процентную точку распределения Фишера р и n−p−1 степенями свободы.
Ранговые коэффициенты корреляции
Если необходимо исследовать двумерные данные, закон распределения которых заметно отличается от нормального, то для решения вопроса о некоррелированности или коррелированности этих данных нельзя применять критерии проверки гипотез о значимости коэффициента корреляции, рассмотренные ранее. В этом случае можно воспользоваться методом, основанным на рангах наблюдений каждой переменной и приводящим к коэффициентам ранговой корреляции.
Коэффициент ранговой корреляции Спирмена
Коэффициент ранговой корреляции Спирмена rs для выборки (x1, y1), ..., (xn, yn) объема n определяется как обычный коэффициент корреляции для ранговых переменных. Это означает, что значения X ранжируются по возрастанию и им приписываются ранги от 1 до n. Аналогичная операция осуществляется и с Y. Затем вычисляется коэффициент корреляции между рангами элемента пары (xi, yi), i = 1, ..., n.
Т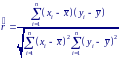 .
е., в выражение для выборочного коэффициента
корреляции
.
е., в выражение для выборочного коэффициента
корреляции
следует вместо значений выборки подставить их ранги.
Учитывая, что xi упорядочены в порядке возрастания, ранг xi равен i (при отсутствии совпадений между xi). Ранг yi обозначим через Ri. Поскольку ранги xi принимают значения от 1 до n, их сумма, как сумма чисел натурального ряда, равна n(n + 1)/2. Отсюда среднее значение рангов xi
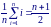
Такое же среднее значение имеют и ранги yi.
Для коэффициента ранговой корреляции получим выражение:
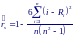
Если два и более значений в исходных данных совпадают, то им присваивают ранг, равный среднему рангов, присваиваемых при отсутствии совпадения.
Закон распределения коэффициента rs при условии некоррелированности переменных симметричен относительно нуля. Имеются таблицы процентных точек распределения rs, позволяющие проверять гипотезу о значимости коэффициента ранговой корреляции H0: rs=0.
В случае больших выборок (n ≥ 30) для проверки нулевой гипотезы может использоваться статистика
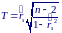
которая распределена по закону Стьюдента с n−2 степенями свободы.
Коэффициент ранговой корреляции Кендалла
Для вычисления коэффициента ранговой корреляции Кендалла rk необходимо ранжировать данные по одному из признаков в порядке возрастания и определить соответствующие ранги по второму признаку. Затем для каждого ранга второго признака определяется число последующих рангов, больших по величине, чем взятый ранг, и находится сумма этих чисел.
Коэффициент ранговой корреляции Кендалла определяется формулой
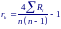
где Ri – количество рангов второй переменной, начиная с i+1, величина которых больше чем величина i-ого ранга этой переменной.
Существуют таблицы процентных точек распределения коэффициента rk, позволяющие проверить гипотезу о значимости коэффициента корреляции.
П ри
больших объемах выборки критические
значения rk
не табулируются,
и их приходится вычислять по приближенным
формулам, которые основаны на том, что
при нулевой гипотезе H0:
rk=0
и больших n
случайная величина
ри
больших объемах выборки критические
значения rk
не табулируются,
и их приходится вычислять по приближенным
формулам, которые основаны на том, что
при нулевой гипотезе H0:
rk=0
и больших n
случайная величина
распределена приближенно по стандартному нормальному закону.