

Непараметрические методы факторного анализа. Ранговый двухфакторный анализ без повторений
В ряде случаев предположение о нормальности закона распределения остаточных случайных величин в моделях, описанных в дисперсионном анализе, не выполняется. Более того, этот закон оказывается неизвестным. Тогда используют различные непараметрические методы проверки однородности нескольких выборок, из которых наиболее разработаны ранговые методы.
Обозначив через rij ранг значения xij, который получит это значение при упорядочении всей совокупности данных в порядке возрастания, придем к следующей таблице данных.
В рамках ранговых критериев нулевая гипотеза формулируется как гипотеза о том, что все k выборок (столбцов таблицы) являются выборками из одного и того же распределения.
Строго говоря, если нулевая гипотеза отвергается, то можно только утверждать, что распределения совокупностей различны. Это, однако, не означает, что их средние не равны между собой. Для вывода о том, что выборки производились из совокупностей с различными математическими ожиданиями, необходимо предположить, что эти совокупности одинаковы по всем другим параметрам.
Критерий Фридмана
Рассмотрим двухфакторный эксперимент, когда на уровнях фактора B проведено по одному наблюдению (неповторяемый эксперимент). Его модель имеет вид

В отличие от дисперсионного анализа нам неизвестно распределение случайных величин εij. Известно только, что оно непрерывно, а сами случайные величины независимы в совокупности и имеют одинаковое распределение.
В этом случае для оценки влияния на исследуемый признак факторов A и B используется непараметрический критерий Фридмана, который основан на переходе от значений xij в таблице данных двухфакторного анализа к их рангам.

В отличие от однофакторного анализа ранжирование осуществляется не по всей совокупности величин xij , а по строкам (для проверки однородности данных по столбцам таблицы данных), т. е. ранжируется каждая отдельная строка таблицы данных.
Обозначим полученные ранги величин xij через rij. Будем считать, что среди элементов xij, стоящих в одной строке таблицы, нет совпадающих. Определим средние значением рангов по i-му столбцу
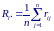
При справедливости нулевой гипотезы в силу равновероятности всех перестановок рангов в каждой строке значение Ri. для каждого i не должно сильно отличаться от величины R.. = 0.5(k + 1), представляющей собой общий средний ранг всех элементов таблицы рангов.
О тсюда
статистика Фридмана, используемая для
проверки нулевой гипотезы, будет
определяться как
тсюда
статистика Фридмана, используемая для
проверки нулевой гипотезы, будет
определяться как
При вычислениях удобно использовать другую запись статистики:
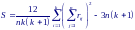
Для небольших значений k и n имеются таблицы процентных точек распределения статистики Фридмана, позволяющие при заданном уровне значимости α находить критические значения s(k, n, α).
При больших n для определения критических значений пользуются аппроксимацией статистики S. При справедливости нулевой гипотезы статистика в этом случае аппроксимируется распределением χ2 с k−1 степенями свободы.
Нулевая гипотеза об однородности данных по столбцам (отсутствие влияния фактора A) принимается с уровнем значимости α, если расчетное значение статистики S меньше критического значения и отвергается, если оно больше критического.
Если в строках таблицы данных имеются совпадающие значения, при переходе к таблице рангов используются средние ранги, а вместо статистики S используется ее модификация.
Для проверки гипотезы об эффектах фактора B (строк) следует поменять местами строки и столбцы таблицы данных.