

Качество данных. Этапы обработки данных. Вычислительные аспекты обработки данных
Первое, с чем сталкивается исследователь при обработке данных, это контроль качества данных, который обычно включает следующие процедуры:
Проверку данных с целью выявления тех значений, которые логически несовместимы или противоречат предварительным сведениям о границах изменения отдельных переменных
Выявление резко выделяющихся по своей величине наблюдений
Восстановление пропущенных наблюдений, включая и наблюдения, которые были исключены по причине их чрезвычайно подозрительного характера
Проверка однородности нескольких групп исходных данных
Проверка статистической независимости наблюдений, представляющих исходные данные
Этапы обработки данных
Начальная обработка, т. е. представление исходных данных в подходящей для анализа форме, и проведение проверки качества данных
Предварительный анализ данных, направленный на выяснение общей формы данных и предложение путей более обстоятельного анализа
Итоговый анализ (статистическая обработка), цель которого – дать основу для выводов
Представление выводов в краткой и ясной форме
Вычислительные аспекты обработки данных
В настоящее время существует большое количество программных средств реализующих различные методы обработки данных:
SPSS, STADIA, STATISTICA, STATGRAPHIKS ЭВРИСТА
Тем не менее при использовании пакетов статистических программ принятие решений остается за исследователем. Программа освобождает исследователя только от рутинной вычислительной работы
Разновидности исследований. Шкалы измерений
Разновидности исследований:
Эксперимент (активный эксперимент). В этом случае система, над которой осуществляется наблюдение, построена самим исследователем и контролируется им. При этом, как правило, одно из возможных воздействий применяется к каждому объекту наблюдений (экспериментальной единице) и измеряется результат воздействия (отклик)
Пассивное наблюдение (пассивный эксперимент). В этом случае данные собираются от объектов, входящих в некоторую систему. При этом исследователь не имеет другого контроля над сбором данных, кроме, может быть, некоторого участия в проверке качества данных
Шкалы измерений:
Номинальная шкала (шкала наименований). Эта шкала используется только для того, чтобы отнести объект или индивидуум в определенный класс
Порядковая шкала. Эта шкала в дополнение к функции отнесения объектов в определенный класс также упорядочивает классы по степени выраженности заданного свойства
Интервальная шкала. Эта шкала позволяет не только классифицировать и упорядочивать объекты и индивидуумы, но и количественно оценивать различие между классами
Шкала отношений. Эта шкала отличается от интервальной шкалы лишь тем, что в ней задано абсолютное начало отсчета
Описательная статистика: Закон распределения случайной величины
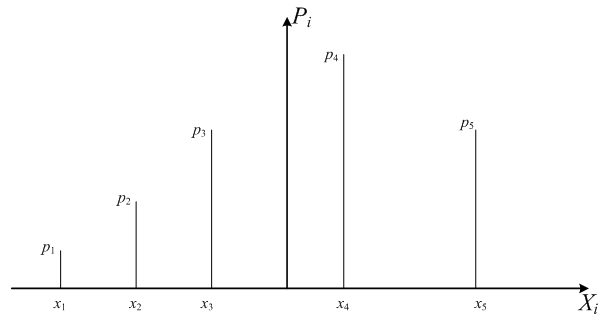
Полное описание случайной величины дается законом распределения, который устанавливает зависимость между возможными значениями случайной величины и их вероятностями
Закон распределения случайной величины можно задать в виде графика, таблицы или аналитического выражения:
Ф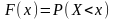 ункцией
распределения случайной величины X
называется
функция F(x),
равная вероятности того, что случайная
величина примет значение меньшее, чем
x :
ункцией
распределения случайной величины X
называется
функция F(x),
равная вероятности того, что случайная
величина примет значение меньшее, чем
x :
Вероятность попадания случайной величины в интервал от x1 до x2 равна разности функции распределения в точках x1 и x2 :
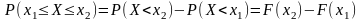
При достаточно широких предположениях о плотностях распределения случайных величин их сумма с ростом числа слагаемых ведет себя асимптотически нормально, что составляет содержание центральной предельной теоремы теории вероятностей
Т. е. если N достаточно велико, значение данных выборки будут иметь распределение, которое близко к нормальному (Гауссовскому) распределению
Нормальное распределение величины x описывается следующей функцией:

Характеристики распределения Гаусса:
оно симметрично относительно m
имеет максимум равный
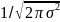
монотонно убывает при возрастании |x-m|
Если совокупность случайных величин задана в виде набора дискретных значений, то математическое ожидание случайной величины определяется как среднее значение по выборке:
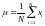
Числовой характеристикой, показывающей степень разброса значений случайной величины относительно математического ожидания, называется дисперсия
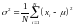
П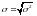 оскольку
дисперсия имеет размерность квадрата
случайной величины, то для характеристики
меры рассеяния значений случайной
величины относительно математического
ожидания пользуются среднеквадратическим
отклонением σ,
равным значению квадратного корня из
дисперсии
оскольку
дисперсия имеет размерность квадрата
случайной величины, то для характеристики
меры рассеяния значений случайной
величины относительно математического
ожидания пользуются среднеквадратическим
отклонением σ,
равным значению квадратного корня из
дисперсии