

Вопрос 11. Корреляционно-дисперсионный анализ переменных, выраженными количественными и качественными показателями.
Корреляционно-дисперсионный анализ порядковых данных
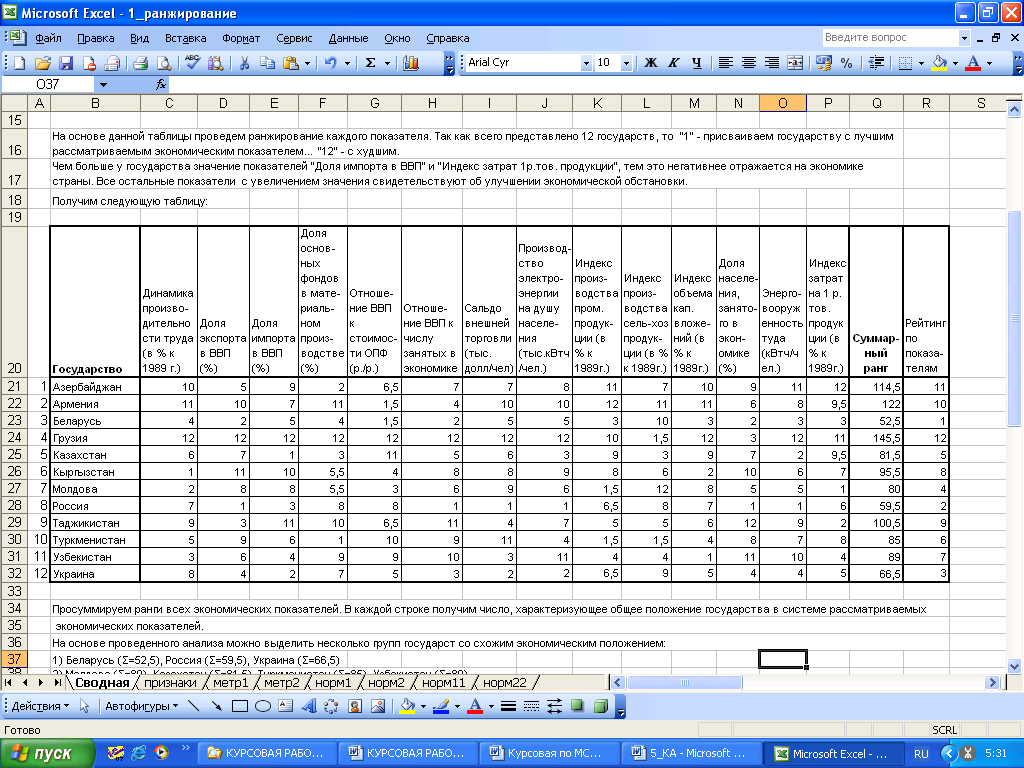
Проведем структурный анализ связей в признаковом пространстве на основе таблицы «Основные экономические показатели стран СНГ в 1990 г.» с проранжированными показателями.
Для этого рассчитаем коэффициенты Спирмена и Кендалла.
Для случая отсутствия связанных рангов:
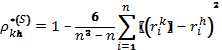
![]() – кол-во объектов
– кол-во объектов
Так как в нашем случае имеются связанные ранги, то применим модифицированный коэффициент Спирмена:
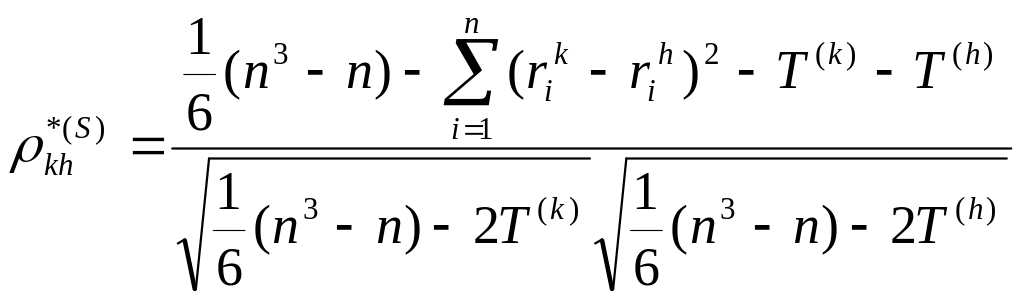
Коэффициент связанности:
![]() ,
где
,
где
![]()
![]() -
число групп связанных рангов в ранжировкеl
-
число групп связанных рангов в ранжировкеl
![]() -
количество элементов или количество
неразличимых элементов в группе под
номером t
у l-й
ранжировки
-
количество элементов или количество
неразличимых элементов в группе под
номером t
у l-й
ранжировки
|
1. |
2. |
3. |
4. |
5. |
6. |
7. |
8. |
9. |
10. |
11. |
12. |
13. |
14. |
T(l) |
0 |
0 |
0 |
0,5 |
1 |
0 |
0 |
0 |
1 |
0,5 |
0 |
0 |
0 |
0,5 |
Модифицированные коэффициенты Спирмена:
|
1. |
2. |
... |
n |
1. |
1 |
0,021 |
0,238 |
0,557 |
2. |
|
1 |
0,455 |
0,459 |
... |
|
|
… |
… |
n |
|
|
|
1 |
Проверка значимости коэффициентов:
![]() -
отвергает идентичность ранжировок
-
отвергает идентичность ранжировок
![]()
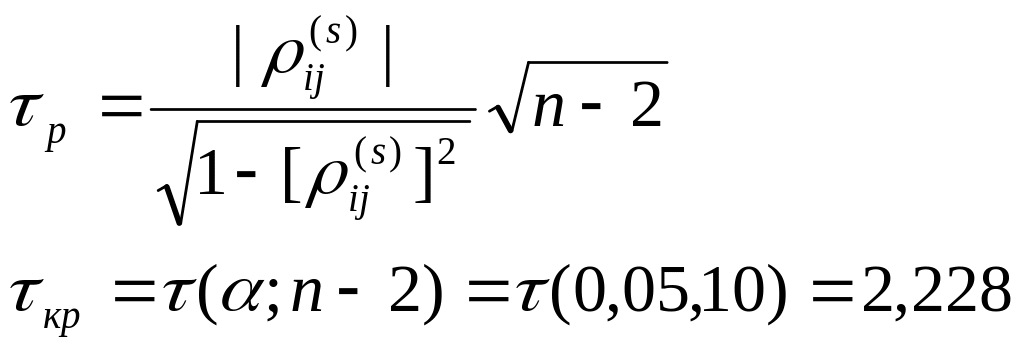
Если τр.> τкр, то то принимается гипотеза H1, т.е. две исследуемые ранжировки согласованы.
τрасчетное
|
1. |
2. |
3. |
4. |
5. |
6. |
7. |
8. |
9. |
10. |
11. |
12. |
13. |
14. |
1. |
|
0,066 |
0,774 |
1,540 |
0,729 |
0,311 |
0,492 |
0,561 |
2,776 |
0,391 |
3,644 |
0,561 |
1,462 |
2,120 |
2. |
|
|
1,614 |
0,436 |
0,540 |
1,912 |
5,172 |
2,424 |
0,975 |
1,037 |
0,896 |
0,631 |
1,614 |
1,633 |
3. |
|
|
|
1,025 |
0,222 |
2,811 |
2,213 |
2,919 |
0,552 |
0,402 |
0,847 |
1,023 |
3,155 |
0,357 |
4. |
|
|
|
|
0,022 |
0,751 |
0,166 |
1,763 |
1,009 |
0,189 |
0,824 |
0,278 |
1,142 |
0,335 |
… |
|
|
|
|
|
… |
… |
… |
… |
… |
… |
… |
… |
… |
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Коэффициент Кендалла:
Рассчитаем коэффициент Кендалла для ранжировок, у которых коэффициенты по Спирмену оказались значимыми.
![]() ,
где
,
где
![]() -
количество минимальных перестановок
соседних элементов в последовательности
rk
необходимое для приведения ее к
последовательности rh,
-
количество минимальных перестановок
соседних элементов в последовательности
rk
необходимое для приведения ее к
последовательности rh,
![]()
 1,
если rqh>rlh
1,
если rqh>rlh
0, если перестановка не нужна
ПРИМЕР перестановки
(1,2,3,4,5,6,7,8,9,10) – такая послед-ть должна быть
(3,1,2,7,5,4,6,10,9,8) – такая последовательность у нас
Треугольная м-ца перестановок,
Пояснение *: 3>1 и 3>2
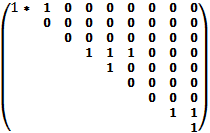
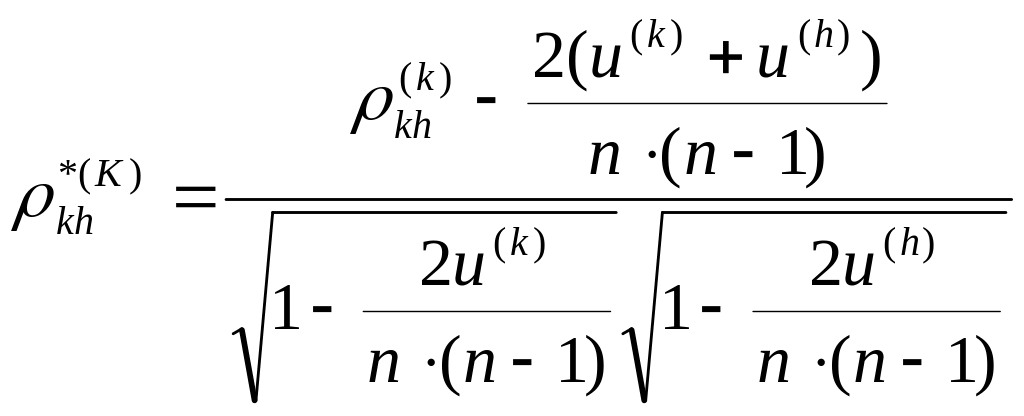 -
модифицированный коэффициент Кендалла
-
модифицированный коэффициент Кендалла
 – коэффициент связанности
– коэффициент связанности
– число групп связанных рангов в каждой ранжировке
Проверка значимости коэффициентов:

![]()
Если
![]() ,
то принимается гипотеза H1,
т.е. две исследуемые ранжировки
согласованы.
,
то принимается гипотеза H1,
т.е. две исследуемые ранжировки
согласованы.
Отбор информативных признаков
Значимая связь наблюдается у следующих признаков:
1 и 9
1 и 11
…
9 и 14
Исключим следующие признаки (которые чаще всего встречаются в связи с др. признаками – см. выше):
1. Динамика производительности труда (в % к 1989г)
2. Доля экспорта в ВВП (%)
6. Отношение ВВП к числу занятых в экономике
8. Производство электроэнергии на душу населения (тыс.кВтч/чел.)
Сгруппируем объекты в сокращенном признаковом пространстве с учетом отобранных информативных признаков:
|
|
3. |
4. |
5. |
7. |
9. |
10. |
11. |
12. |
13. |
14. |
Σ-й ранг |
1) |
Азербайджан |
9 |
2 |
6,5 |
7 |
11 |
7 |
10 |
9 |
11 |
12 |
84,5 |
2) |
Армения |
7 |
11 |
1,5 |
10 |
12 |
11 |
11 |
6 |
8 |
9,5 |
87 |
3) |
Беларусь |
5 |
4 |
1,5 |
5 |
3 |
10 |
3 |
2 |
3 |
3 |
39,5 |
12) |
Украина |
2 |
7 |
5 |
2 |
6,5 |
9 |
5 |
4 |
4 |
5 |
49,5 |
Сформируем группы:
|
Беларусь |
39,5 |
1 |
Россия |
49,5 |
|
Украина |
49,5 |
|
Молдова |
58 |
2 |
Туркменистан |
58 |
|
Узбекистан |
59 |
|
Казахстан |
60,5 |
3 |
Кыргызстан |
66,5 |
|
Таджикистан |
70,5 |
4 |
Азербайджан |
84,5 |
|
Армения |
87 |
|
Грузия |
97,5 |
Корреляционно-дисперсионный анализ количественных данных
Исходные данные (вариант № 203):
№ предприятия |
Y2 |
X4 |
X5 |
X7 |
X9 |
X17 |
1 |
204,2 |
0,23 |
0,78 |
1,37 |
0,23 |
17,72 |
2 |
209,6 |
0,24 |
0,75 |
1,49 |
0,39 |
18,39 |
… |
|
|
|
|
|
|
53 (n) |
72 |
0,31 |
0,74 |
1,22 |
0,79 |
19,41 |
Y2 – индекс снижения себестоимости продукции;
X4 – трудоемкость единицы продукции;
X5 – удельный вес рабочих в составе ППП;
X7 – коэффициент сменности оборудования;
X9 – удельный вес потерь от брака;
X17 – непроизводственные расходы.
Матрица парных коэффициентов корреляции (R)
|
|
1 |
2 |
3 |
4 |
5 |
6 |
|
|
Y2 |
X4 |
X5 |
X7 |
X9 |
X17 |
1 |
Y2 |
1 |
-0,6414 |
0,234 |
0,3619 |
-0,0094 |
-0,0582 |
2 |
X4 |
-0,6414 |
1 |
-0,322 |
-0,3549 |
-0,0482 |
0,1994 |
3 |
X5 |
0,234 |
-0,322 |
1 |
0,4147 |
0,3627 |
-0,9402 |
4 |
X7 |
0,3619 |
-0,3549 |
0,4147 |
1 |
0,2705 |
-0,3894 |
5 |
X9 |
-0,0094 |
-0,0482 |
0,3627 |
0,2705 |
1 |
-0,3775 |
6 |
X17 |
-0,0582 |
0,1994 |
-0,9402 |
-0,3894 |
-0,3775 |
1 |
Парный коэффициент корреляции считается значимым, если tнабл>tкр
tкр (α; n– 2) = tкр (0,05;51) = 2,008
Матрица частных коэффициентов корреляции вычисляется согласно формуле:
![]() ,
где
,
где
R12 – алгебраическое дополнение к элементу r12 корреляционной матрицы R,
R11 – алгебраическое дополнение к элементу r11 = 1,
R22 – алгебраическое дополнение к элементу r22 = 1,
Rij=![]() ,
где Mij-
определитель
матрицы, получаемой из матрицы R,
путем вычеркивания j-ой
строки и i-го
столбца.
,
где Mij-
определитель
матрицы, получаемой из матрицы R,
путем вычеркивания j-ой
строки и i-го
столбца.
Проверка на значимость частных коэффициентов корреляции при α = 0,05:
![]()
Коэффициент корреляции считается значимым (т.е. гипотеза H0
отвергается с вероятностью ошибки (0,05), если tнабл>tкр для заданного n-l-2,
в нашем случаеn = 53, l = 4 (l – это порядок коэффициента корреляции, т.е. число фиксируемых факторов).
tкр (α; n – l – 2) = tкр (0,05;47) = 2,01
Если |tнабл| >tкрит, то гипотеза H0отвергается, т.е. r значим.
t кр = |
2,01174 |
|
|
|
|
|
|
t набл. |
значим,если |t набл| >tкр |
|
ρ 12/3456 = |
-0,50614 |
-4,02333 |
+ |
|
ρ 13/2456 = |
0,387995 |
2,886046 |
+ |
|
ρ 14/2356 = |
0,249213 |
1,76418 |
- |
|
ρ 15/2346 = |
-0,07929 |
-0,54532 |
- |
|
ρ 16/2345 = |
0,410426 |
3,085599 |
+ |
|
ρ 23/1456 = |
-0,10523 |
-0,72548 |
- |
|
ρ 24/1356 = |
-0,10777 |
-0,74319 |
- |
|
ρ 25/1346 = |
0,033959 |
0,232945 |
- |
|
ρ 26/1345 = |
-0,04532 |
-0,311 |
- |
|
ρ 34/1256 = |
-0,07028 |
-0,48304 |
- |
|
ρ 35/1246 = |
0,062736 |
0,430944 |
- |
|
ρ 36/1245 = |
-0,94107 |
-19,0754 |
+ |
|
ρ 45/1236 = |
0,174861 |
1,217549 |
- |
|
ρ 46/1235 = |
-0,16725 |
-1,16301 |
- |
|
ρ 56/1234 = |
-0,04202 |
-0,28834 |
- |
Интервальные оценки частных коэффициентов корреляции:
![]() ,
функция нечетная, т.е.
,
функция нечетная, т.е.
![]()
![]() ,
где tγ
вычисляют по таблице интегральной
функции Лапласа, n
= 53, а l
=4 – порядок коэффициента корреляции,
т.е. число
фиксируемых факторов.
,
где tγ
вычисляют по таблице интегральной
функции Лапласа, n
= 53, а l
=4 – порядок коэффициента корреляции,
т.е. число
фиксируемых факторов.
Чтобы получить интервальные оценки для значимых частных коэффициентов корреляции ρ 12/3456 ,
ρ 13/2456 , ρ 16/2345 , ρ 36/1245воспользуемся таблицей Z-преобразования Фишера:
-0,69
![]() ρ
12/3456
-0,26
ρ
12/3456
-0,26
0,12 ρ 13/2456 0,6
0,15 ρ 16/2345 0,62
-0,97 ρ 36/1245 -0,9
![]() -
множественных коэффициентов корреляции
-
множественных коэффициентов корреляции
|
|
|
r2 |
F набл |
F кр |
Значим |
Y2 |
r1/23456 = |
0,7303 |
0,53336 |
10,74402 |
2,412837 |
+ |
X4 |
r2/13456 = |
0,6706 |
0,44973 |
7,682518 |
|
+ |
X5 |
r3/12456 = |
0,9579 |
0,917656 |
104,7553 |
|
+ |
X7 |
r4/12356 = |
0,5467 |
0,298895 |
4,00741 |
|
+ |
X9 |
r5/12346 = |
0,4147 |
0,171964 |
1,952157 |
|
- |
X17 |
r6/12345 = |
0,9564 |
0,91468 |
100,7732 |
|
+ |
Проверка на значимость:
![]()
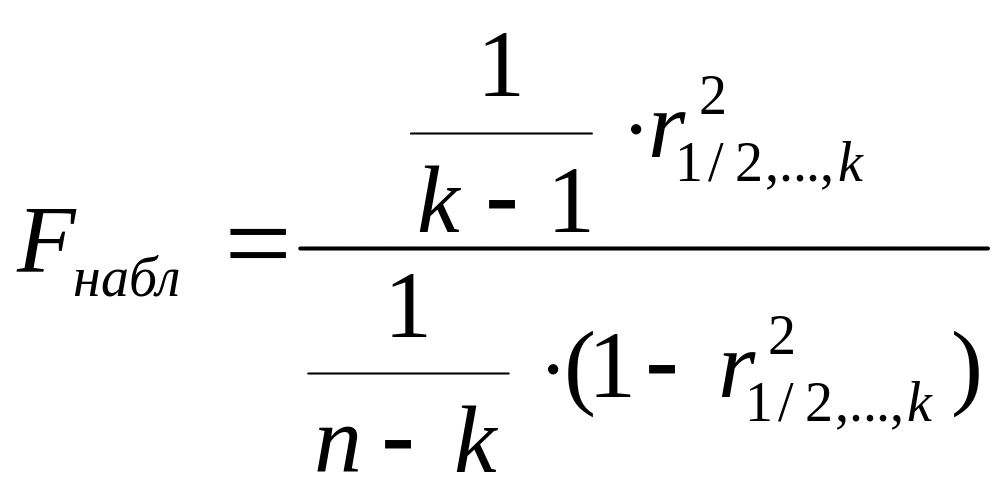 ,
где k
= 6 – число факторов, n
= 53.
,
где k
= 6 – число факторов, n
= 53.
Множественный коэффициент корреляции считается значимым, т. е. имеет место линейная статистическая зависимость, между X1 и остальными факторами X2,...,Xk, если:
Fнабл. >Fкр. (α, k - 1, n - k) , где Fкр определяется по таблице, F-распределения для заданных α,
ν1 = k - 1, ν2 = n - k.
Значимыми оказались r1, r2, r3, r4, r6.
r3является наибольшим множественным коэффициентом корреляции.
Уравнение регрессии (в качестве результативного показателя выбран тот, которому соответствует наибольший множественный коэффициент корреляции):X5
X5 = 0,948721 + 0,0000741993*Y2 - 0,0205264*X4 - 0,00905721*X7 + 0,00305865*X9 - 0,0104647*X17