

vstatmp_engl
.pdf
|
|
|
|
|
|
6.6 |
Inclusion of Constraints 167 |
||||||
Example 92. Example 90 continued |
|
|
|
|
|
|
|
|
|
|
|||
The modified χ2 expression is |
|
|
|
|
|
|
|
|
|
|
|
||
3 |
|
2 |
3 |
|
|
|
|
|
|
|
|
|
|
X |
ri − ρi |
|
X |
|
|
|
|
|
|
|
|
|
|
χ2 = |
|
+ |
|
(p |
ai − |
π )V (p |
aj − |
π ) + |
|||||
i=1 |
δri |
|
i,j=1 |
|
ai aij |
aj |
|||||||
3 |
|
|
|
|
|
3 |
|
πi 2 |
|
ε 2 |
|||
X |
|
|
|
|
|
X |
|
|
+ |
|
|
||
+ i,j=1(pbi − πbi)Vbij (pbj − πbj ) + i=1 |
δπ |
δε |
|||||||||||
with tiny values for δπ and δε.
This direct inclusion of the constraint through a penalty term in the fit is technically very simple and e cient.
As demonstrated in example 88 the term su ciently small means that the uncertainty δhk of a constraint k as derived from the fitted values of the parameters and their errors is large compared to δk:
|
X |
|
|
|
(δh)k2 = |
|
∂hk ∂hk |
δθiδθj δk2 . |
(6.24) |
|
∂θi ∂θj |
|||
|
i,j |
|
|
|
The quantities δθi in (6.24) are not known precisely before the fit is performed but can be estimated su ciently well beforehand. The precise choice of the constraint precision δk is not at all critical, variations by many orders of magnitude make no di erence but a too small values of δk could lead to numerical problems.
6.6.4 The Method of Lagrange Multipliers
This time we choose the likelihood presentation of the problem. The likelihood function is extended to
N |
X |
|
X |
(6.25) |
|
ln L = |
ln f(xi|θ) + αkhk(θ) . |
|
i=1 |
k |
|
We have appended an expressions that in the end should be equal to zero, the constraint functions multiplied by the so-called Lagrange multipliers. The MLE as obtained by setting ∂ ln L/∂θj = 0 yields parameters that depend on the Lagrange multipliers α. We can now use the free parameters αk to fulfil the constraints, or in other words, we use the constraints to eliminate the Lagrange multiplier dependence of the MLE.
Example 93. Example 88 continued
Our full likelihood function is now
ln L = |
− |
(l1 − λ1)2 |
− |
(l2 − λ2)2 |
+ α(λ + λ |
− |
L) |
|
||||
2δ2 |
2δ2 |
|
||||||||||
|
|
1 2 |
|
|
||||||||
ˆ |
|
|
2 |
|
|
ˆ |
ˆ |
|
2 |
α = (l1 |
+l2−L)/2 |
|
with the MLE λ1,2 |
= l1,2−δ |
α. Using λ1 |
+λ2 = L we find δ |
|
||||||||
ˆ |
|
|
|
|
|
ˆ |
= (L + l2 − l1)/2. |
|
|
|
|
|
and, as before, λ1 |
= (L + l1 − l2)/2, λ2 |
|
|
|
|
|||||||
168 6 Parameter Inference I
Of course, the general situation is much more complicated than that of our trivial example. An analytic solution will hardly be possible. Instead we can set the derivative of the log-likelihood not only with respect to the parameters θ but also with respect to the multipliers αk equal to zero, ∂ ln L/∂αk = 0, which automatically implies, see (6.25), that the constraints are satisfied. Unfortunately, the zero of the derivative corresponds to a saddle point and cannot be found by a maximum searching routine. More subtle numerical methods have to be applied.
Most methods avoid this complication and limit themselves to linear regression models which require a linear dependence of the observations on the parameters and linear constraint relations. Non-linear problems are then solved iteratively. The solution then is obtained by a simple matrix calculus.
Linear regression will be sketched in Sect. 7.2.3 and the inclusion of constraints in Appendix 13.10.
6.6.5 Conclusion
By far the simplest method is the one where the constraint is directly included and approximated by a narrow Gaussion. With conventional minimizing programs the full error matrix is produced automatically.
The approach using a reduced parameter set is especially interesting when we are primarily interested in the parameters of the reduced set. Due to the reduced dimension of the parameter space, it is faster than the other methods. The determination of the errors of the original parameters through error propagation is sometimes tedious.
It is recommended to either eliminate redundant parameters or to use the simple method where we represent constraints by narrow Gaussians. The application of Lagrange multipliers is unnecessarily complicated and the linear approximation requires additional assumptions and iterations.
6.7 Reduction of the Number of Variates
6.7.1 The Problem
A statistical analysis of an univariate sample is obviously much simpler than that of a multidimensional one. This is not only true for the qualitative comparison of a sample with a parameter dependent p.d.f. but also for the quantitative parameter inference. Especially when the p.d.f. is distorted by the measurement process and a Monte Carlo simulation is required, the direct ML method cannot be applied as we have seen above. The parameter inference then happens by comparing histograms with the problem that in multidimensional spaces the number of entries can be quite small in some bins. Therefore, we have an interest to reduce the dimensionality of the variable space by appropriate transformations, of course, if possible, without loss of information. However, it is not always easy to find out which variable or which variable combination is especially important for the parameter estimation.

170 |
6 |
Parameter Inference I |
|
|
|
|
|
|
|
q |
= -1 |
|
|
q |
= 1 |
|
|
g(u) |
|
|
|
|
|
|
|
-1.0 |
-0.5 |
0.0 |
u |
0.5 |
1.0 |
Fig. 6.13. Simulated p.d.f.s of the reduced variable u for the values ±1 of the parameter.
Example 94. Reduction of the variate space We consider the p.d.f.
f(x, y, z|θ) = π1 h(x2 + y2 + z2)1/2 + (x + y3)θi , x2 + y2 + z2 ≤ 1 , (6.27)
which depends on three variates and one parameter. For a given sample of observations in the three dimensional cartesian space we want to determine the parameter θ. The substitutions
|
x + y3 |
√ |
|
|
|
|
|||
u = |
|
, |u| ≤ 2 , |
||
(x2 + y2 + z2)1/2 |
||||
v = (x2 + y2 + z2)1/2 , 0 ≤ v ≤ 1 ,
z = z
lead to the new p.d.f. g′(u, v, z)
g′(u, v, z|θ) = |
v |
[1 + u θ] |
∂(x, y, z) |
, |
|
|
|
|
|||
π |
∂(u, v, z) |
||||
which after integrating out v and z yields the p.d.f. g(u|θ):
Z
g(u|θ) = dz dv g′(u, v, z|θ) .
This operation is not possible analytically but we do not need to compute g explicitly. We are able to determine the MLE and its error from the simple log-likelihood function of θ
X
ln L(θ) = ln(1 + uiθ) .
i

172 |
6 |
Parameter Inference I |
|
|
|
|
|
|
|
|
|
|
mean values |
|
1.4 |
|
|
|
|
|
|
100 |
true |
observed |
observed |
|
|
|
|
|
|
|
1.2 |
|
|
|
|||
|
|
|
|
|
|
|
|
||
|
events |
75 |
|
|
1.0 |
|
|
|
|
|
|
|
|
|
|
|
|||
|
of |
|
|
|
|
|
|
|
|
|
number |
50 |
|
|
|
0.8 |
0.8 |
1.0 |
1.2 |
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
true |
|
|
|
|
|
|
|
|
|
|
|
|
|
25 |
|
|
|
|
|
|
|
|
|
00 |
1 |
2 |
|
|
3 |
4 |
5 |
|
|
|
|
|
lifetime |
|
|
||
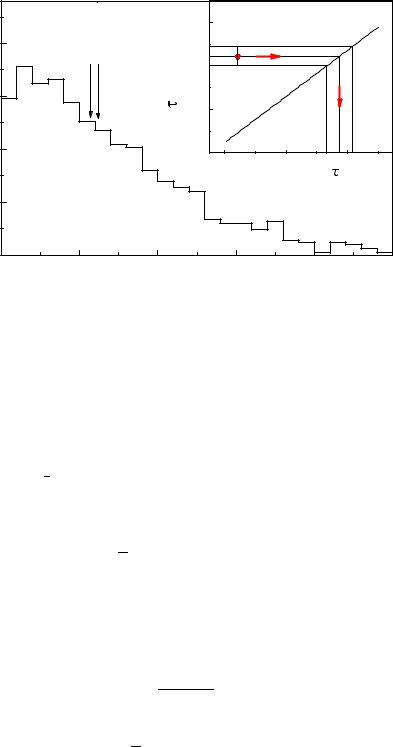
Fig. 6.14. Observed lifetime distribution. The insert indicates the transformation of the observed lifetime to the corrected one.
obtain when we insert the data into the undistorted p.d.f.. In both cases we find the relation between the experimental statistic and the estimate of the parameter by a Monte Carlo simulation. The method should become clear in the following example.
Example 95. Approximated likelihood estimator: Lifetime fit from a distorted distribution
The sample mean t of a sample of N undistorted exponentially distributed lifetimes ti is a su cient estimator: It contains the full information related to the parameter τ, the mean lifetime (see Sect. 7.1.1). In case the distribution is distorted by resolution and acceptance e ects (Fig. 6.14), the mean value
X
t′ = t′i/N
of the distorted sample t′i will usually still contain almost the full information relative to the mean life τ. The relation τ(t′) between τ and its approximation t′ (see insert of Fig. 6.14) is generated by a Monte Carlo simulation. The uncertainty δτ is obtained by error propagation from the uncertainty δt′ of t′,
|
|
|
|
|
|
|
− |
|
2) |
|
||
|
|
|
|
|
t′2 |
|
||||||
|
|
|
)2 = |
( |
t′ |
|
||||||
(δt′ |
, |
|||||||||||
|
|
|
|
|
||||||||
|
N − 1 |
|||||||||||
|
|
|
|
|
|
|
||||||
|
|
|
|
|
1 |
X ti′2 |
|
|||||
with t′2 = |
|
|||||||||||
|
|
|||||||||||
N |
|
|||||||||||
using the Monte Carlo relation τ(t′).
This approach has several advantages:

6.8 Method of Approximated Likelihood Estimator |
173 |
•We do not need to histogram the observations.
•Problems due to small event numbers for bins in a multivariate space are avoided.
•It is robust, simple and requires little computing time.
For these reasons the method is especially suited for online applications, provided that we find an e cient estimator.
If the distortions are not too large, we can use the likelihood estimator extracted from the observed sample {x′1, . . . , x′N } and the undistorted distribution f(x|λ):
Y
L(λ) = f(x′i|λ) ,
dL
d |ˆ = 0 . (6.29)
λ λ′
This means concretely that we perform the usual likelihood analysis where we ignore
the distortion. We obtain ˆ′. Then we correct the bias by a Monte Carlo simulation
λ
which provides the relation ˆ ˆ′ .
λ(λ )
It may happen in rare cases where the experimental resolution is very bad that f(x|λ) is undefined for some extremely distorted observations. This problem can be
cured by scaling ˆ′ or by eliminating particular observations.
λ
Acceptance losses α(x) alone without resolution e ects do not necessarily entail a reduction in the precision of our approach. For example, as has been shown in Sect. 6.5.2, cutting an exponential distribution at some maximum value of the variate, the mean value of the observations is still a su cient statistic. But there are cases where sizable acceptance losses have the consequence that our method deteriorates. In these cases we have to take the losses into account. We only sketch a suitable method. The acceptance corrected p.d.f. f′(x|λ) for the variate x is
f′(x λ) = |
R |
α(x)f(x|λ) |
, |
|
α(x)f(x|λ)dx |
||||
| |
|
where the denominator is the global acceptance and provides the correct normalization. We abbreviate it by A(λ). The log-likelihood of N observations is
XX
ln L(λ) = ln α(xi) + ln f(xi|λ) − NA(λ) .
The first term can be omitted. The acceptance A(λ) can be determined by a Monte Carlo simulation. Again a rough estimation is su cient, at most it reduces the precision but does not introduce a bias, since all approximations are automatically corrected with the transformation λ(λ′).
Frequently, the relation (6.29) can only be solved numerically, i.e. we find the maximum of the likelihood function in the usual manner. We are also allowed to approximate this relation such that an analytic solution is possible. The resulting error is compensated in the simulation.
Example 96. Approximated likelihood estimator: linear and quadratic distributions
A sample of events xi is distributed linearly inside the interval [−1, 1], i.e. the p.d.f. is f(x|b) = 0.5 + bx. The slope b , |b| < 1/2, is to be fitted. It is located in the vicinity of b0. We expand the likelihood function
174 |
6 Parameter Inference I |
|
|
|
|
|
ln L = X ln(0.5 + bxi) |
||||
|
at b0 with |
|
|
|
|
|
|
|
b = b0 + β |
|
|
|
and derive it with respect to |
|
|
|
ˆ |
|
β to find the value β at the maximum: |
||||
|
X |
|
x |
|
|
|
i |
= 0 . |
|||
|
0.5 + (b0 + βˆ)xi |
||||
|
|
|
|
|
ˆ |
|
Neglecting quadratic and higher order terms in β we can solve this equation |
||||
|
ˆ |
|
|
|
|
|
for β and obtain |
|
|
|
|
|
|
ˆ |
|
xi/f0i |
(6.30) |
|
|
β |
≈ Pxi2/f02i |
||
|
|
|
P |
|
|
where we have set f0i = f(xi|b0).
If we allow also for a quadratic term
f(x|a, b) = a + bx + (1.5 − 3a)x2 ,
we write, in obvious notation,
f(x|a, b) = f0 + α(1 − 3x2) + βx
and get, after deriving ln L with respect to α and β and linearizing, two linear
ˆ |
|
|
|
|
equations for αˆ and β: |
X |
|
X |
|
X |
|
|
||
2 |
ˆ |
|
= Ai , |
|
αˆ Ai |
+ β AiBi |
|
||
|
ˆ |
|
= X Bi , |
(6.31) |
αˆ X AiBi + β X Bi |
||||
|
|
2 |
|
|
with the abbreviations Ai = (1 − 3x2i )/f0i, Bi = xi/f0i.
From the observed data using (6.31) we get ˆ′ ′ , ′ ′ , and the simulation
β (x ) αˆ (x )
provides the parameter estimates ˆ ˆ′ ′ and their uncertainties. b(β ), aˆ(αˆ )
The calculation is much faster than a numerical minimum search and almost as
precise. If ˆ are large we have to iterate.
α,ˆ β
6.9 Nuisance Parameters
Frequently a p.d.f. f(x|θ, ν) contains several parameters from which only some, namely θ, are of interest, whereas the other parameters ν are unwanted, but influence the estimate of the former. Those are called nuisance parameters. A typical example is the following.
Example 97. Nuisance parameter: decay distribution with background
We want to infer the decay rate γ of a certain particle from the decay times ti of a sample of M events. Unfortunately, the sample contains an unknown amount of background. The decay rate γb of the background particles be known. The nuisance parameter is the number of background events N. For

176 |
6 |
Parameter Inference I |
|
|
|
|
|
|
|
|
3.0 |
|
|
|
|
|
|
|
2.5 |
|
|
|
|
|
rate |
2.0 |
|
|
|
|
|
|
|
|
|
|
|
||
|
decay |
1.5 |
|
|
lnL = 0.5 |
lnL = 2 |
|
|
|
|
|
|
|||
|
|
|
|
|
|
||
|
|
|
1.0 |
|
|
|
|
|
|
|
0.5 |
|
|
|
|
|
|
|
0.0 0 |
5 |
10 |
15 |
20 |
number of background events
Fig. 6.15. Log-likelihood contour as a function of decay rate and number of background events. For better visualization the discrete values of the event numbers are connected.
Let us resume the problem discussed in the introduction. We now assume that we have prior information on the amount of background: The background expectation had been determined in an independent experiment to be 10 with su cient precision to neglect its uncertainty. The actual number of background events follows a Poisson distribution. The likelihood function is
L(γ) = N=0 |
− N! |
i=1 1 − |
20 |
γe−γti + |
20 0.2e−0.2ti . |
||
∞ e |
1010N 20 |
N |
|
N |
|||
X |
|
Y |
|
|
|
|
|
Since our nuisance parameter is discrete we have replaced the integration in (6.32) by a sum.
6.9.2 Factorizing the Likelihood Function
Very easy is the elimination of the nuisance parameter if the p.d.f. is of the form
f(x|θ, ν) = fθ(x|θ)fν (x|ν) , |
(6.33) |
i.e. only the first term fθ depends on θ. Then we can write the likelihood as a product
L(θ, ν) = Lθ(θ)Lν (ν)
with |
Y |
|
Lθ = fθ(xi|θ) ,
independent of the nuisance parameter ν.
Example 99. Elimination of a nuisance parameter by factorization of a twodimensional normal distribution