

5.3. Лексемы
Лексемами (tokens) языканазываются “слова”, из которых состоит программа. Синтаксический анализатор разбивает исходный текст на отдельные лексемы и пытается понять, из каких операторов, идентификаторов и т.д. состоит программа. В языке Java символы-разделители (пробелы, табуляция, перевод строки и возврат курсора) применяются исключительно для разделения лексем или содержимого символьных или строковых литералов. Вы можете взять любую работающую программу и заменить произвольное количество символов-разделителей между лексемами (то есть разделителей, не входящих в строки и символы) на другое количество разделителей (не равное нулю)— это никак не повлияет на работу программы.
Разделители необходимы для отделения лексем друг от друга, которые бы в противном случае представляли бы собой одно целое. Например, в операторе
return 0;
нельзя убрать пробел между return и 0, поскольку это приведет к появлению неправильного оператора
return0;
состоящего всего из одного идентификатора return0. Дополнительные разделители облегчают чтение вашей программы, несмотря на то что синтаксический анализатор их игнорирует. Обратите внимание: комментарии считаются разделителями.
Алгоритм деления программы на лексемы функционирует по принципу “чем больше, тем лучше”: он отводит для следующей лексемы как можно больше символов, не заботясь о том, что при этом может произойти ошибка. Следовательно, раз ++ оказывается длиннее, чем +, выражение
j = i+++++i; // НЕВЕРНО
неверно интерпретируется как
j = i++ ++ +i; // НЕВЕРНО
вместо правильного
j = i++ + ++i;
5.4. Идентификаторы
Идентификаторы
Java, используемые для
именования объявленных в программе
величин (переменных и констант) и меток,
должны начинаться с буквы, символа
подчеркивания (_) или знака доллара ($),
за которыми следуют буквы или цифры в
произвольном порядке. Многим программистам
это покажется знакомым, но в связи с
тем, что исходные тексты Java-программ
пишутся в кодировке Unicode,
понятие “буква” или “цифра” оказывается
значительно более широким, чем в
большинстве языков программирования.
“Буквы” в Java могут
представлять собой символы из армянского,
корейского, грузинского, индийского и
практически любого алфавита, который
используется в наше время. Следовательно,
наряду с идентификатором kitty
можно пользоватьсяидентификаторами
maиka, кошка,
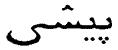 ,
,
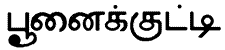 и
и
 .
/Эти слова означают "кошка" или
"котенок" на английском,
сербо-хорватском, русском, фарси,
тамильском и японском языках соответственно.
Если в других языках они имеют иное
значение, мы искренне надеемся, что оно
не является оскорбительным; в противном
случае приносим свои извинения и
заверяем, что оскорбление было
ненамеренным./ Термины “буква” и “цифра”
в Unicode трактуются довольно
широко, но если какой-либо символ
считается буквой или цифрой в неком
языке, то, по всей вероятности, он имеет
аналогичный смысл и в Java.
Полные определения этих понятий
приводятся в таблицах “Цифры Unicode”
и “Буквы и цифры Unicode”.
.
/Эти слова означают "кошка" или
"котенок" на английском,
сербо-хорватском, русском, фарси,
тамильском и японском языках соответственно.
Если в других языках они имеют иное
значение, мы искренне надеемся, что оно
не является оскорбительным; в противном
случае приносим свои извинения и
заверяем, что оскорбление было
ненамеренным./ Термины “буква” и “цифра”
в Unicode трактуются довольно
широко, но если какой-либо символ
считается буквой или цифрой в неком
языке, то, по всей вероятности, он имеет
аналогичный смысл и в Java.
Полные определения этих понятий
приводятся в таблицах “Цифры Unicode”
и “Буквы и цифры Unicode”.
Любые расхождения
в символах, входящих в состав
идентификаторов, делают два идентификатора
различными. Регистр символов имеет
значение: 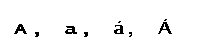 и
т.д. являются разными
идентификаторами. Символы, которые
выглядят одинаково или почти одинаково,
нетрудно спутать друг с другом. Например,
латинская заглавная n (N)
и греческая заглавная
и
т.д. являются разными
идентификаторами. Символы, которые
выглядят одинаково или почти одинаково,
нетрудно спутать друг с другом. Например,
латинская заглавная n (N)
и греческая заглавная 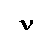 (N)
выглядят практически одинаково, однако
им соответствуют разные символы Unicode
(\u004e и \u039d
соответственно). Единственная возможность
избежать ошибокзаключается
в том, чтобы каждый идентификатор был
написан только на одном языке (и,
следовательно, включал символы известного
набора), чтобы программист мог понять,что
вы имеете в виду— E
или E. /Одна из этих букв
входит в кириллицу, а другая - в ASCII.
Отличите одну от другой, и вы получите
приз./
(N)
выглядят практически одинаково, однако
им соответствуют разные символы Unicode
(\u004e и \u039d
соответственно). Единственная возможность
избежать ошибокзаключается
в том, чтобы каждый идентификатор был
написан только на одном языке (и,
следовательно, включал символы известного
набора), чтобы программист мог понять,что
вы имеете в виду— E
или E. /Одна из этих букв
входит в кириллицу, а другая - в ASCII.
Отличите одну от другой, и вы получите
приз./
Идентификаторы в языке Java могут иметь произвольную длину.